正文
易于访问的外围
认证和授权
标准化的 RPC
Martin 说:
你应该具备在几个小时内搭建一个新服务器的能力。在云计算平台上,这是很基本的行为,不过它也不一定非要借助云服务。你可以通过自动化来实现快速配置——刚开始可以不用完全自动化,但在进入微服务架构之后需要实现完全的自动化。
Martin 在他的话里使用了服务器这个词,但在现今的 IT 环境,既可以使用真实的服务器,也可以使用虚拟机、容器、函数,或这些组件的组合。这也是为什么我使用了“计算资源”这个词,它是指任何可以为你提供 CPU 和内存来运行代码的资源。
十多年前,我们需要将应用程序部署到应用服务器上。这个层多路复用了单独的计算单元,多个应用程序或服务可以同时运行在服务器上面,而且这种部署架构沿用了多年。那个时候,每秒钟处理几百个请求就可以称得上是“互联网规模”了。企业可以最大化对硬件的使用,多个不同的服务可以运行在同一个硬件上,有时候甚至多个公司共享一个应用服务器,在上面运行多租户服务。
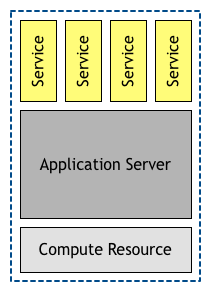
随着硬件的发展,计算资源成本在下降,本地数据中心和云端都可以提供这些计算资源。这样,对应用服务器的需求就被弱化了。尽管应用服务器为应用程序提供了拆箱即用的服务(比如安全、服务发现、管理面板等),但这些服务器太过笨重了。另外,随着流量的增长,我们从垂直伸缩转向了水平伸缩,而这些服务器在这方面并未能提供很好的支持。
基于上述的各种原因,我们才有了现今的部署架构,服务实例和计算资源之间是一对一的关系。
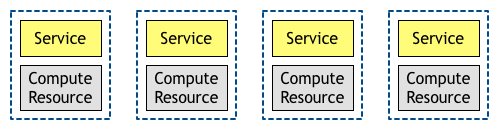
这种一对一的关系直接影响到了微服务架构。尽管针对微服务还没有最终的定义,不过当人们提及微服务时,他们一定是指很多小型的服务。按照上面的这种部署架构,我们就会有很多计算单元。这就要求计算单元的配置必须是自动化、快速和弹性的,以便满足微服务的需求。
我在 2015 年加入 DigitalOcean 的时候,我和同事们花了很多时间思考我们的内部系统——云控制面板。那个时候,控制面板由三个单体应用组成,它们运行在 Chef Data Bag 的虚拟机上。但我们很快发现这种方式不仅复杂,而且容易出错,无法伸缩。我们需要在转向微服务之前改进我们的配置能力。
我们决定使用容器和 Kubernetes 作为新的计算平台,我们在 2016 年的头六个月把所有的新服务部署到了新平台上,同时把遗留的单体也迁移到上面。我们因此可以在对架构做出变更的同时发布新产品。事实上,我们的监控和告警组件就是在新平台上开发出来的。
Martin 说:
生产环境的很多轻度耦合的服务在一起协作容易出现问题,而这些问题在测试环境难以被发现。所以我们需要一个有效的监控机制来快速地检测这些问题。最起码要能够检测技术问题(计数器错误、服务可用性等),不过如果能够同时检测出业务问题(比如订单数的下降)就更好了。如果突然出现了问题,你要确保能够快速回滚……
微服务是一个复杂的系统,我们可以控制和预测的东西很有限。造成这种混乱主要是因为持续的变更,微服务几乎每天要部署好几次。
不过这些问题不是微服务独有的。事实上,十多年前,John Allspaw 等人在 Flickr 和 Etsy 就构建了一些工具用于解决这类问题,他们当时的架构还是单体。当时,Allspaw 在文档中记录了一些有关如何应付快速变更的方法:
换句话说,MTTR 比 MTBF 更重要。我并不是说故障是可接受的。我只是假定故障是一定会发生的,所以把时间和精力花在处理故障上要比花在如何避免故障上更有意义。我很同意 Hammond 的看法,他说:“如果你认为你可以避免故障,那么你就不会想着怎么提升处理故障的能力。”故障平均时间(MTBF)是指系统故障之间的时间间隔。修复平均时间(MTTR)是指修复一个故障所花掉的平均时间。简单地说,MTBF 会告诉你系统有多经常发生故障,而 MTTR 则告诉你故障在被检测到之后修复得有多快。在一个持续变化的系统里,你无法控制 MTBF,所以最好把时间和精力投入到如何改进 MTTR 上。
在你想办法改进 MTTR 的时候,你会发现,加快从故障中恢复的速度所能带来的好处越来越少。用于从故障中恢复的时间并非事故管理的唯一步骤,有时候,它占用的时间并不是最多的。我发现,事故管理当中最令人感到痛苦的是用于检测故障的时间(MTTD)。这个指标反映了故障从发生到被检测出来的时间。










