正文
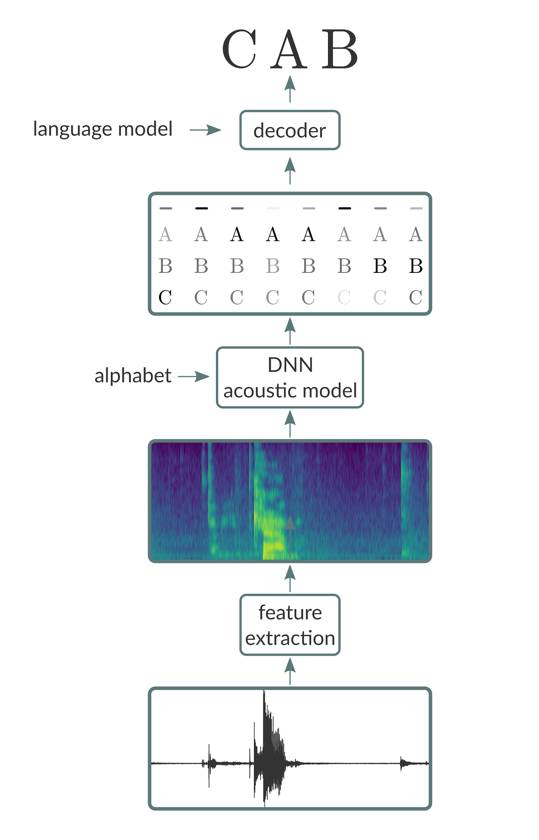
简单扼要的说,端到端语音识别流水线由三个主要部分组成:
1. 特征提取阶段,其将原始音频信号(例如,来自 wav 文件)作为输入,并产生特征向量序列,其中有一个给定音频输入帧的特征向量。特征提取级的输出的示例包括原始波形,频谱图和同样流行的梅尔频率倒频谱系数(mel-frequency cepstral coefficients,MFCCs)的切片。
2. 将特征向量序列作为输入并产生以特征向量输入为条件的字符或音素序列的概率的声学模型。
3. 采用两个输入(声学模型的输出以及语言模型)的解码器并且在受到语言模型中编码的语言规则约束的声学模型生成的序列的情况下搜索最可能的转录。
处理数据
当构建端到端语音识别系统时,一套有效的加载数据的机制是十分关键的。我们将充分利用 Neon 1.7 版本中新添加的功能:Aeon,一个能够支持图像,音频和视频数据的高级数据加载工具。使用 Aeon 大大简化了我们的工作,因为它允许我们直接使用原始音频文件训练声学模型,而不必困扰于对数据显示地预处理过程。此外,Aeon 能让我们更加容易的指定我们希望在训练期间使用的光谱特征的类型。
提取数据
通常,语音数据以一些标准音频格式的原始音频文件和一些包含相应转录的一系列文本文件的形式被分发。在许多情况下,转录文件将包含形如:,的行的形式。这表示所列出的路径指向包含转录的音频文件。但是,在许多情况下,转录文件中列出的路径不是绝对路径,而是相对于某些假定目录结构的路径。为了处理不同数据打包情况,Aeon 要求用户生成包含绝对路径对的「清单文件」(manifest file),其中一个路径指向音频文件,另一个路径指向相应的转录。我们将为读者介绍 Neon 的演讲示例(包括链接)和 Aeon 文档以获取更多详细信息。
除了清单文件,Aeon 还要求用户提供数据集中最长的话语的长度以及最长的转录的长度。这些长度可以在生成清单文件时被提取。比如可以使用当下流行的 SoX 程序去提取音频文件的时长。
我们通过训练由卷积(Conv)层,双向复现(bi-directional recurrent (BiRNN))层和完全连接(FC)层(基本上遵循「Deep Speech 2」,如示意图所示)组成的深层神经网络来建立我们的声学模型。
