正文
答案是不困难,但是这个模型不是干这个事的,这个模型就是为了让你灵活地存储收集数据,而数据链路是交由上层去做的,后面我会讲到怎么样施展魔法把这条链路拉出来。
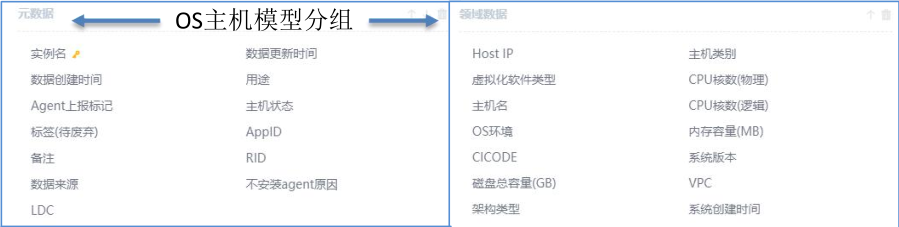
先看一下模型的分类情况。这是OS模型,为什么把它分成两部分,一部分是元数据模型,比如说元数据实例名,这边是有统一的CICODE,它是由CMDB直接管理的,而其他所有的数据都是「
领域」去管理的。
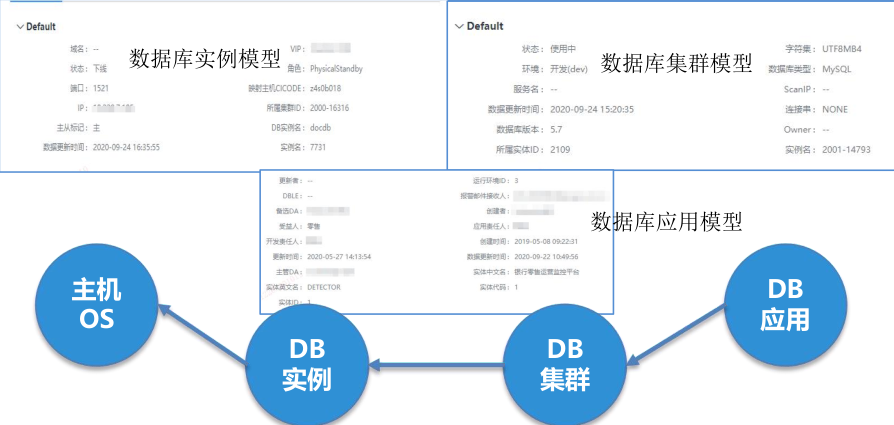
怎样理解「领域」?拿一个DB举例,这里有DB应用、DB集群实例关联到主机,这层模型关联关系从应用到集群到实例,三个模型是由DBA团队根据本地领域梳理出来的关系,哪个实例属于哪
个集群?这个集群又是被谁应用去使用?
