正文
锤子新一代手机Big Bang功能的核心算法模块,Rokid机器人聊天系统,威马汽车车载前装的音乐和导航模块,此外,还有一些推进中的项目,其中包括3家巨头公司,4家手机,2家车载后装,和一些机器人公司,以及为消费者提供信息和提供服务的企业客户。
雷锋网:在您看来,目前语义理解技术主要用在哪些场景和应用里?
亓超:
语义技术是自然语言处理(NLP)方向很重要的一个部分,三角兽科技优势和积累也主要在NLP方向。
自然语言处理(NLP) 的研发有很久的历史,特别是在互联网发展起来后, 在很多场景里都有应用例如:
-
搜索引擎中的排序算法及广告推荐系统;
-
机器翻译, 输入法;
-
电商, 视频, 及新闻的个性化及推荐系统;
-
等等。
这些系统的背后都会涉及到NLP问题。
雷锋网:国内语义理解技术的现状是怎样的呢?
亓超:
国内NLP及相关的技术目前BAT,360等互联网大企业都有不错的积累。其他互联企业也有非常好的算法团队,例如今日头条等等。
很多产品线,例如百度度搜索,都会有各自的算法团队在支持, 其中NLP的算法支持占了比较大的比例,单从NLP基础技术本身,百度和MSRA的NLP团队无论从规模和深度上都有强大优势,国内的大学里哈工大在这个方向有强大的实力和积累,创业公司在这方面会面临人才稀缺的压力, 比较难形成一个很好的算法团队。
雷锋网:相比做语音识别的公司,提供语义理解的团队看似要少一些,其中的难点是
什么?
亓超:
两者在各自方向上都有各自的难点。
语音识别和合成相对语义理解来说, 技术上相对成熟。并且很早就作为相对独立的服务进行包装, 较为容易进行产品的落地。例如,地图服务的导航功能 包含了识别与合成两部分。另一方面从事语音技术的公司起步都比较早, 例如科大讯飞, 云知声, 思必驰等, NLP相关技术落地到具体产品也非常依赖于应用场景,相关团队多在大公司里作为某个产品线的算法团队来进行支持 。
虽然越来越受到关注, 但NLP及相关算法人才特别是有经验的从业者仍然非常稀缺, 促使从业者的收入水平较高, 人力成本占了比较大的比例。另外如果是ToC的商业模式, 那么运营成本也会占去较大比例。
雷锋网:理解中的语义理解公司往往需要大量标记好的语料数据,这些数据如何形成?
亓超:
-
1. 并不是所有NLP问题的解决都要依靠大量标注数据, 问题的解决方案也分统计方法的和规则方法的,这个好比要拧一个螺丝使用普通螺丝刀还是电动螺丝刀,电动螺丝刀需要电,普通的不需要;
-
2. 数据标注也并不一定是要纯靠人来进行操作, 很多结构化和半结构化的信息可以用来让机器进行学习, 例如电商的打分及评论数据可以用来进行观点分类的学习任务;
-
3. 未标注的语料很多时候的作用是很大的, 例如目前比较热门的DNN技术, 在很多场景下是使用未标注的数据进行数据及特征的表示学习。
雷锋网:就三角兽而言,我们目前有多少这样的数据?
亓超:
数据是我们的核心资源,数据抓取及建设会是我们长期的重点。以我们开放领域聊天系统依赖的数据举例:
-
百亿级的人人对话数据(未标注生语料);
-
亿级的面向不同任务的有标签或辅助信息的数据(未标注数据, 但可以进行数据处理后, 针对不同任;务可以用与进行机器学习任务);
-
千万级的有丰富标签精品数据(采用人机结合的方法进行标注, 形成精品语料);
-
已有并正在建设的百万级的标注数据(采用人机结合的方法进行标注, 形成精品语料, 每天新增数万条)。
雷锋网:
无论小冰还是度秘,都在最初注入了大量关联业务或者公开的数据(据说小冰是微博、度秘是贴吧),三角兽怎么解决冷启动的数据问题的?
亓超:
小冰及度秘使用的大部分数据都是互联网公开可见的数据(例如BBS或社区等人与人间的对话数据), 这些数据无论是大公司还是小公司都是可以公平获取的。三角兽成立之初便已开始在各大bbs和社区进行大量的数据的抓取及语料的清洗。
雷锋网:一个完整的聊天机器人或者多轮对话系统,应该包含哪些技术模块?
