正文
去噪自编码器(Denoising autoencoders,
DAE)是一种自编码器。在去噪自编码器中,我们不是输入原始数据,而是输入带噪声的数据(好比让图像更加的颗粒化)。但是我们用和之前一样的方法计算误差。所以网络的输出是和没有噪音的原始输入数据相比较的。这鼓励网络不仅仅学习细节,而且学习到更广的特征。因为特征可能随着噪音而不断变化,所以一般网络学习到的特征通常地错误的。
深度信念网络(Deep belief networks,
DBN)是受限玻尔兹曼机或者变分自编码器的堆叠结构。这些网络已经被证明是可有效训练的。其中,每个自编码器或者玻尔兹曼机只需要学习对之前的网络进行编码。这种技术也被称为贪婪训练。贪婪是指在下降的过程中只求解局部最优解,这个局部最优解可能并非全局最优解。深度信念网络能够通过对比散度(contrastive
divergence)或者反向传播来训练,并像常规的受限玻尔兹曼机或变分自编码器那样,学习将数据表示成概率模型。一旦模型通过无监督学习被训练或收敛到一个(更)稳定的状态,它可以被用作生成新数据。如果使用对比散度训练,它甚至可以对现有数据进行分类,因为神经元被教导寻找不同的特征。
卷积神经网络(Convolutional neural networks, CNN, or Deep convolutional neural
networks,
DCNN)和大多数其他网络完全不同。它们主要用于图像处理,但也可用于其他类型的输入,如音频。卷积神经网络的一个典型应用是:将图片输入网络,网络将对图片进行分类。例如,如果你输入一张猫的图片,它将输出“猫”;如果你输入一张狗的图片,它将输出“狗”。卷积神经网络倾向于使用一个输入“扫描仪”,而不是一次性解析所有的训练数据。举个例子,为了输入一张200
x 200像素的图片,你不需要使用一个有40000个结点的输入层。相反,你只要创建一个扫描层,这个输入层只有20 x 20个结点,你可以输入图片最开始的20 x
20像素(通常从图片的左上角开始)。一旦你传递了这20 x 20像素数据(可能使用它进行了训练),你又可以输入下一个20 x
20像素:将“扫描仪”向右移动一个像素。注意,不要移动超过20个像素(或者其他“扫描仪”宽度)。你不是将图像解剖为20 x
20的块,而是在一点点移动“扫描仪“。然后,这些输入数据前馈到卷积层而非普通层。卷积层的结点并不是全连接的。每个结点只和它邻近的节点(cell)相关联(多靠近取决于应用实现,但是通常不会超过几个)。这些卷积层随着网络的加深会逐渐收缩,通常卷积层数是输入的因子。(所以,如果输入是20,可能接下来的卷积层是10,再接下来是5)。2的幂是经常被使用的,因为它们能够被整除:32,16,8,4,2,1。除了卷积层,还有特征池化层。池化是一种过滤细节的方法:最常用的池化技术是最大池化(max
pooling)。比如,使用2 x
2像素,取这四个像素中数值最大的那个。为了将卷积神经网络应用到音频,逐段输入剪辑长度的输入音频波。卷积神经网络在真实世界的应用通常会在最后加入一个前馈神经网络(FFNN)以进一步处理数据,这允许了高度非线性特征映射。这些网络被称为DCNN,但是这些名字和缩写通常是可以交换使用的。