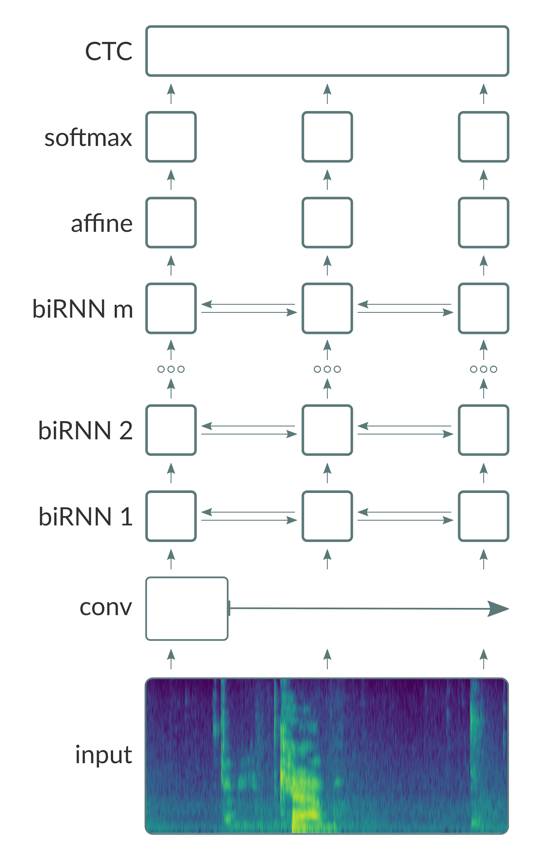
除了在输出层使用 softmax 激活函数,我们在其它层都采用 ReLU 激活函数。
如图所示,网络采用光谱特征向量作为输入。利用 Aeon dataloader,Neon 可以支持四种类型的输入特性:原始波形,频谱图,mel 频率谱系数(mel-frequency spectral coefficients (MFCSs))和 mel 频率倒频谱系数(mel-frequency cepstral coefficients (MFCCs))。MFSCs 和 MFCCs 是从频谱图中导出的,它们基本上将频谱图的每个列转换为相对较小数量的与人耳的感知频率范围更相近的独立系数。在我们的实验中,我们还观察到,在所有其他条件相等的情况下,用 mel 特征训练的模型作为输入执行效果略好于用频谱图训练的模型。
光谱输入被传送到了 Conv 层。通常,可以考虑具有采用 1D 或 2D 卷积的多个 Conv 层的架构。我们将利用可以允许网络在输入的「更广泛的上下文」(wider contexts)上操作的 strided convolution 层。Strided convolution 层还减少序列的总长度,这又显著减小了存储器的占用量和由网络执行的计算量。这允许我们训练甚至更深层次的模型,这种情况下我们不用增加太多的计算资源就可以让性能得到较大的改进。
Conv 层的输出被送到 BiRNN 层的栈中。每个 BiRNN 层由串联运行的一对 RNN 组成,输入序列在如图所示的相反方向上呈现。
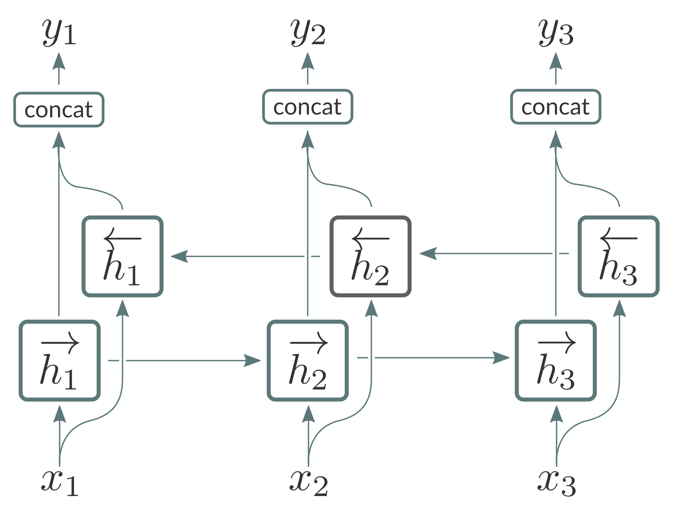
来自这对 RNN 的输出将被串接起来如图所示。BiRNN 层特别适合于处理语音信号,因为它们允许网络访问输入序列 [1] 的每个给定点处的将来和过去的上下文。当训练基于 CTC 的声学模型时,我们发现使用「vanilla」RNN 而不是其门控变体(GRU 或 LSTM)是有好处的。这主要是因为后者具有显着的计算开销。如 [2] 所讲,我们还对 BiRNN 层应用批次归一化(batch normalization),以减少整体训练时间,同时对总体字错误率(WER)测量的模型的精度几乎没有影响。









