正文
基于协同过滤召回
基于协同过滤的召回策略我们融合了user-based和item-based两种。
基于item-based的协同过滤,我们首先通过用户的购买行为计算item之间的相似度,比如通过计算发现item A和item B之间的相似度比较高,我们把item A作为候选推荐给购买item B的用户,作为item B的用户的召回候选集之一;同样也把item B作为候选推荐给购买item A的用户,作为购买item A的用户的召回候选集之一。因为item-based协同过滤的特征,这一部分召回基本能够把热门爆款单都拉到候选集中。
基于user-based的协同过滤,我们同样需要先计算用户之间的相似度。计算用户相似度时,除了考虑用户购买的商品,还可以把用户所消费过的商家及商家所在的商圈作为相似度权重考虑进来。这么做是因为,很多商品是在全国多个城市都可以购买的,如果只采用用户购买的商品来计算相似度,可能把两个不同城市用户的相似度计算的比较高,加入商家和商圈的权重,可以大大降低这种情况的可能性。
基于矩阵分解的场景化召回
对于O2O消费的某些场景,比如美食和外卖,用户是否发生购买与用户目前所处的场景有很大关系,这里的场景包含时间、地点、季节、天气等。举个例子来说,工作日的中午,如果还在下雨,这个时候外卖的购买概率一般是比其他商品高的。
基于此,我们开发了基于矩阵分解的场景化召回策略。我们采用了FM模型来进行建模,建模的特征包括季节、时间(工作日/周末,一天之内的时段)、地点、天气等。这个策略的目的是希望召回用户实时的基于场景化的需求。
上文提到在实时竞价阶段,AdServer会跟PredictorServer请求每个广告的站外点击率和点击价值。
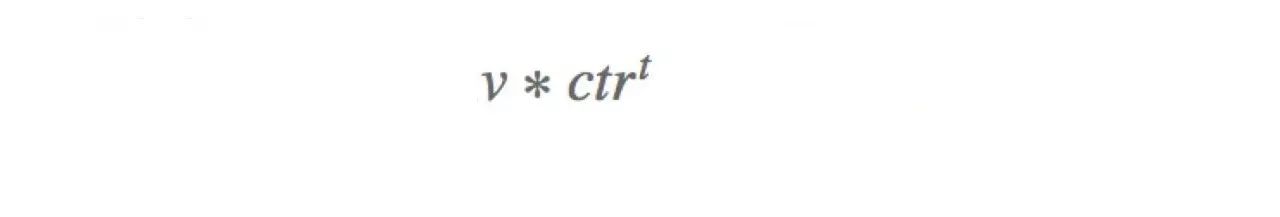
最后AdServer根据获取的点击价值
v
和
ctr
,根据上面的公式进行站外广告排序,挑选top的广告。最终的报价公式如下:
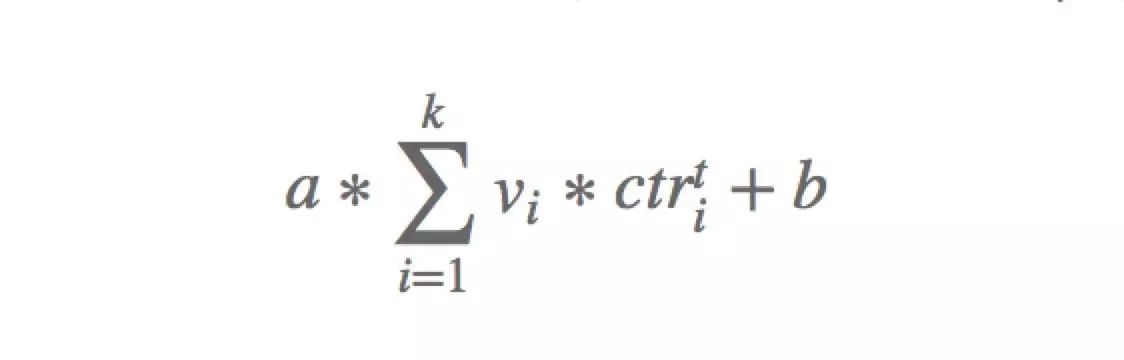
公式(1)
(1)
a
∗
∑
i
=
1
k
v
i
∗
c
t
r
i
t
+
b
" role="presentation">
k
是本次竞价要展示的广告数,
t
,
a
,
b
都是根据实际流量情况进行调整。其中
t
为挤压因子,为了控制
ctr
在排序和报价中起作用的比重,
t
越大,
ctr
在排序和报价中的比重越高;
a
,
b
需要根据DSP需要获取的流量和需要达到的ROI之间的权衡进行调整,
a
,
b
越大,出价越高,获取的流量越多,成本越高,ROI就减少。
公式1中CTR直接作为一个引子进行出价计算,所以这里的CTR必须是一个真实的点击率。因为在站外广告点击日志中,正样本是非常稀疏的,为了保证模型的准确度,我们一般都会采用负样本抽样。这样模型估计出来的CTR相对大小是没有问题的,可以作为排序依据,但是用来计算出价的时候,必须把负样本采样过程还原回去,我们在下面的小节中详细解释。
