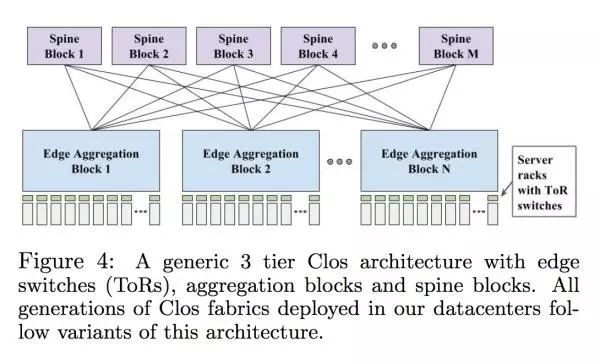
正文
如果这些机器是一个储存服务,那么这个我们需要确保储存的数据不能在一个 rack/集群上面,不然会出现 correlated failure。但是如果要分散数据的话,就会需要用跟多的 CR 层面的网络,所以储存类服务需要常常跟其他的 rack 去沟通。
这个设计在当时是符合 Google 的内部需求的,但是总体的速度和价格还是不尽人意。每个 host 网络最多能用 100Mbps,丢包率也是很高(没说具体多高)。如果要增加带宽那么价格就会增加。这个时候他们了解到了现有的网络设计是没有办法继续扩张的,所以 Google 开始往 Clos topologies 上面移:
Google 当时遇到的最大的问题有下面几个
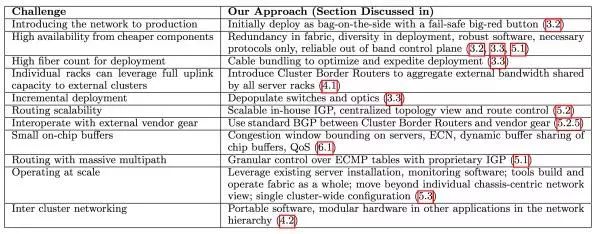
这个到后面我们会一个一个来解答。Paper 里面还提到了市面上还有几个可替换的解决方案比如 HyperX, Dcell,BCube 和 Jellyfish,这个大家有兴趣的话可以去看看这个 paper 的 reference。
Google 内部网络设计的进化史
下图是 Google 每个世代的网络架构的参数:
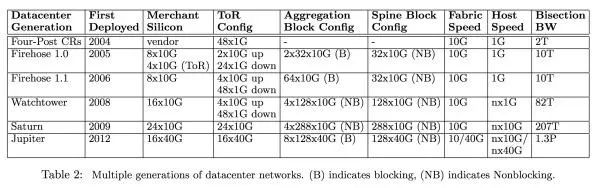
Firehose 1.0 一开始设计的时候主要就是为了能够支持在一个 10k 机器的集群里面,每个 host 有 1Gbps 的 nonblocking bisection bandwidth(看最右一栏 Bisection BW 从 2T 变成了 10T)。这个时代的最大的问题在于 ToR Switch 的基数比较低,每一对 ToR 之间的 link 断了之后这两个 rack 之间是不能沟通的,虽然能跟其他 rack 沟通。下图是 Firehose 1.0 的具体设计
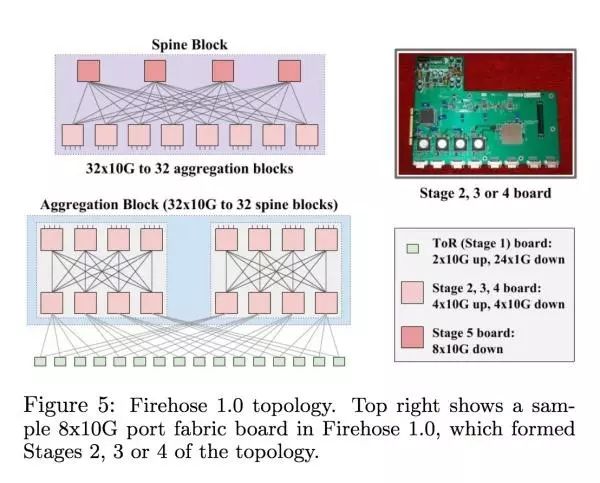
Google 当时在服务器设计端比较有经验,所以试过把 switching 的硬件通过 PCI-E 插到服务器上面。但是服务器常常挂掉/要被换,如果是负责 routing 的服务器挂掉的话整个 rack 都断网;由于这些缺陷 Firehose 1.0 从来没有进到 production。
Firehose 1.1: First Production Clos
1.1 跟 1.0 差别在于,swtiching 的逻辑不再是基于某一个服务器的了,而被放到了分开的一个盒子里面。用来控制这些网卡的网络是完全跟服务器的网络分离的。1.1 也为了确保整体每个 rack 的网络 over subscription 不超过两倍,每两个 ToR 被绑在了一起。每个 ToR 有 4
10G 跟 48
1G 的 link,这里面两条 10G 的 link 是连在 fabric 上面的,另外两条 link 连到了被绑定的 ToR 上面,每次每个机器的网络可以四条都用。Stage 2/3 的 swtich 是全部都连在一起的,而不是分开的两个 block。下图是 1.1 具体的设置

对于这个设计来说,连网线也是一大挑战,Google 当时的线主要是 14 米长,所以连的时候要事先计划好,所以还特地设计了 100 米的光纤让连线变得更容易。
Watchtower: Global Deployment
Firehose 1.1 的反响不错,但是当时没有把所有的集群都移到 firehose 上面。接下来继续在 Google 内部推的网络叫 Watchtower,主要差别在于解决之前连线的麻烦跟启用新一代 16*10G 的 switch 芯片。新一代的 chasis 跟内部设计长这样











