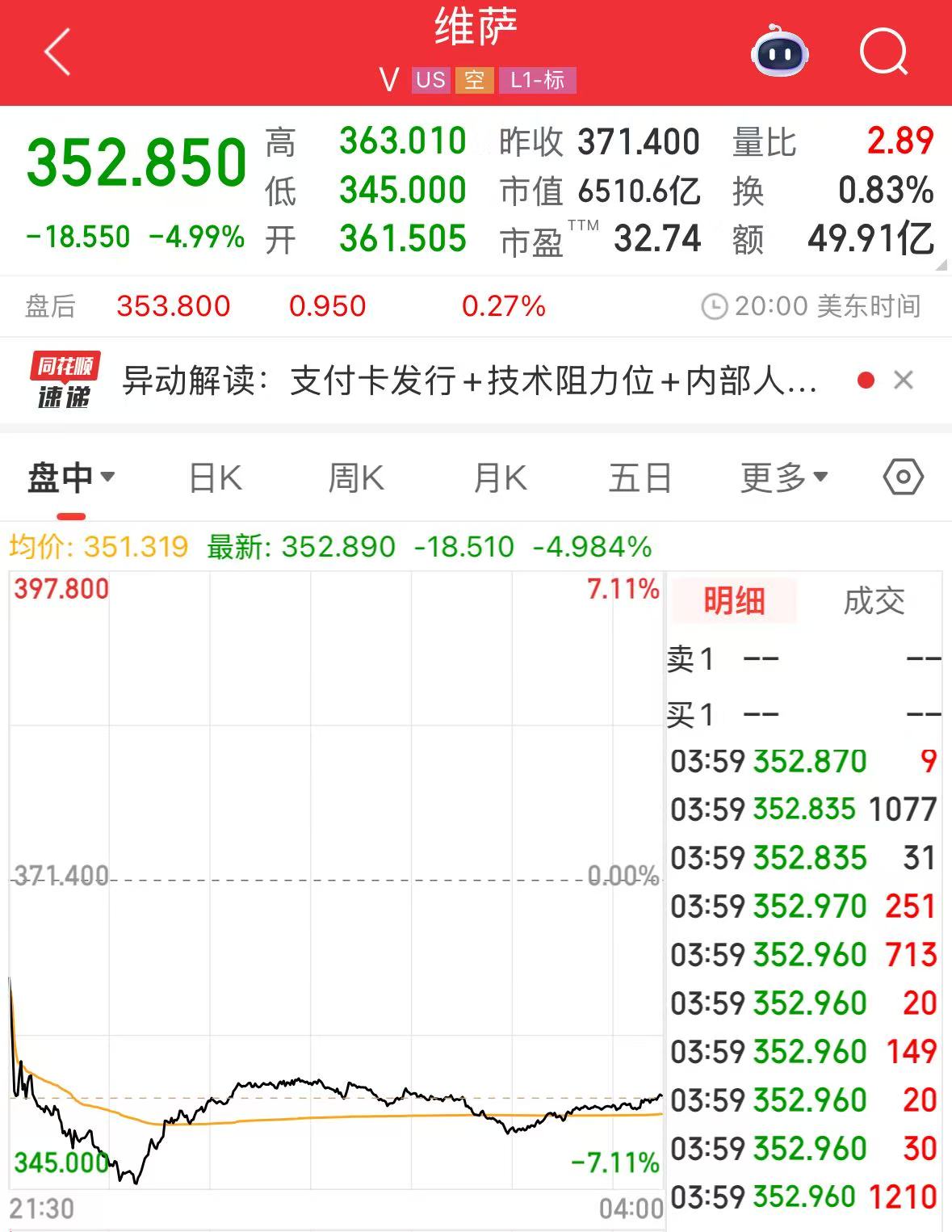
正文
The issue with Network Load Balancers should be resolved for all regions except us-central1, for which repairs are almost complete. We expect a full resolution in the next hour, and will provide another status update by 17:00 US/Pacific with current details.
Aug 30, 2017
14:35
The issue with Network Load Balancers should be resolved for all regions except us-central1, for which repairs are ongoing. We expect a full resolution in the next few hours, and will provide another status update by 16:00 US/Pacific with current details.
Aug 30, 2017
13:36
The issue with Network Load Balancers should be resolved for all regions are fixed except for us-central1, us-east1, and europe-west1. Those 3 are underway. We expect a full resolution in the next few hours. We will provide another status update by 16:00 US/Pacific with current details.
Aug 30, 2017
12:00
We have identified all possibly affected instances and are currently testing the fix for these instances. We will be deploying the fix once it has been verified. No additional action is required. Performing the workaround mentioned previously will not cause any adverse effects.
Next update at 14:00 US/Pacific
Aug 30, 2017
11:02
We wanted to send another update with better formatting. We will provide more another update on resolving effected instances by 12 PDT.
Affected customers can also mitigate their affected instances with the following procedure (which causes Network Load Balancer to be reprogrammed) using gcloud tool or via the Compute Engine API.
NB: No modification to the existing load balancer configurations is necessary, but a temporary TargetPool needs to be created.
Create a new TargetPool. Add the affected VMs in a region to the new TargetPool. Wait for the VMs to start working in their existing load balancer configuration. Delete the new TargetPool. DO NOT delete the existing load balancer config, including the old target pool. It is not necessary to create a new ForwardingRule.
Example:
1) gcloud compute target-pools create dummy-pool --project=
--region=
2) gcloud compute target-pools add-instances dummy-pool --instances=
--project=
--region=
--instances-zone=
3) (Wait)
4) gcloud compute target-pools delete dummy-pool --project=
--region=
Aug 30, 2017
10:30
Our first mitigation has completed at this point and no new instances should be effected. We are slowly going through an fixing affected customers. Affected customers can also mitigate their affected instances with the following procedure (which causes Network Load Balancer to be reprogrammed) using gcloud tool or via the Compute Engine API.
NB: No modification to the existing load balancer configurations is necessary, but a temporary TargetPool needs to be created.
Create a new TargetPool. Add the affected VMs in a region to the new TargetPool. Wait for the VMs to start working in their existing load balancer configuration. Delete the new TargetPool. DO NOT delete the existing load balancer config, including the old target pool. It is not necessary to create a new ForwardingRule.