正文
1.帕金森病中的认知损伤还没有有效的干预手段;
2.那是因为相应的临床研究中,还有没办法对认知功能进行有效的基线控制和预测,导致临床研究的效率不高;
3.瞧瞧隔壁心血管科,人家有个Framingham风险评分,就是基于简单的性别、年龄及其他心血管危险因素,来预测10年内心血管疾病发生率,炒鸡friendly。我们帕金森也要搞一个。
首先,
研究者收集汇总了9个已发表研究的纵向队列数据(北美+欧洲),有的是人群观察队列,有的是生物标志物研究队列,有的是临床试验队列。它们原来的实验设计、纳排标准、和评价指标都不同。研究者认为正因此,由这些数据开发出为的模型更具有普适性。
9个队列的患者数据经过一系列纳排标准的筛选后,又把剩下的分为两个库,一个是由6个队列组成的发现库(discovery population),用于建立模型;另一个是重复库(replication population),由3个队列组成,用于验证模型。
其次,
建模所需要的风险因素(即自变量,Predictors),也是从既往文献报道中整理出来的,共有9个,分别为:
简易精神状态量表(MMSE);
蒙特利尔认知评估量表(MoCA);
国际帕金森病运动障碍协会改良统一帕金森病评分量表第II、第III部分(MDS-UPDRSII、MDS-UPDRS III);
帕金森病的发病年龄;
受教育年限;
性别;
抑郁状态;
β-葡糖脑苷脂酶(GBA)基因突变。
以上就是研究所需要的材料。然后通过那9个队列的数据,对9个变量进一步筛选,找出哪些确实有影响力,哪些没有;有影响力的,影响力又有多大,这才能形成一个精致的评分模型。
整个研究的流程如Figure 1所示:
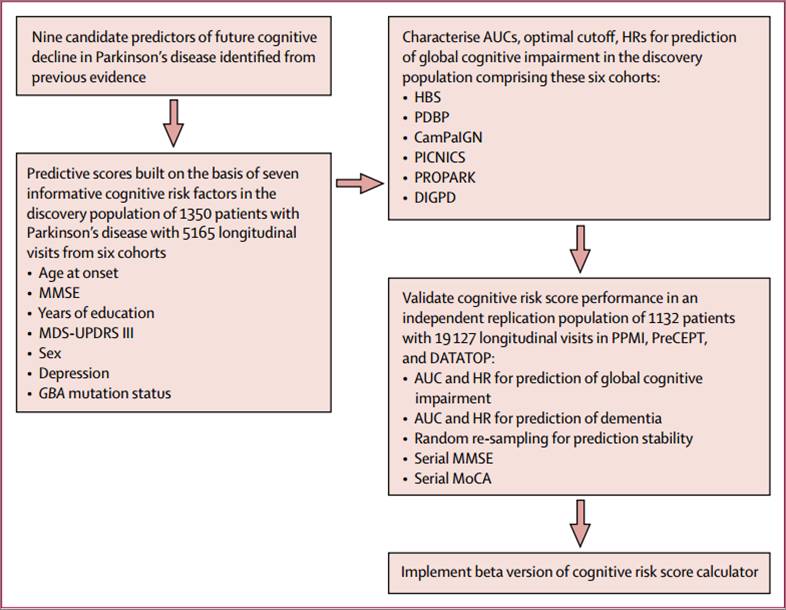
Figure1实验设计
第一步:建立模型
先在发现库中用Cox回归计算每个自变量的回归系数、风险比(HR)等统计量,剔除无效的自变量,于是MDS-UPDRSII评分先被刷掉了。