亓超:
聊天系统及对话系统是个庞杂的系统模块 有张技术分解图share给大家来参考。
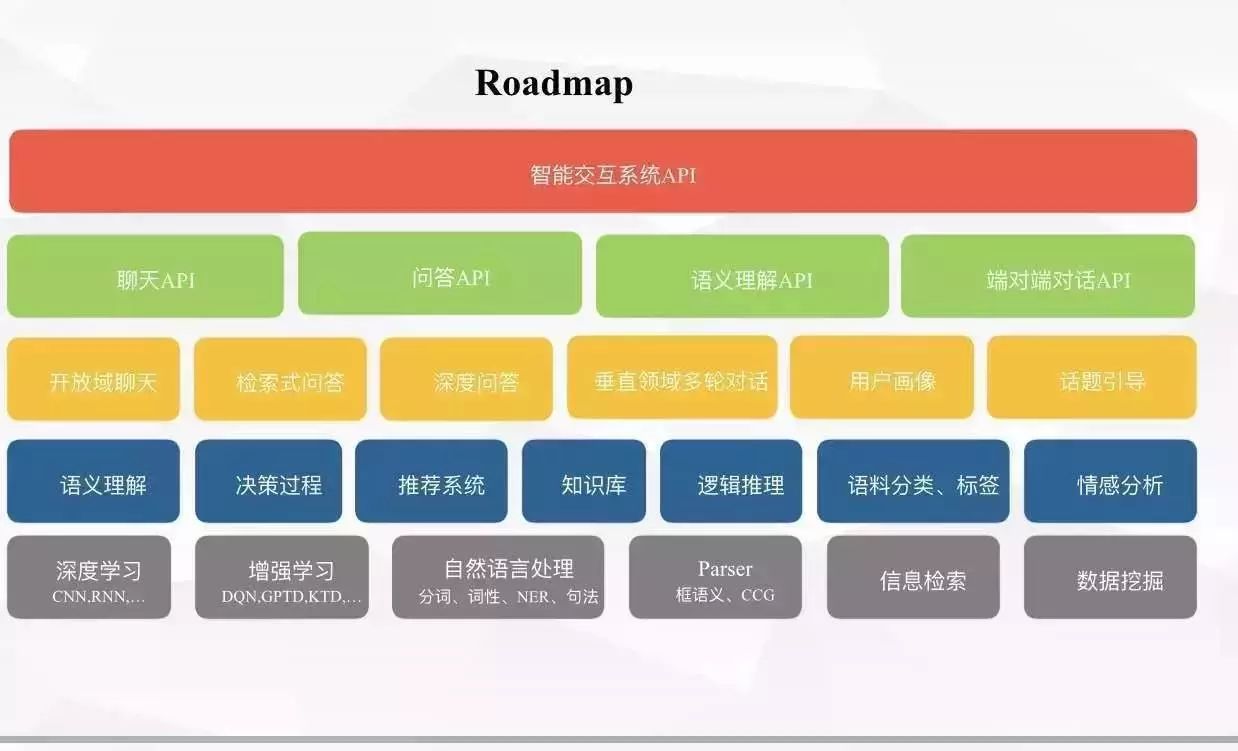
雷锋网:看到图片中对不同的模块进行了颜色区分,可以详细介绍下吗?
亓超:
最下面这一层是依赖的基础技术系列 上面蓝色这层是利用基础技术构造的基础技术模块,中间橙色是利用基础技术模块构造的子系统,上面两层是将子系统进行封装 对外提供打包服务 API 应用层。
雷锋网:多轮对话系统开发起来,与单轮对话系统的差异主要是哪些?
亓超:
其实严格来讲, 没有单纯的单轮对话系统 涉及对话系统一定是要考虑上下文的处理, 例如订票场景下,用户与机器之间需要进行多次的需求描述、澄清及确认过程来完成订票任务。单轮更偏向于信息获取的系统, 例如搜索引擎及问答系统。
雷锋网:您当时是小冰团队唯一负责核心算法的工程师,开创了开放域聊天系统。可以详细介绍下什么是开放域聊天技术吗?开放域聊天技术与传统用关键字、模板或者人工参与的聊天技术的不同之处是什么?
亓超:
开放领域聊天中的开放是指对用户不限定领域, 不会出现像Siri发布之初只能回复特定问题, 超出范围的返回搜索引擎结果, 另一方面聊天以一种模拟人类日常对话的方式进行自然的人机对话, 不同于一个冷冰冰的工具。
开放域聊天系统中也有关键词及模板的方法作为辅助,我们主打的两个技术方向是:
-
1. 检索式聊天系统: 基于几十亿量级人人对话, 使机器人进行人的聊天模式的模拟;
-
2. Sequence To Sequnence 端对端的 生成时聊天系统: 利用数据量的精品人人对话语料, 利用RNN等相关技术训练对话模型, 使机器具备对话的能力, 目前主要用于儿童聊天方向。
这两种方法的基础都是统计和机器学习, 关键词及模板的基础是NLP方向中常用的另一种方法规则系统。
无论是检索式还是生成式, 相对于纯规则的聊天系统来讲:










