正文
强化学习
基于来自环境的反馈,强化学习分析和优化智能体的行为。机器尝试不同的策略,从而发现哪种行为能产生最大的回报,因此智能体不是被告知应该采取哪种行为。试错和延迟的 reward 是将强化学习与其他技术区分的特点。
选择算法的注意事项
当选择一个算法的时候,你要时刻牢记如下方面:精确性、训练时间和易用性。很多用户将精确性置于首位,然而新手则倾向于选择他们最了解的算法。
当你有一个数据集后,第一件需要考虑的事情就是如何获得结果,无论这些结果可能会多么奇怪。新手倾向于选择易于实现且能快速获得结果的算法。这种思路仅在整个训练的第一步过程中适用。一旦你获得了一些结果并且开始逐渐熟悉数据,你或许应该花更多时间,使用更加复杂的算法来强化你对数据的理解,这样方可改进结果。
不过,即便到了这一步,达到最高精度的标准算法也可能不是最合适的算法,这是因为一个算法通常需要用户细致的调参以及大范围的训练才能获得其最佳性能。
选择具体算法的场景
对具体算法的深入研究可以帮助你理解它们的能力以及使用的方式。下面更多细节可为你选择具体算法提供进一步帮助,你可以配合前面速查表一起阅读。
线性回归和 Logistic 回归
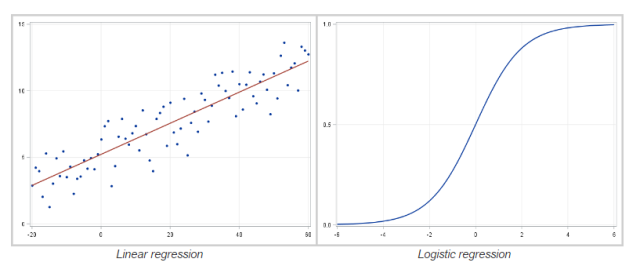
线性回归(linear regression)是一种对连续型因变量 y 与单个或多个特征 X 之间的关系进行建模的方法。y 和 X 之间的关系可被线性建模成 如下形式:当存在训练样本
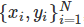 时,
时,
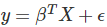 ,参数向量β可从训练样本中学到。
,参数向量β可从训练样本中学到。
如果因变量不连续且为类别,那么线性回归可以转为使用一个 Sigmoid 函数的 logistic 回归。logistic 回归是一种简便,快速而且强大的分类算法。这里讨论二值情况,即因变量 y 只有两个值 y∈(−1,1)(这可以很容易被扩展为多类分类问题)。
在 logistic 回归中,我们使用不同的假设类别来尝试预测一个给定样例是属于「1」类还是「-1」类的概率。具体而言,我们将尝试学习如下形式的一个函数:
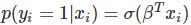 以及
以及
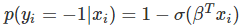 ,其中
,其中
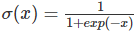 是一个 sigmoid 函数。当存在训练样本 {xi,yi} 时,参数向量β能在给定数据集下,最大化 β 对数似然值来学习。
是一个 sigmoid 函数。当存在训练样本 {xi,yi} 时,参数向量β能在给定数据集下,最大化 β 对数似然值来学习。

线性 SVM 和核 SVM
核(kernel)技巧可被用于将非线性可分函数映射成高维的线性可分函数。支持向量机(SVM)训练算法可以找到由超平面的法向量 w 和偏置项 b 表示的分类器。这个超平面(边界)可以按照最大间隔的方式来分开不同的类别。这个问题可以被转换一个条件优化问题:
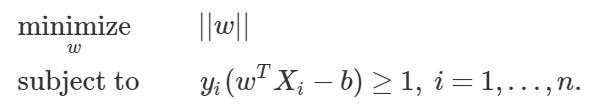
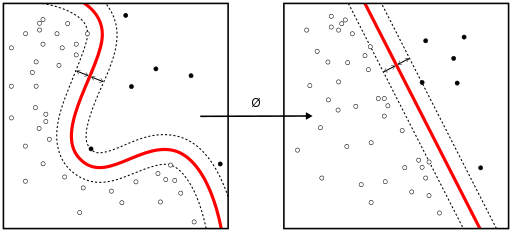
Kernel 技巧被用于将非线性可分函数映射成高维的线性可分函数
当类别不是线性可分的时候,核技巧可被用于将非线性可分空间映射到高维的线性可分空间。
当因变量不是数值型时,logistic 回归和 SVM 应该被用作分类的首要尝试。这些模型可以轻松实现,它们的参数易于调节,而且其性能也相当好。所以这些模型非常适合初学者。
树和集成树
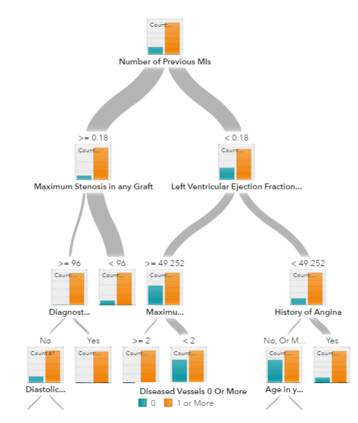
用于预测模型的决策树