因为银行里面的组织架构会很细,有DB、网络、存储,设备、机房、应用运维……应用运维又五花八门。这么多情况下,如果我作为工具开发方,
去推动铺垫这个链路的成本是很高的,并且所有的领域都必须严格按照我的要求去设计模型。
为了让领域能够更好的去做自己的关联关系,所以我们把这部分权利下放给了领域,领域把集群和实例关系接好之后,只要把实例CICODE指向到主机就可以了。
也就意味着DB整个关联关系
就是一个建制,那就是CICODE,它有它的生命周期,而我就负责管理这个CICODE生命周期。同样的应用和网络交换机等等都是如此,所有关联关系一串下来都关联主机,这三个集群关联关
系自己内部解决消化掉。
这些都是数据库模型字段,这些字段都是通过自动采集或者流程变更,你可以理解成在DBA团队里面有一个非常小型的CMDB,所有领域都是垂直的,只单向跟我沟通,领域和领域之间不会有
任何沟通。
怎么理解?DBA绝对不会去找网络交换机,不需要知道放在哪个柜子里面,也不需要知道放在哪个物理机上,我只要知道集群是提供给谁服务的,有哪些机器,这就是DBA要做得
事情。
这样就可以把每块领域拆的很干净,能带来的好处就是,当今天集群里面要加字段,或者关系,或者重新建它自己的关系,只需要把这部分全都推掉,DBA重新上报一次就结束了,所
有外部的集群关联关系什么都不用动。
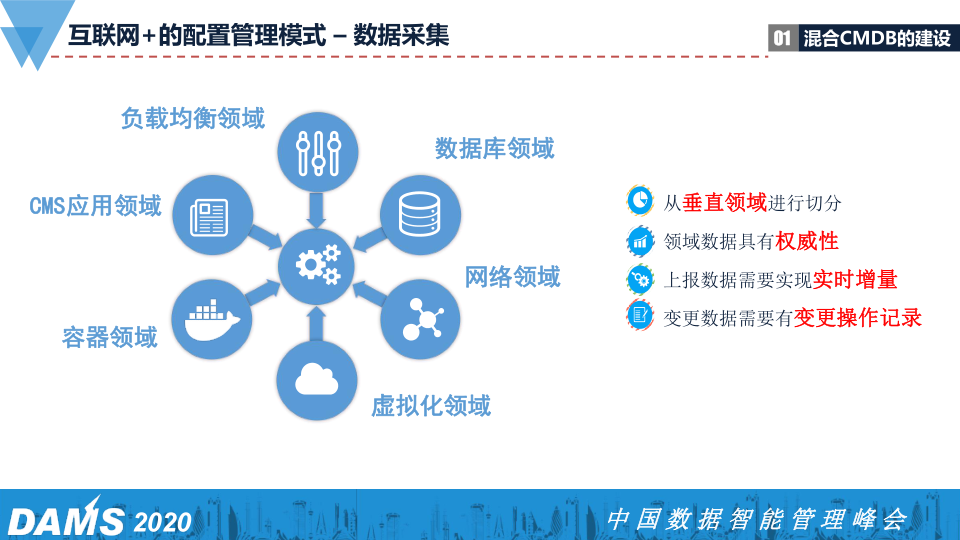
上图是「领域」,CMS是应用领域,它去负责每一个应用的属性。比如会给一个应用取一个ID号,这个ID号上面用了什么语言,跑了什么版本,用了什么中间件等等信息,还有它的管理属性
,功能、开发、运维等等都会在这个领域里面完成它的关系。
从垂直领域进行切分可以保证所有领域是不相干的,拆分完了之后可以去做自己想做的任何事情,这是具有权威性的,当上报的数据到我这里,我会相信它每次的上报。我们也会有更多的检
测机制,比如自动采集,会有一个组件自动采集所有网络设备,拿采集到的数据和领域报上来的数据去做比较,比较出来有问题的会退回到领域做相应的整改。
上报的数据是实时增量的。比如碰到厂商黑盒子的集群,有时候是通过API拿了所有数据回来,本身是不具备追溯性的。
今天前一分钟拿的一批地址里面有A,后一批拿的地址没有A了,那这
个A去了哪里呢?我们不知道,但是对银行来说是不允许这种情况发生的,需要所有生产变更都需要有被记录,那要求领域做到实时上报。
怎么做到实时上报?很简单,就是内部CMDB先和拿
上来的脚本做差异检查,把不需要的东西自己标记好再通过你上报。
这里又有一个问题了,我说这个状态改成A了,你就相信是A,我变成B你就相信是B,凭什么去相信结果?后面我们会跟变更事件串联起来,从后面的图里面会看到这个事情是怎么具有权威
性的。
变更数据需要有变更操作记录,这就是每个变更项目都会有变更记录。说到变更记录,我们银行虽然有4万台物理机,10万台虚拟机、网络交换机等等不算设备的情况下,我们的数据量其实
很轻,为什么会轻?
