正文
静态延迟算完,我们来看带宽和动态延迟。
CCI和CPU/GPU之间是ACE口相连,数据宽度读写各128bit,16Byte。如果总线跑在800Mhz,单口的理论读或者写带宽分别是10.8GB/s。这个速度够吗?可以通过CPU端和总线端的Outstanding Transaction个数来判断。A73的手册上明确指出,ACE接口同时支持48个Cacheable的读请求,14x4(CPU核数量)设备和non-Cacheable的TLB/指令读,7x4+16写,这是固定的。而对应的CCI550的ACE接口支持OT数量是可配置的,配多大?有个简单公式可以计算。假设从CPU出来的传输全都是64字节的(Cacheable的一定是,而non-Cacheable的未必),而我们的带宽是10.8GB/s(假设是读),而一个传输从进入ACE到离开是51.3ns(按照上图计算),那么最大OT数是10.8x51.3/64=8.也就是说,只要8个OT就可以应付CPU那里100多个读的OT,多了也没用,因为总线数据传输率在那。从这点看,瓶颈在总线的频率。
那为什么不通过增加总线的数据位宽来移除这个瓶颈呢?主要是是位宽增加,总线的最大频率相应的会降低,这是物理特性。同时我们可能会想,真的有需要做到更高的带宽吗,CPU那里发的出来吗?我们可以计算一下。先看单个A73核,A73是个乱序CPU,它的读来自于三类方式,一个是读指令本身,一个是PLD指令,一个是一级缓存的预取。A73的一级缓存支持8路预取,每路预取范围+/-32,深度是4,预取请求会送到PLD单元一起执行,如下图。所以他们同时受到BIU上Cacheable Linefill数目的限制,也就是8.此外还有一个隐含的瓶颈,就是A73的LSU有12个槽,读写共享,所有的读写请求(包括读写指令,PLD和反馈过来的预取)都挂在这12个槽中独立维护。
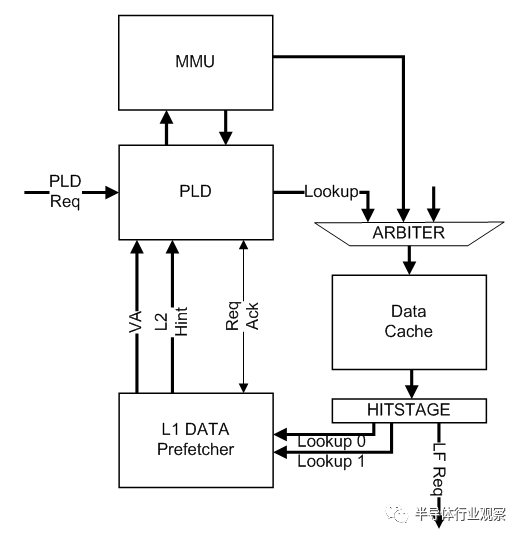
言归正传,假设系统里全是读请求,地址连续;此时A73每一条读指令的延迟是3个cycle(PLD可能只需要1个cycle,我不确定)跑在3Ghz的A73,一每秒可以发出1G次读,每个8字节(LDM)的话,就是8GB/s带宽,相当于每秒128M次Linefill请求,除以BIU的8个Linefill数量,也就是每个请求可以完成的时间是60ns这和我们看到的系统延迟接近。此时一级缓存预取也会起作用,所以8个Linefill肯定用满,瓶颈其实还是在在BIU的Linefill数量,按照50ns延迟算,差不多是10GB/s。假设都是写,指令一个周期可以完成,每cycle写8字节(STM),带宽24GB/s。如果写入的地址随机,会引起大量的Linefill,于是又回到BIU的Linefill瓶颈。地址连续的话,会触发Streaming模式,在BIU内部只有一个传输ID号,由于有竞争,肯定是按次序的,所以显然这里会成为写的瓶颈。由于写的确认来自于二级缓存,而不是DDR(是cacheable的数据,只是没分配一级缓存),延迟较小,假设是8个cycle,每秒可以往外写64B/8=8GB的数据。总的来说,A73核内部,瓶颈在BIU。
到了二级缓存这,预取可以有27次。当一级缓存的BIU发现自己到了4次的极限,它可以告诉二级缓存去抓取(Hint)。单个核的时候,4+27
A53是顺序执行的,读取数据支持miss-under-miss,没有A73上槽位的设计,就不具体分析了。
这里我简单计算下各个模块需要的带宽。
