正文
Kafka Stream 的整体架构图
如下。
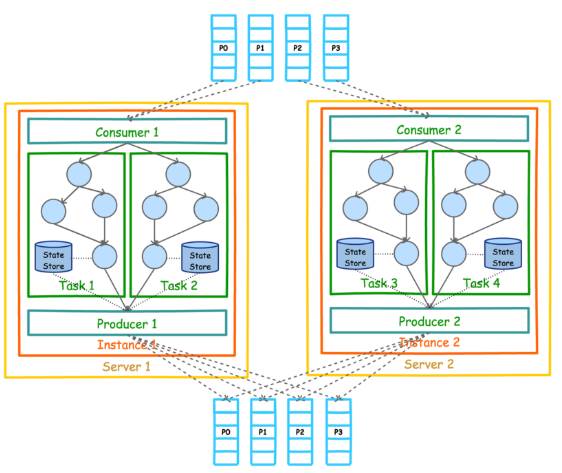
目前(Kafka 0.11.0.0)Kafka Stream 的数据源只能如上图所示是 Kafka。但是处理结果并不一定要如上图所示输出到 Kafka。实际上 KStream 和 Ktable 的实例化都需要指定 Topic。
KStream stream = builder.stream("words-stream");
KTable table = builder.table("words-table", "words-store");
另外,上图中的 Consumer 和 Producer 并不需要开发者在应用中显示实例化,而是由 Kafka Stream 根据参数隐式实例化和管理,从而降低了使用门槛。开发者只需要专注于开发核心业务逻辑,也即上图中 Task 内的部分。
基于 Kafka Stream 的流式应用的业务逻辑全部通过一个被称为 Processor Topology 的地方执行。它与 Storm 的 Topology 和 Spark 的 DAG 类似,都定义了数据在各个处理单元(在 Kafka Stream 中被称作 Processor)间的流动方式,或者说定义了数据的处理逻辑。
下面是一个 Processor 的示例,它实现了 Word Count 功能,并且每秒输出一次结果。
public class WordCountProcessor implements Processor {
private ProcessorContext context;
private KeyValueStore kvStore;
@SuppressWarnings("unchecked")
@Override
public void init(ProcessorContext context) {
this.context = context;
this.context.schedule(1000);
this.kvStore = (KeyValueStore) context.getStateStore("Counts");
}
@Override
public void process(String key, String value) {
Stream.of(value.toLowerCase().split(" ")).forEach((String word) -> {
Optional counts = Optional.ofNullable(kvStore.get(word));
int count = counts.map(wordcount -> wordcount + 1).orElse(1);
kvStore.put(word, count);
});
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator iterator = this.kvStore.all();
iterator.forEachRemaining(entry -> {
context.forward(entry.key, entry.value);
this.kvStore.delete(entry.key);
});
context.commit();
}
@Override
public void close() {
this.kvStore.close();
}
}
从上述代码中可见
-
process 定义了对每条记录的处理逻辑,也印证了 Kafka 可具有记录级的数据处理能力。
-
context.scheduler 定义了 punctuate 被执行的周期,从而提供了实现窗口操作的能力。
