正文
在向大宽表插入数据时,需要等待业务的数据都准备好后,才能跑关联表操作,然后将关联的结果插入到 ES。
经常遇到的情况是:
某个业务方的任务延迟,导致插入 ES 的关联任务无法执行,运营人员无法及时使用最新的画像数据。
在 ES 中修改文档结构是比较重的操作,修改或者删除标签比较耗时,ES 的多维聚合性能比较差,ES 的 DSL 语法对研发人员不太友好,所以我们将标签存储引擎从 ES 替换为 ClickHouse。
ClickHouse 是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。凭借优异的查询性能,受到业界的青睐,各个大厂纷纷跟进大规模使用它。
苏宁大数据已将 ClickHouse 引入并改造,封装成丰富的 Bitmap 接口,用来支撑标签平台的存储及分析。
我们在 ClickHouse 中集成了 RoaringBitmap,实现了 Bitmap 计算功能集,并贡献给开源社区。
对 userid 进行位图方式的压缩存储,将人群包的交并差计算交给高效率的位图函数,这样既省空间又可以提高查询速度。
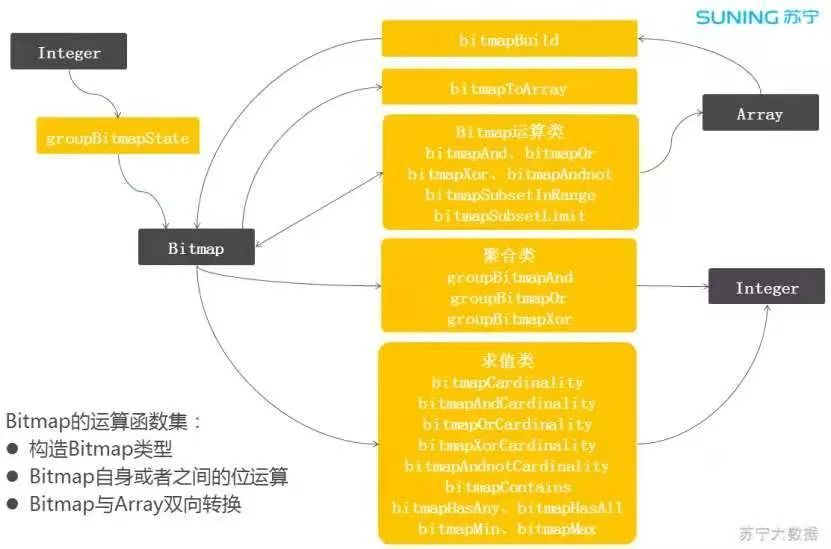
图 3:ClickHouse 集成 Bitmap
围绕 Bitmap 对象实现了一套完善的计算函数。Bitmap 对象有两种构建方式,一种是从聚合函数 groupBitmap 构建,另一种是从 Array 对象构建,也可以将 Bitmap 对象转换为 Array 对象。
ClickHouse 的 Array 类型有大量的函数集,这样可以更加方便的加工数据。
上图的中间部分是 Bitmap 的计算函数集,有位运算函数、聚合运算函数、求值类运算函数,比较丰富。
架构图如下:
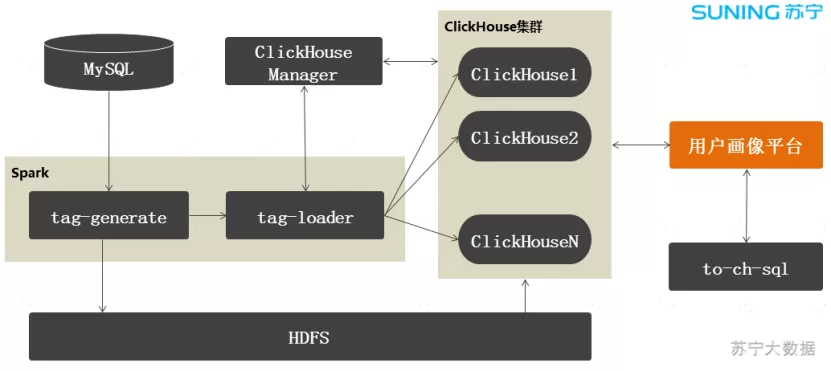
图 4:标签架构
ClickHouse Manager 是我们自研的 ClickHouse 管理平台,负责集群管理、元数据管理和节点负载协调。
Spark 任务负责标签数据的生成和导入,当某个业务方的任务跑完后,会立刻调用 tag-generate 生成标签数据文件,存放到 HDFS,然后在 ClickHouse 上执行从 HDFS 导入到 ClickHouse 的 SQL 语句,这样就完成了标签的生产工作。
标签生产是并发跑的,假设某个业务方的数据没有准备好,不影响其他业务的标签生产。
用户画像平台通过 Proxy 从 ClickHouse 集群查询标签数据。在查询前,需要将查询表达式转换为 SQL,我们对这块逻辑做了一个封装,提供一个通用的转换模块,叫做:to-ch-sql。
业务层基本上不用修改就可以查询 ClickHouse 了。
相对于 ElasticSearch 的存储结构,我们将标签存储做了一个行转列存储。每个标签对应一个 Bitmap 对象。
Bitmap 对象中存储 userid 集合:
CREATE TABLE ch_label_string
(
labelname String, --标签名称
labelvalue String, --标签值
uv AggregateFunction( groupBitmap, UInt64 ) --userid集合
)
ENGINE = AggregatingMergeTree()
PARTITION BY labelname
ORDER BY (labelname, labelvalue)
SETTINGS index_granularity = 128;
uv 字段为 Bitmap 类型的字段,将整形的 userid 存入,每个 userid 用一个 bit 位表示。
主键索引(index_granularity)默认为 8192,修改为 128 或者其他数值,由于 Bitmap 占用的存储空间比较大,修改为小数值,以减少稀疏索引的读放大问题。







