正文
图像识别是一项艰巨的任务
图像识别不是一件容易的事情。实现它的一个好方法是,将元数据应用于非结构化数据。聘请人类专家手动标注音乐和电影库可能是一项艰巨的任务,但是当涉及无人驾驶汽车的导航系统,如将道路上的行人与各种其他车辆区分开来或过滤,分类或标记每天在社交媒体上显示的用户上传的数百万个视频和照片等挑战时,将变得遥不可及。
解决这个问题的一个方法是利用神经网络。我们可以利用传统的神经网络在理论上分析图像,但在实践中,从计算的角度来说,成本将是非常昂贵的。例如,一个普通的试图处理小图像的神经网络(让它变为30 * 30像素)仍然需要50万个参数和900个输入。一个功能强大的机器可以处理这一点,但是,一旦图像变得更大(例如达到500 * 500像素),则需要的参数和输入数量就会增加到非常高的水平。
与图像识别神经网络的应用相关的另一个问题是过度拟合。简单来说,过度拟合发生在模型裁剪本身与其已经被训练的数据非常接近的时候。一般来说,这将导致附加参数(进一步增加计算成本)和模型对新数据的暴露导致一般性能下降。
卷积神经网络
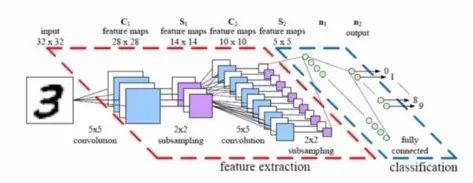
卷积神经网络架构模型
就神经网络的结构而言,一个相对简单的变化可以使更大的图像更易于管理。结果就是我们所说的CNN或ConvNets(卷积神经网络)。
神经网络的一般适用性是其优点之一,但是这种优势在处理图像时变成了一种妨碍。卷积神经网络进行有意思的权衡:如果一个网络是专门为处理图像而设计的,那么为了更可行的解决方案,必须牺牲一些一般性。
如果你考虑任何图像,接近度与其中的相似性具有很强的相关性,并且卷积神经网络明确利用了这一事实。这意味着在给定图像中,彼此更接近的两个像素更可能与彼此分开的两个像素相关。然而,在一般的神经网络中,每个像素都都与每一个神经元相连。增加的计算负荷使得网络在这种情况下不太准确。
通过停止很多这些不太重要的连接,卷积解决了这个问题。在技术术语中,卷积神经网络使得图像处理可以通过邻近度对连接进行滤波而计算可管理。在给定层中,卷积神经网络不是将每个输入连接到每个神经元,而是有意限制了连接,使得任何一个神经元仅从它之前的层的小部分接受输入(例如5 * 5或3 * 3像素)。因此,每个神经元只负责处理图像的某一部分(顺便说一句,这几乎是个体皮质神经元在大脑中的作用,每个神经元只对整个视野的一小部分起反应)。