-
context.getStateStore 提供的状态存储为有状态计算(如窗口,聚合)提供了可能。
Kafka Stream 的并行模型中,最小粒度为 Task,而每个 Task 包含一个特定子 Topology 的所有 Processor。因此每个 Task 所执行的代码完全一样,唯一的不同在于所处理的数据集互补。这一点跟 Storm 的 Topology 完全不一样。Storm 的 Topology 的每一个 Task 只包含一个 Spout 或 Bolt 的实例。因此 Storm 的一个 Topology 内的不同 Task 之间需要通过网络通信传递数据,而 Kafka Stream 的 Task 包含了完整的子 Topology,所以 Task 之间不需要传递数据,也就不需要网络通信。这一点降低了系统复杂度,也提高了处理效率。
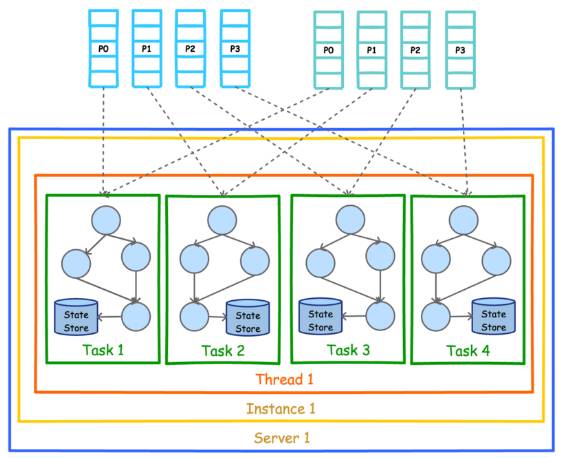
如果某个 Stream 的输入 Topic 有多个 (比如 2 个 Topic,1 个 Partition 数为 4,另一个 Partition 数为 3),则总的 Task 数等于 Partition 数最多的那个 Topic 的 Partition 数(max(4,3)=4)。这是因为 Kafka Stream 使用了 Consumer 的 Rebalance 机制,每个 Partition 对应一个 Task。
下图展示了在一个进程(Instance)中以 2 个 Topic(Partition 数均为 4)为数据源的 Kafka Stream 应用的并行模型。从图中可以看到,由于 Kafka Stream 应用的默认线程数为 1,所以 4 个 Task 全部在一个线程中运行。
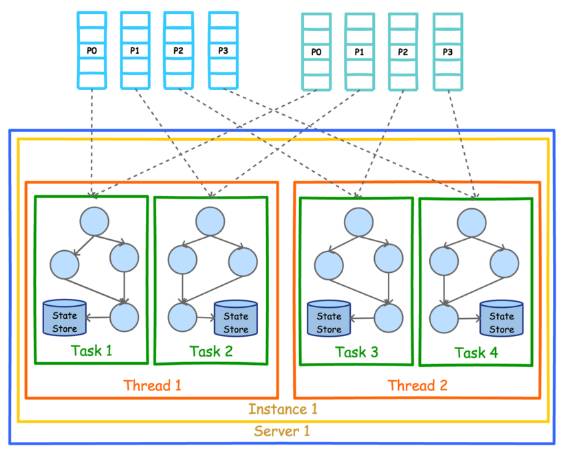
为了充分利用多线程的优势,可以设置 Kafka Stream 的线程数。下图展示了线程数为 2 时的并行模型。
前文有提到,Kafka Stream 可被嵌入任意 Java 应用(理论上基于 JVM 的应用都可以)中,下图展示了在同一台机器的不同进程中同时启动同一 Kafka Stream 应用时的并行模型。注意,这里要保证两个进程的 StreamsConfig.APPLICATION_ID_CONFIG 完全一样。因为 Kafka Stream 将 APPLICATION_ID_CONFI 作为隐式启动的 Consumer 的 Group ID。只有保证 APPLICATION_ID_CONFI 相同,才能保证这两个进程的 Consumer 属于同一个 Group,从而可以通过 Consumer Rebalance 机制拿到互补的数据集。
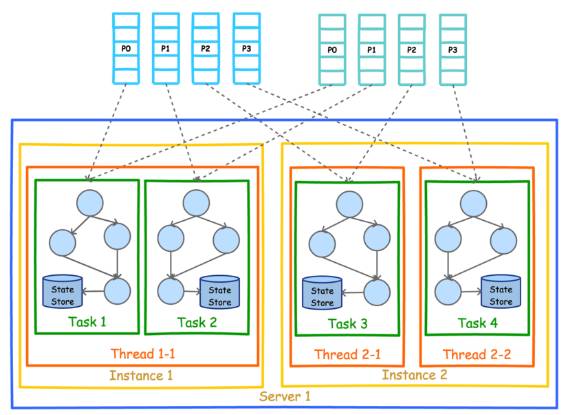
既然实现了多进程部署,可以以同样的方式实现多机器部署。该部署方式也要求所有进程的 APPLICATION_ID_CONFIG 完全一样。从图上也可以看到,每个实例中的线程数并不要求一样。但是无论如何部署,Task 总数总会保证一致。
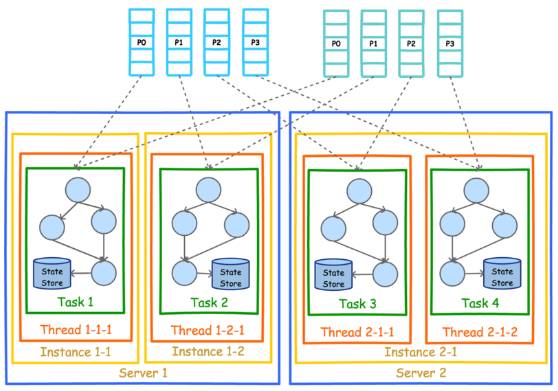
注意:Kafka Stream 的并行模型,非常依赖于《Kafka 设计解析(一)- Kafka 背景及架构介绍》一文中介绍的 Kafka 分区机制和《Kafka 设计解析(四)- Kafka Consumer 设计解析》中介绍的 Consumer 的 Rebalance 机制。强烈建议不太熟悉这两种机制的朋友,先行阅读这两篇文章。
这里对比一下 Kafka Stream 的 Processor Topology 与 Storm 的 Topology。





