正文
近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类领域特别是应用深度学习解决文本分类的相关的思路、做法和部分实践的经验。
业务问题描述
:
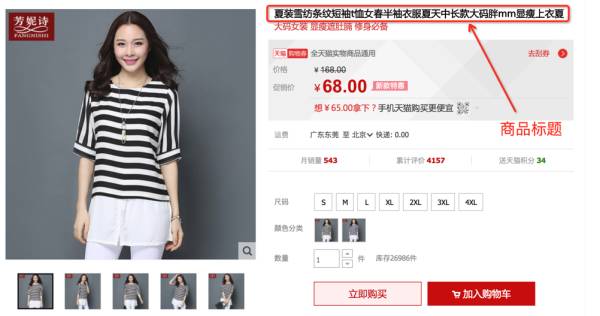
淘宝商品的一个典型的例子见下图,图中商品的标题是“
夏装雪纺条纹短袖t恤女春半袖衣服夏天中长款大码胖mm显瘦上衣夏
”。淘宝网后台是通过树形的多层的类目体系管理商品的,覆盖叶子类目数量达上万个,商品量也是10亿量级,我们是任务是根据商品标题预测其所在叶子类目,示例中商品归属的类目为“女装/女士精品>>蕾丝衫/雪纺衫”。很显然,这是一个非常典型的短文本多分类问题。接下来分别会介绍下文本分类传统和深度学习的做法,最后简单梳理下实践的经验。
一、传统文本分类方法
文本分类问题算是自然语言处理领域中一个非常经典的问题了,相关研究最早可以追溯到上世纪50年代,当时是通过专家规则(Pattern)进行分类,甚至在80年代初一度发展到利用知识工程建立专家系统,这样做的好处是短平快的解决top问题,但显然天花板非常低,不仅费时费力,覆盖的范围和准确率都非常有限。
后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典玩法,这个阶段的主要套路是人工特征工程+浅层分类模型。训练文本分类器过程见下图:
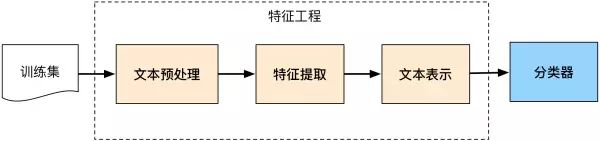
整个文本分类问题就拆分成了特征工程和分类器两部分,玩机器学习的同学对此自然再熟悉不过了
1.1 特征工程
特征工程在机器学习中往往是最耗时耗力的,但却极其的重要。抽象来讲,机器学习问题是把数据转换成信息再提炼到知识的过程,特征是“数据-->信息”的过程,决定了结果的上限,而分类器是“信息-->知识”的过程,则是去逼近这个上限。然而特征工程不同于分类器模型,不具备很强的通用性,往往需要结合对特征任务的理解。
文本分类问题所在的自然语言领域自然也有其特有的特征处理逻辑,传统分本分类任务大部分工作也在此处。文本特征工程分位文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。





