正文
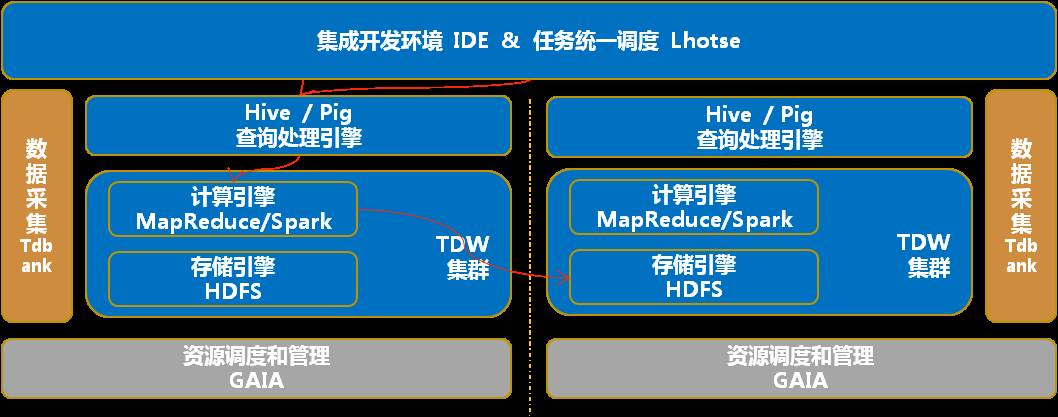
在说方案之前,我再深入介绍一下 TDW 里面的几个模块。我们只看左边就可以了。
左边从下面最底层是 GAIA,GAIA 负责资源调度。中间最左侧是数据采集 TDBank,它负责把各个业务线数据收集到 TDW。
TDW 的核心是计算引擎和存储引擎,存储引擎是放数据的地方,计算引擎提供 MapReduce 和 Spark 的计算能力。之上有查询引擎,最上面提供两个用户入口,任务统一调度和集成开发环境 IDE。
我举两个例子来说说各模块是怎么交互的。
案例一
,数据是怎么进入 TDW 的?
首先业务数据经过数据采集模块,落地到存储引擎的某个目录下;统一任务调度 Lhotse 配置的一个入库任务,与 Hive 交互,将目录的数据转换成 Hive 表的数据。
案例二
,数据是怎么计算的?
数据计算通过任务触发,任务是对数据的处理加工,比如统计日报的时候,计算任务对某个表做操作,把结果写回到另一个表中。
迁移是把存储和计算整套 TDW 平台,从一个城市搬迁到另外一个城市,双集群方案思路就很简单,在另外一个城市把所有系统都搭起来,跑起来就好了。
系统在两个城市之间是完全独立的,比如数据两份,计算两份,在这两个独立的系统之间不需要有任何的数据穿越(除了在迁移本身的数据穿越)。
这个方案最大优点就是不需要数据穿越,业务可以做到完全无影响,但是它最大缺点是需要大量的冗余设备。
方案二:
单集群方案
下面讲一下单集群方案,它跟双集群差异点在哪里?
最核心的差别在于:存储不会同时在两个地方,要么在左边,要么在右边。
(单集群方案)
单集群方案有一个最大的优点就是不需要大量的设备,慢慢地把一部分设备,一部分业务,从左边迁移到右边。
这里会面临一个问题,比如刚才说到的一个计算的场景,如果没有控制好的话,会出现计算在左侧,数据已经跑到右侧去了,因为数据只有一份。任务跑起来的时候,左侧的计算引擎就会大量拉取右侧的数据,会对专线造成很大的风险。
对比一下刚才那两个方案,我们可以总结一下思路:
在一个大的系统里,如果优先考虑成本,建议采用单集群方案。
单集群方案最大风险是跨城流量控制,跨城流量控制最重要的点是:
数据在哪里,计算就去哪里,要不然就是穿越;
如果访问的数据两边都有,哪边数据量大,计算就在哪边。
2.2 建立基于关系链的迁移模型
前面我们分析了一下我们实现跨城迁移的问题和方案,接下来我们为了解决跨城的流量控制降低跨城迁移的流量,我们引入一个基于关系链的迁移模型。
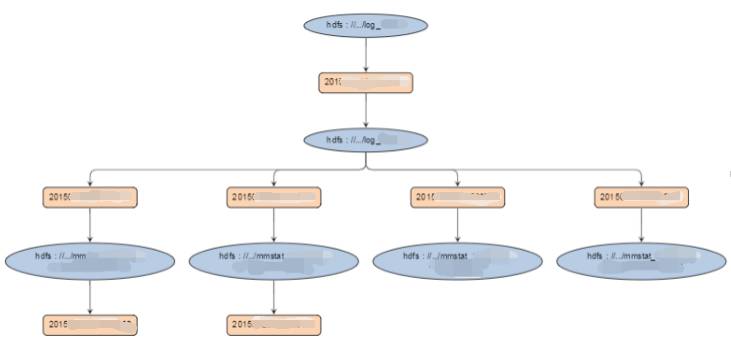
(一个关系链的例子)
我们需要知道数据流是怎么样来的,比如上面的一个关系链中,入库任务对最顶层的 HDFS 数据做一些加工处理,处理之后把结果保存到入库表;
分析人员基于这个入库表做各种计算和统计分析,比如统计某些指标,做关联性分析,这里配置了四个任务,这四个任务运行后产生新的结果表,其中还有两个结果表由下层的任务做进一步的处理,这样就产生了数据和任务的关系链。
引入关系链模型,它能帮助我们理清楚数据和任务的关系。
我们用椭圆描述数据,矩形描述对数据的加工,他们的连线表明访问数据的方向,是读还是写。这个关系可以用来指导我们的数据迁移,可以做到数据在哪里,计算就在哪里。
2.3 关系链的生成
接着的问题是在一个大的系统里关系链怎么生成?