主要是在CMDB里面,就会想好做出来的数据到底有什么用处,不是所有数据都需要往CMDB里面扔,CMDB也不是一个“垃圾场”,CMDB其实是数据源头,它不是一个数据
仓库。
凡是进CMDB配置项,都要求有生产变更的才会进来。比如说今天的磁盘使用率或者变更比较频繁的东西不需要进到CMDB。因为这些东西变化太频繁,频繁的向CMDB灌输这些东西,而这些数
据产生不了任何价值的时候,我们就不会把它纳入进来。
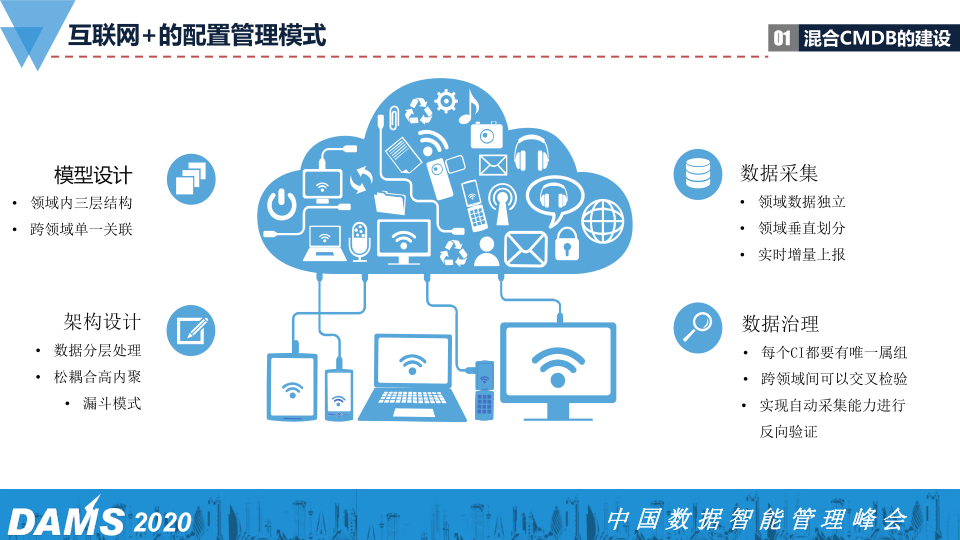
我们建CMDB的时候是会依照四个基本的原则去做。
1)模型设计
建模的时候每一个模型都是单一的模型,领域里面内均匀集群单一地向中间方靠拢。
2)架构设计
CMDB本身是分层治理。最底层的数据仓库与所有接入领域的数据上报,但是数据清洗和数据治理又是在上层一个一个构建出来的,是松耦合高内聚的模式。
3)数据采集
领域的数据是需要独立采集上来的,即使工具开发平台有这个能力自动采集,但是采集上来的不会作为CMDB原始数据来使用,而是作为领域上报数据的校验数据来做对比使用,为什么?
你
今天不是网络的同事,你不是CCIE或者你不是DBA,你没有办法知道里面比较细节的东西。在我们银行里边这个事情就被扩大了,虽然小公司可能一个人负责网络,同时兼DBA和运维是可能
的事情,但是在银行里面是做不到,那这种冲突就会无限放大,所以我会选择相信权威,他的专业知识比我厉害,那么领域上报的数据我是优先认可的。
4)数据治理
数据治理,治理其实是后事,在前期我们需要遵从几件事:
每一个配置项,每台都需要有一个CICODE,这台机器从生命周期一开始CICODE就跟着,一路跟到消亡,比如虚拟机被销毁,物理机直到报废。
跨领域之间需要沟通,什么是“跨领域之间”?
举个例子,虚拟化云团队领域会上报虚拟机和物理机的关系,会先把关系关联好,然后把CICODE告诉我,知道虚拟机CICODE映射到哪个物理
机上面,表示它的关联性。如果上报的一个CICODE没有在物理机里面,说明不是虚拟化有问题,就是物理机上报缺失了,这样就可以通过两个不同的领域知道数据里面的准确度有多少。





