正文
图像生成任务有哪些特点
不过端到端网络的总体结构还不足以保证图像的质量。所以作者们在根据其它现有的网络结构做了很多实验以后,列举出了三项他们认为非常重要的特点,模型要满足这三点才能有足够好的表现。
全局的协调性
: 照片中物体的结构要正确,许多物体的结构都不是在局部独立存在的,它们可能有对称性。比如如果一辆车左侧的刹车灯亮了,那右侧的刹车灯也要亮。
高分辨率
:为了达到足够高的分辨率,模型需要具有专门的分辨率倍增模块。
记忆力 (Memory)
:网络需要有足够大的容量才能复现出图像中物体足够多的细节。一个好的模型不仅在训练集中要有好的表现,也要有足够的泛化能力,都需要网络容量足够大。
巧妙的网络结构设计
为了同时达到以上的三个特点,作者们设计了一个由多个分辨率倍增模块组成的级联优化网络 CRN。
模型一开始生成的图像分辨率只有 4x8,通过串接的多个分辨率倍增前馈网络模块,分辨率逐步翻番,最终达到很高的图像分辨率(比如最后一个模块把512x1024的图像变成1024x2048)。这就是论文标题的“Cascaded Refinement Networks”的体现。这样做的好处是,
1. 覆盖大范围的物体特征一开始的时候都是在很小的临近范围内表示的,它们的总体特征在一开始就是协调的,在分辨率逐步升高的过程中也能够保持下来,就达到了“
全局的协调性
”。
2. 在提高分辨率的过程中,使用串接的多个前馈网络模块就可以对整个模型做端到端的训练,如果这部分用 GANs 就没办法端到端训练,而且分辨率选择的灵活性也变差了。这样就保证了“
高分辨率
”。
3. 增加更多的分辨率倍增模块可以提高网络容量,作者们表示只要硬件能够支持就可以增加更多的模块,现在他们实验中用到的网络有超过1亿个参数,已经用尽了GPU的显存空间,但是有明确的证据表明继续增大网络容量可以继续提高图像质量。这样模块化的网络也就非常方便在硬件资源充足的情况下拓展网络容量。
每个分辨率增倍模块都在各自的分辨率下工作,它们的输入有两部分,一部分是降采样到当前模块分辨率的输入语义布局图像 L,另一部分是上一级模块的输出特征层 F
i-1
(最初的模块没有这一项输入),其中包含若干个 feature map。输出的 F
i
分辨率在输入 F
i-1
的基础上长宽都为2倍。
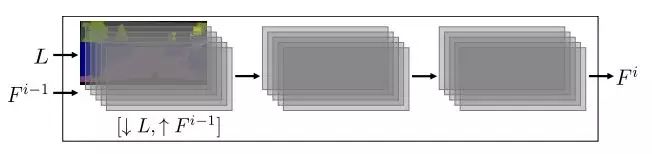
单个模块的示意图,L 和 F
i-1
为模块输入;语义布局图像 L 需要降采样,来自上一个模块的 F
i-1
需要升采样。