CPU簇x2,每个接口理论上总线接口共提供读写43.2GB/s带宽(我没有SPECINT2K时的带宽统计)。
G71MP8在跑Manhattan时每一帧需要370M带宽(读加写未压缩时),850Mhz可以跑到45帧,接近17GB/s,压缩后需要12GB/s。
4K显示模块需要4096x2160x4(Bytes)x60(帧)x4(图层)的输入,未压缩,共需要8GB/s的带宽,压缩后可能可以做到5GB/s。这还都是单向输入的,没有计算反馈给其他模块的。
视频需求带宽少些,解压后是2GB/s,加上解压过程当中对参考帧的访问,压缩后算2GB/s。
还有ISP的,拍摄视频时会大些,算2GB/s。
当然,以上这些模块不会全都同时运行,复杂的场景下,视频播放,GPU渲染,CPU跑驱动,显示模块也在工作,带宽需求可以达到20GB/s。
而在参考设计里,我们的内存控制器物理极限是3.2Gbpsx8Bytes=25.6GB/s,这还只是理论值,有些场景下系统设计不当,带宽利用率只有50%,那只能提供13GB/s的带宽了,显然不够。
而我们也不能无限制的增加内存控制器和内存通道,一个是内存颗粒成本高,还有一个原因是功耗会随之上升。光是内存控制和PHY,其功耗就可能超过1瓦。所以我们必须走提高带宽利用率的路线。
在这个前提下,我们需要分析下每个模块数据流的特征。
对于CPU,先要保证它的延迟,然后再是带宽。
对于GPU,需要保证它的带宽,然后再优化延迟,低延迟对性能跑分也是有提高的。
对于视频和ISP,带宽相对来说不大,我们要保证它的实时性,间接的需要保证带宽。
对于显示模块,它的实时性要求更高,相对于应用跑的慢,跳屏可能更让人难以容忍。
其余的模块可以相对放在靠后的位置考虑。
在CCI550上,每个端口的带宽是读写共21.6GB/s,大小核簇各需要一个端口,GPU每四个核也需要一个端口。显示和视频并没有放到CCI550,原因稍后解释。CCI550的结构如下:
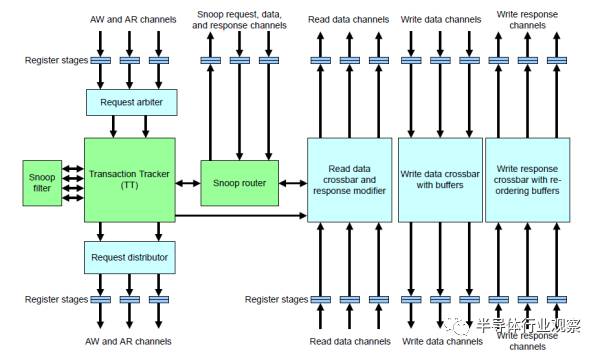
它一共可以有7个ACE/ACE-Lite进口,读写通道分开,地址共用,并且会进行竞争检查,每cycle可以仲裁2个地址请求。之前我们只计算了独立的读写通道带宽,那共用的地址会是瓶颈吗?算一下就知道。对于CPU和GPU,所有从端口出来的传输,无论是不是Cacheable的,都不超过64字节,也就是16x4的突发。一拍地址对应四拍数据,那就是可以同时有八个端口发起传输,或者4个通道同时发起读和写。假设在最差情况下,CPU+GPU同时发起shareable读请求,并且,读回去的数据全都引起了eviction,造成同等数量的写。此时数据通道上不冲突,地址通道也正好符合。如果是CPU+GPU同时发起shareable写请求,并且全都命中别人的缓存,引起invalidate,读通道此时空闲,但是invalidate占用地址,造成双倍地址请求,也符合上限。到DMC的地址不会成为瓶颈,因为共四个出口,每周期可以出4个。这里,我们使用的都是shareable传输,每次都会去Snoop Filter查找,每次可能需要两个对TAG RAM的访问(一次判断,一次更新标志位,比如Invalidate),那就是每cycle四次(地址x2)。而我们的Tagram用的是2cycle访问延迟的2块ram,也就是说,需要同时支持8个OT。这一点,CCI550已经做到了。在以上的计算中,DMC是假设为固定延迟,并且OT足够,不成为瓶颈。实际情况中不会这么理想,光是带宽就不可能满足。