在任务调度里面有一个概念,叫做依赖,用来描述任务的父子关系,父任务运行完成后子任务才允许运行。
原来我们没有做关系链的时候,这是纯粹的任务调度层的关系,虽然它有一定指导作用,但是不能直接应用在迁移里面,因为我们需要的是数据和任务的关系,而不仅是任务和任务的关系,我们需要从庞大的任务管理系统生成关系链,来指导数据迁移。
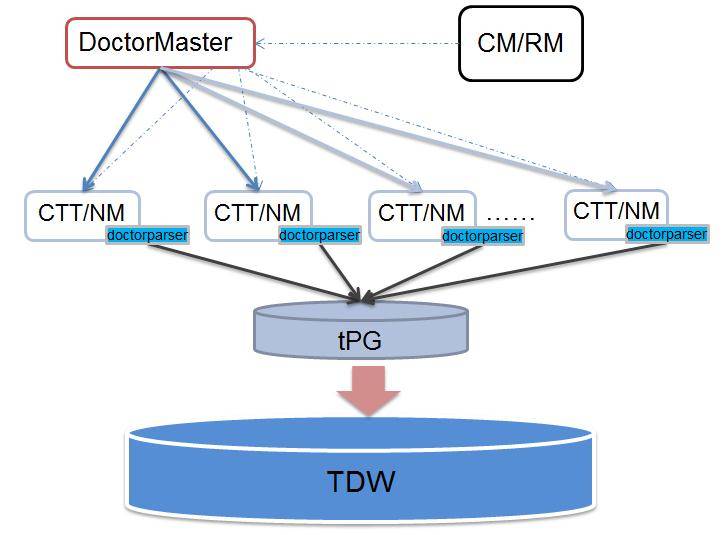
接下来介绍一个叫 hadoopdoctor 的运营工具,它是用做什么的?
它会把我们跑的任务信息采集回来,把它保存在 DB 里面,这些信息用于定位 MR 失败原因或性能分析。
它有一个主控模块,每五分钟去所有的 NodeManager 采集每个 MR 的配置和运行信息,比如说它的访问数据是什么,输出结果是什么。
为了支持迁移,我们改了一些逻辑,让 hadoopdocter 记录数据路径和任务ID,同时区分标识是读的还是写的。
把这个数据采集出来以后,我们就可以做关系链的分析。
(hadoopdoctor架构)
这里面采集到的路径会非常多,比如一个日报可能访问的是昨天某一个表的数据,比如访问量,就需要访问昨天的分区。采集出来的数据路径粒度非常细,它是包含日期的。
但是我们关注点并不需要到分区,我们关注的是表本身。所以我们把涉及到日期相关的路径规约掉,转成与日期无关的路径,数据规约对关系链分析有好处,归完之后减少了很多的数据量。
我们把最基础的信息采集到,它描述了一个任务,访问什么数据,产生什么数据。
经过我们的逻辑采集完之后,我们得到的是最原子的数据访问关系,就是一个任务对存储的操作,读或者是写,我们会产生非常多这样的原子关系,这种关系累计的结果就是关系链。
我们清洗出来一个最基础的关系,可以拼凑成一个大的关系链。
2.4 切分大关系链
关系链里面特别注意的地方,是一定要覆盖全面。





