主要观点总结
本文介绍了Pythoner志朋在知乎上的爬虫实验,包括使用的技术栈、数据成果、简单的可视化分析、爬虫架构、编码实现、如何获取authorization、可改进的地方等。文章还提及了ELK套件的安装和使用,以及爬虫在数据分析中的应用。
关键观点总结
关键观点1: 技术栈
使用了python27、requests、json、bs4、time等工具进行爬虫,使用ELK套件进行数据分析。
关键观点2: 数据成果
成功爬取了知乎部分用户数据信息,并进行了简单的可视化分析,如性别分布、粉丝最多的top30、写文章最多的top30等。
关键观点3: 爬虫架构
介绍了爬虫的架构图,包括选择活跃用户的url作为入口,抓取内容并解析,存储数据到本地磁盘,使用logstash、elasticsearch和kibana进行数据可视化。
关键观点4: 获取authorization的方法
介绍了如何通过chrome浏览器获取知乎的authorization,并解释了如何改进爬虫效率,如增加线程池、存储策略等。
关键观点5: 课程推广
文章最后推荐了马哥教育的Python自动化开发实战班,介绍了课程内容和咨询抢位方式。
正文
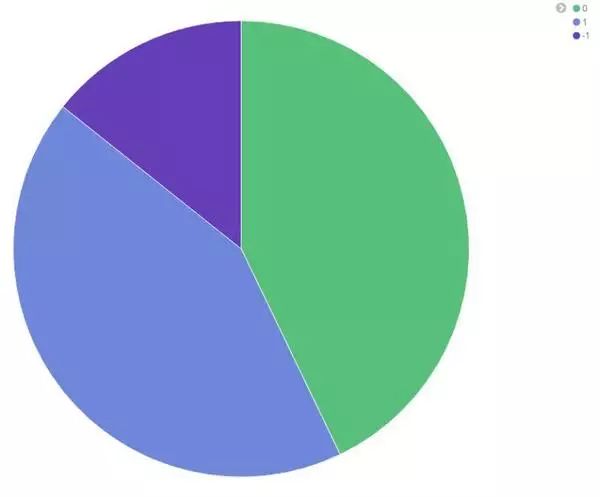
可见知乎的用户男性颇多。
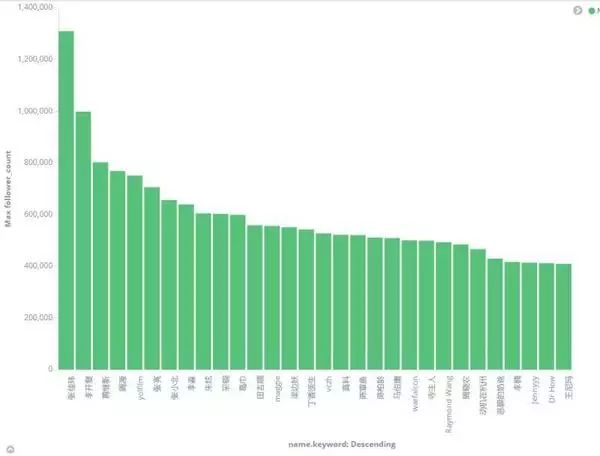
2.粉丝最多的top30
粉丝最多的前三十名:依次是张佳玮、李开复、黄继新等等,去知乎上查这些人,也差不多这个排名,说明爬取的数据具有一定的说服力。
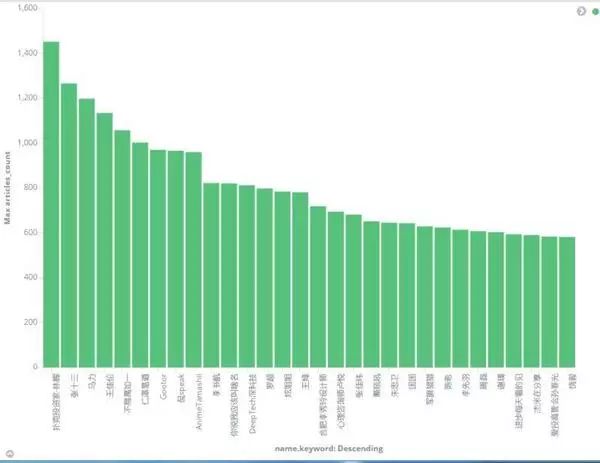
3.写文章最多的top30
四、爬虫架构
爬虫架构图如下:
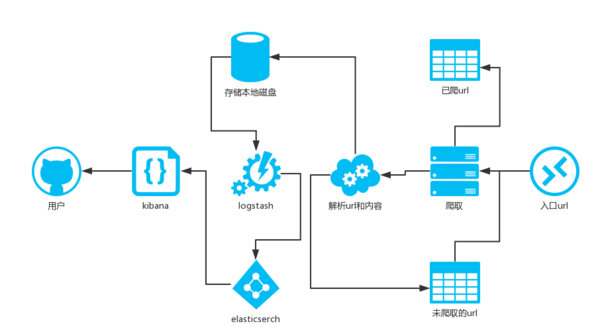
说明:
选择一个活跃的用户(比如李开复)的url作为入口url.并将已爬取的url存在set中。
抓取内容,并解析该用户的关注的用户的列表url,添加这些url到另一个set中,并用已爬取的url作为过滤。
解析该用户的个人信息,并存取到本地磁盘。
logstash取实时的获取本地磁盘的用户数据,并给elsticsearch