站外CTR预估
该模型目标是,对于RecServer召回的广告,预测出广告的相对点击率和真实点击率,相对点击率用于排序, 真实点击率用于流量报价。对于每个流量,AdExchange会下发给多个DSP,报价最高的DSP会胜出,获取在这个流量上展示广告的机会。为了能够引入更多的优质流量,减少流量成本,提高ROI、CTR预估模型需要充分考虑站点、广告、用户等维度的信息。
广告的点击与转化主要与用户、广告、媒体(user,ad,publisher)这三个因素相关。我们的特征也主要从这三个方向去构建,并衍生出一些特征
[5]
。
特征选择
1. 用户特征
用户浏览,购买的品类,用户画像,浏览器,操作系统等特征。
2. 广告特征
3. 媒体特征
网站类别,网站域名,广告位,尺寸等特征。
4. 匹配特征(主要是用户与广告维度的匹配)
5. 组合特征
在LR+人工特征的实现过程中,需要人工构造一些组合特征,比如,网站+广告、用户消费水平+价格、广告主+广告品类等,对于FM和FFM能都自动进行特征的组合。
6. 环境特征
广告的效果往往与用户所处的外部环境相关。比如 时段、工作日/节假日、移动端的经纬度等。
特征处理
最后再看我们具体如何构建模型。
1. 模型选择
由于站外的站点数量巨大、广告位较多、广告的品类较多,造成训练样本的特征数较大,需要选择合适的模型来处理,这里我们选用了LR+人工特征的方式,确保训练的性能。
2. 特征降维
点击率模型需要考虑用户维度的数据,由于美团的用户量巨大,如果直接用用户id作为特征会造成特征数急剧增大,而且one-hot encoding后的样本会非常稀疏,从而影响模型的性能和效果。所以我们这里采用了用户的行为和画像数据来表征一个用户,从而降低用户维度的大小。
3. 负样本选择
4. 负样本采样
由于广告点击的正负样本分布极其不均,站外广告的点击率普遍较低,绝大多数样本是负样本,为了保证模型对正样本的召回,需要对负样本按照一定比例抽样。
5. 真实CTR校准
由于负样本抽样后,会造成点击率偏高的假象,需要将预测值还原成真实的值。调整的公式如下:
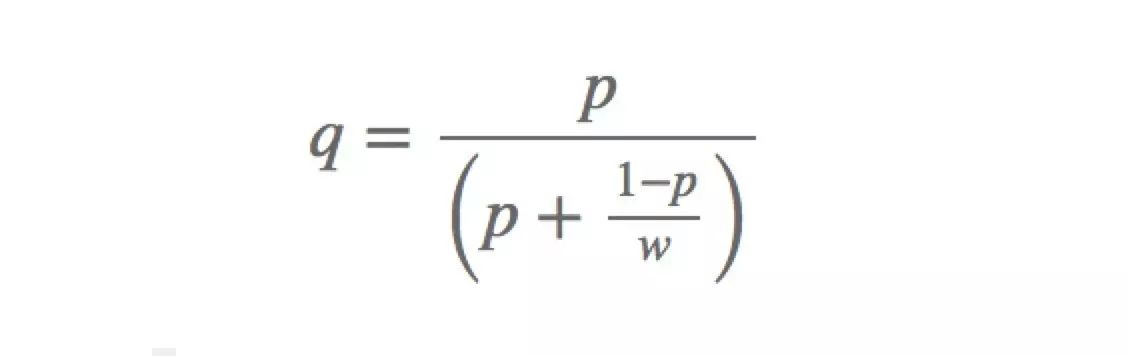
(2)
q
=
p
(
p
+
1
−
p
w
)
" role="presentation" style="line-height: normal; font-size: 13.92px; word-spacing: normal; word-wrap: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; text-align: center; display: table-cell !important; width: 10000em !important;">
公式(2)




