正文
说起爬虫,我们会首先使用
copy
命令抓网页源代码,但是当我们找到网页的源代码之后,通过检索相关信息,发现源代码中并没有我们需要的目标数据。

出现这样的结果,是因为这时我们找到的并不是网页的真实链接,要想继续寻找网页的真实链接,接下来我们需要谷歌浏览器的帮助。
在谷歌浏览器中,我们点击鼠标右键,会出现一个“
检查
”选项,单击“
检查
”,得到如下界面。
点击
network
,再按
F5
刷新,这样工具列表中就会出现许多与网页相关的链接,如下图所示:
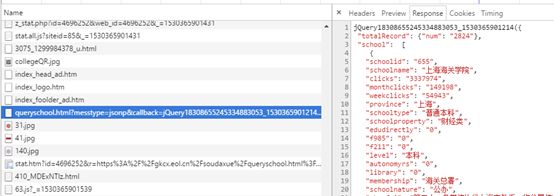
对于这个网页,我们在左侧找到我们需要的链接并单击,查看它的
Response
即返回信息,发现其返回信息和我们所分析的网页信息相同,如下图:
现在,我们就可以在
Headers
中找到网页的真实链接了(
RequestURL
)。如下图:

同时,我们可以发现,该网页的请求方式为
get
方式,网页的一些参数直接在网页的链接里边,找到网页的真实链接之后,我们当然又会想到我们的
copy
命令。所以我们继续使用
copy
抓网页源代码:
copy "https://data-gkcx.eol.cn/soudaxue/queryschool.html?messtype=jsonp&callback=jQuery1830992755553502749_1530151399470&province=&schooltype=&page=8&size=30&keyWord1=&schoolprop=&schoolflag=&schoolsort=&schoolid=&_=1530151399697" temp.txt, replace
我们发现stata报错了:

服务器拒绝了我们的访问!使用
copy
始终没有抓取到源代码,那么接下来,就轮到我们的爬虫神器——“
curl
”出场了!
要想得到这个网页的源代码,就需要我们使用curl模拟浏览器进行抓取。
curl的安装和使用案例在前面的推文中已经有所介绍(详见
《爬虫神器"curl"》
、
《一起来揪出网页真实链接!》
、
《爬虫神器curl继续带你抓网页》
),接下来我们来谈一谈curl在这次爬虫中的具体应用。
右击左侧我们需要的链接,单击
Copy as cURL
(
cmd
),然后复制到
do
文件或者
sublimetext
,就得到了下面一条命令: