正文
-
Inverted Index
-
Stored Fields
-
Document Values
-
Cache
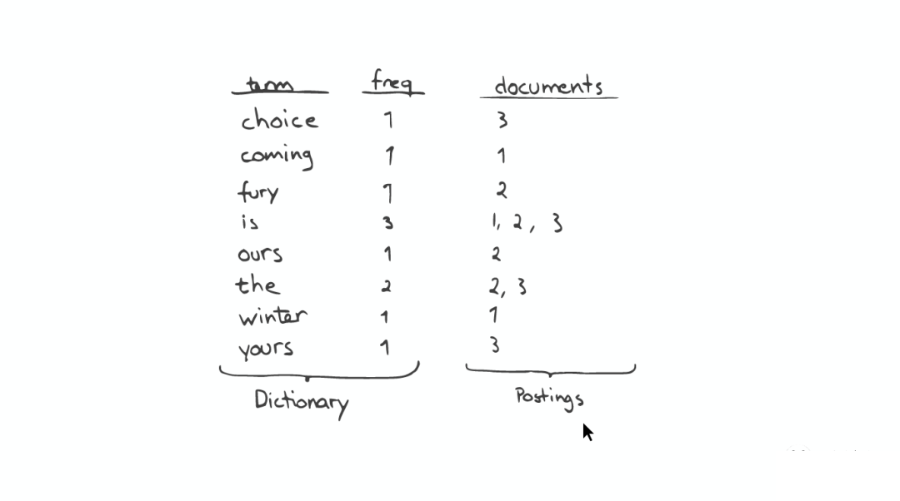
Inverted Index 主要包括两部分:
当我们搜索的时候,首先将搜索的内容分解,然后在字典里找到对应 Term,从而查找到与搜索相关的文件内容。

①查询“the fury”

②自动补全(AutoCompletion-Prefix)
如果想要查找以字母“c”开头的字母,可以简单的通过二分查找(Binary Search)在 Inverted Index 表中找到例如“choice”、“coming”这样的词(Term)。
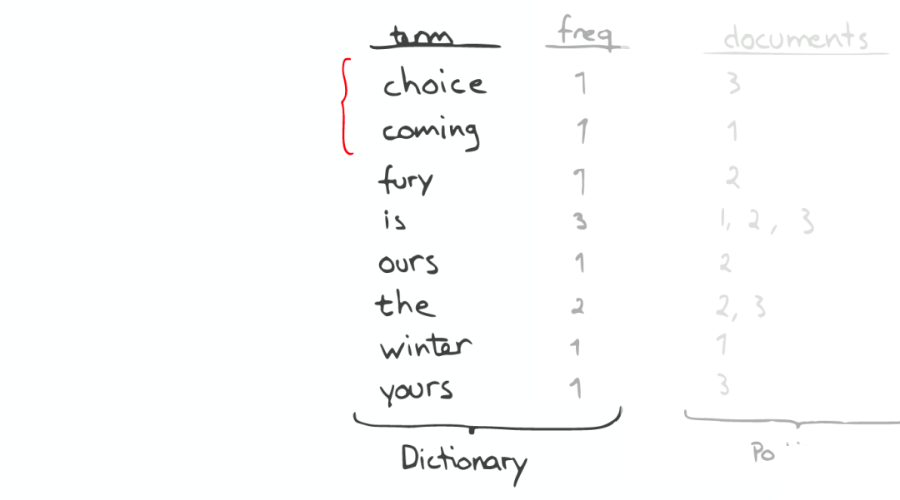
③昂贵的查找
如果想要查找所有包含“our”字母的单词,那么系统会扫描整个 Inverted Index,这是非常昂贵的。
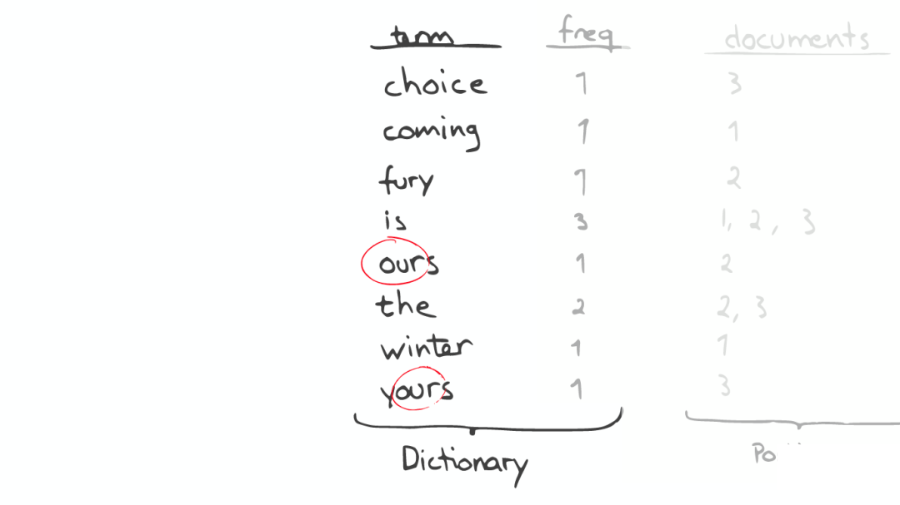
在此种情况下,如果想要做优化,那么我们面对的问题是如何生成合适的 Term。
④问题的转化

对于以上诸如此类的问题,我们可能会有几种可行的解决方案:
-
* suffix→xiffus *
,
如果我们想以后缀作为搜索条件,可以为 Term 做反向处理。
-
(60.6384, 6.5017)→ u4u8gyykk,对于 GEO 位置信息,可以将它转换为 GEO Hash。
-
123→{1-hundreds, 12-tens, 123},对于简单的数字,可以为它生成多重形式的 Term。
⑤解决拼写错误
一个 Python 库为单词生成了一个包含错误拼写信息的树形状态机,解决拼写错误的问题。
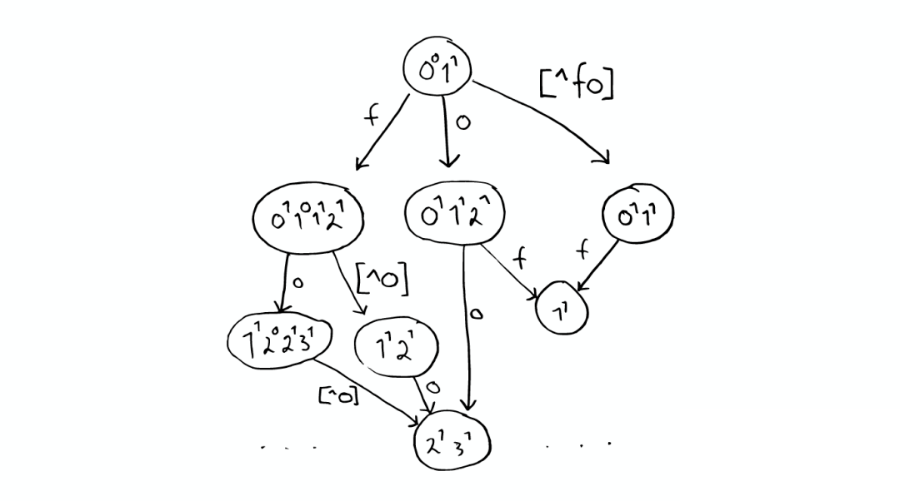
⑥Stored Field 字段查找
当我们想要查找包含某个特定标题内容的文件时,Inverted Index 就不能很好的解决这个问题,所以 Lucene 提供了另外一种数据结构 Stored Fields 来解决这个问题。
本质上,Stored Fields 是一个简单的键值对 key-value。默认情况下,ElasticSearch 会存储整个文件的 JSON source。

⑦Document Values 为了排序,聚合
即使这样,我们发现以上结构仍然无法解决诸如:排序、聚合、facet,因为我们可能会要读取大量不需要的信息。