反卷积神经网络(Deconvolutional networks, DN),也叫做逆向图网络(inverse graphics networks,
IGN)。它是反向卷积神经网络。想象一下,将一个单词”猫“输入神经网络,并通过比较网络输出和真实猫的图片之间的差异来训练网络模型,最终产生一个看上去像猫的图片。反卷积神经网络可以像常规的卷积神经网络一样结合前馈神经网络使用,但是这可能涉及到新的名字缩写。它们可能是深度反卷积神经网络,但是你可能倾向于:当你在反卷积神经网络前面或者后面加上前馈神经网络,它们可能是新的网络结构而应该取新的名字。值得注意的事,在真实的应用中,你不可能直接把文本输入网络,而应该输入一个二分类向量。如,是猫,是狗,而是猫和狗。在卷积神经网络中有池化层,在这里通常被相似的反向操作替代,通常是有偏的插补或者外推(比如,如果池化层使用最大池化,当反向操作时,可以产生其他更低的新数据来填充)
深度卷积逆向图网络(Deep convolutional inverse graphics networks ,
DCIGN),这个名字具有一定的误导性,因为事实上它们是变分自编码器(VAE),只是在编码器和解码器中分别有卷积神经网络(CNN)和反卷积神经网络(DNN)。这些网络尝试在编码的过程中对“特征“进行概率建模,这样一来,你只要用猫和狗的独照,就能让网络学会生成一张猫和狗的合照。同样的,你可以输入一张猫的照片,如果猫的旁边有一只恼人的邻居家的狗,你可以让网络将狗去掉。实验显示,这些网络也可以用来学习对图像进行复杂转换,比如,改变3D物体的光源或者对物体进行旋转操作。这些网络通常用反向传播进行训练。

生成式对抗网络(Generative adversarial networks ,
GAN)是一种新的网络。网络是成对出现的:两个网络一起工作。生成式对抗网络可以由任何两个网络构成(尽管通常情况下是前馈神经网络和卷积神经网络配对),其中一个网络负责生成内容,另外一个负责对内容进行判别。判别网络同时接收训练数据和生成网络生成的数据。判别网络能够正确地预测数据源,然后被用作生成网络的误差部分。这形成了一种对抗:判别器在辨识真实数据和生成数据方面做得越来越好,而生成器努力地生成判别器难以辨识的数据。这种网络取得了比较好的效果,部分原因是:即使是很复杂的噪音模式最终也是可以预测的,但生成与输入数据相似的特征的内容更难辨别。生成式对抗网络很难训练,因为你不仅仅要训练两个网络(它们中的任意一个都有自己的问题),而且还要考虑两个网络的动态平衡。如果预测或者生成部分变得比另一个好,那么网络最终不会收敛。
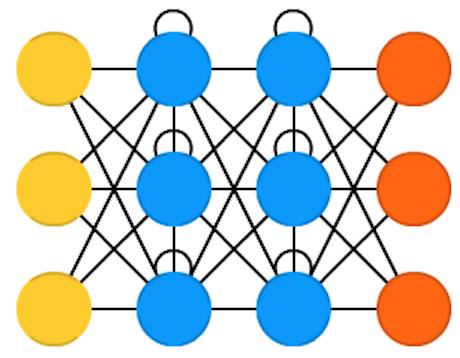
循环神经网络(Recurrent neural networks ,
