我们做了一个通用机器人,它的实现形式是一个移动的操作臂,也就是机械臂,叫做mobile manipulator。下面这个是在我们办公室里面,机械臂自己导航到仓库,看盒子里面有什么东西,去判断盒子里东西的位置、姿态是什么样子的示例。
机器人从底座的移动到机械臂的移动,到如何实现对物品的识别,到抓取,到避开,都是完全自动的,没有任何的人工帮助。这本身也是两台机器人配合的一个过程。

先讲第一个感知的部分。感知就是
要描述你周围的世界,你周围的环境是什么样子的
。这是借用现在最火的自动驾驶的图,自动驾驶其中很重要的能力就是感知。

这张图显示的是recognition的部分,它可以识别一个图片里有什么东西,大概在哪个方位。这也是传统的CV里做的最多的一点。

这张是segmentation,就是把图片做一个分割,比如把人全部染成绿色,道路全部染成紫色,识别出来标志信号是黄色的。把画面里这些不同的功能加以区别,这样一来机器人就可以进行下一步的动作。
而我们目前集中力量做的,也是做真正有操作能力的机器人需要攻克的难点,是
pose estimation,也就是判断一个物品的姿态。
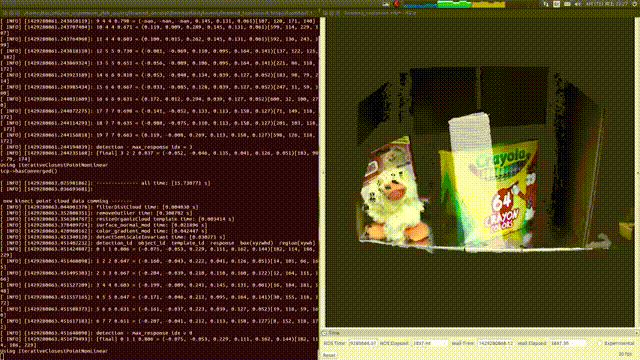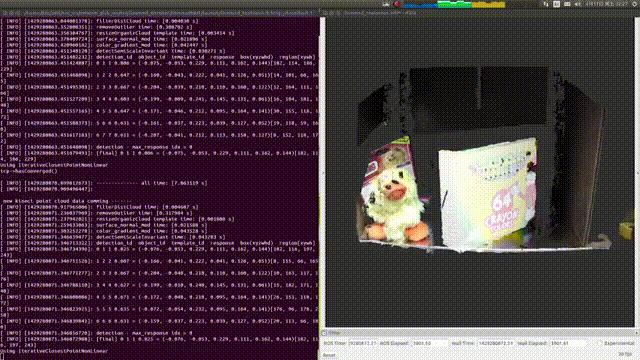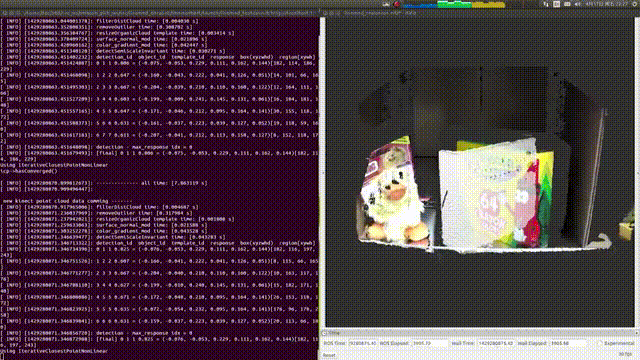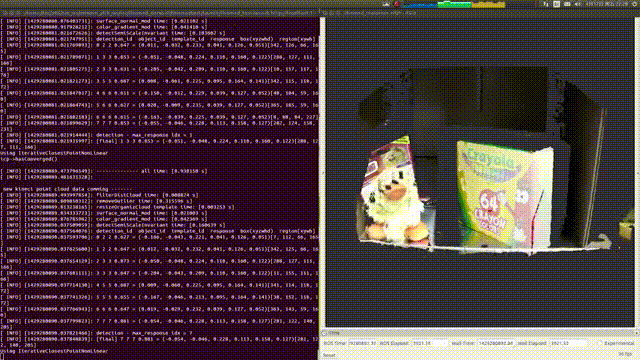
大家可以看到,右面图里有个白色的区域,这是系统识别零食盒的一个模板,当零食盒被转动之后,系统能够重新识别出它再画面里具体哪个位置,通过重新计算之后白色的区域又再次准确识别了零食盒的方位,更重要的是
它朝着什么方向
。
那么感知还有其他的方式,比如说
触觉
。

这是基于
电子
的触觉传感器的原理图。

这是基于
光学
的触觉传感器的一个原理图。

这个
触觉传感器