RNN)是考虑时间的前馈神经网络:它们并不是无状态的;通道与通道之间通过时间存在这一定联系。神经元不仅接收来上一层神经网络的信息,还接收上一通道的信息。这就意味着你输入神经网络以及用来训练网络的数据的顺序很重要:输入”牛奶“、”饼干“和输入”饼干“、”牛奶“会产生不一样的结果。循环神经网络最大的问题是梯度消失(或者梯度爆炸),这取决于使用的激活函数。在这种情况下,随着时间信息会快速消失,正如随着前馈神经网络的深度增加,信息会丢失。直观上,这并不是一个大问题,因为它们只是权重而非神经元状态。但是随着时间,权重已经存储了过去的信息。如果权重达到了0或者1000000,先前的状态就变得没有信息价值了。卷积神经网络可以应用到很多领域,大部分形式的数据并没有真正的时间轴(不像声音、视频),但是可以表示为序列形式。对于一张图片或者是一段文本的字符串,可以在每个时间点一次输入一个像素或者一个字符。所以,依赖于时间的权重能够用于表示序列前一秒的信息,而不是几秒前的信息。通常,对于预测未来信息或者补全信息,循环神经网络是一个好的选择,比如自动补全功能。
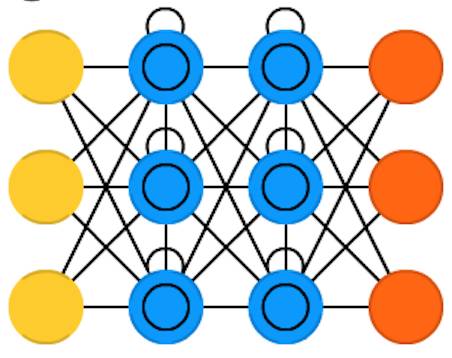
长短时记忆网络(Long / short term memory , LSTM)通过引入门结构(gate)和一个明确定义的记忆单元(memory
cell)来尝试克服梯度消失或者梯度爆炸的问题。这一思想大部分是从电路学中获得的启发,而不是从生物学。每个神经元有一个记忆单元和是三个门结构:输入、输出和忘记。这些门结构的功能是通过禁止或允许信息的流动来保护信息。输入门结构决定了有多少来自上一层的信息被存储当前记忆单元。输出门结构承担了另一端的工作,决定下一层可以了解到多少这一层的信息。忘记门结构初看很奇怪,但是有时候忘记是必要的:
如果网络正在学习一本书,并开始了新的章节,那么忘记前一章的一些人物角色是有必要的。
长短时记忆网络被证明能够学习复杂的序列,比如:像莎士比亚一样写作,或者合成简单的音乐。值得注意的是,这些门结构中的每一个都对前一个神经元中的记忆单元赋有权重,所以一般需要更多的资源来运行。
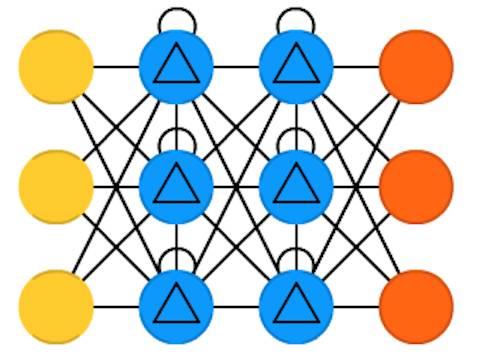
门控循环单元(Gated recurrent units ,
GRU)是长短时记忆网络的一种变体。不同之处在于,没有输入门、输出门、忘记门,它只有一个更新门。该更新门确定了从上一个状态保留多少信息以及有多少来自上一层的信息得以保留。
这个复位门的功能很像LSTM的忘记门,但它的位置略有不同。 它总是发出全部状态,但是没有输出门。
在大多数情况下,它们与LSTM的功能非常相似,最大的区别在于GRU稍快,运行容易(但表达能力更差)。
在实践中,这些往往会相互抵消,因为当你需要一个更大的网络来获得更强的表现力时,往往会抵消性能优势。在不需要额外表现力的情况下,GRU可能优于LSTM。
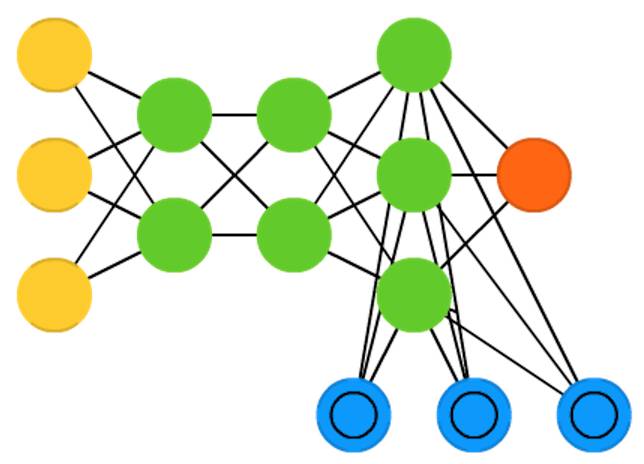
神经图灵机(Neural Turing machines ,
NTM)可以被理解为LSTM的抽象,它试图去黑箱化(使我们能够洞察到发生了什么)。神经图灵机并非直接编码记忆单元到神经元中,它的记忆单元是分离的。它试图将常规数字存储的效率和永久性以及神经网络的效率和表达力结合起来。这种想法基于有一个内容寻址的记忆库,神经网络可以从中读写。神经图灵机中的”图灵“(Turing)来自于图灵完备(Turing
complete):基于它所读取的内容读、写和改变状态的能力,这意味着它能表达一个通用图灵机可表达的一切事情。










