正文
进化策略易于实现和扩展。我们的实现运行在一个包含了 80 台机器和 1440 个 CPU 内核的计算集群上,其可以仅在 10 分钟内就训练出一个 3D MuJoCo 人形步行者(在 32 核上,A3C 需要大约 10 小时)。使用 720 核,我们也能在 Atari 上实现可与 A3C 媲美的表现,同时还能将训练时间从 1 天降低至 1 小时。
下面,我们将首次简要描述传统的强化学习方法与我们的进化策略方法的对比,还会讨论进化策略和强化学习之间的权衡,最后还会突出介绍我们的一些实验。
强化学习
首先让我们简单看看强化学习的工作方式。假设我们有一些环境(比如游戏),我们想要在其中训练一个代理。为了描述该代理的行为,我们要定义一个策略函数(policy function),这是该代理的大脑,用于计算该代理如何在一个给定的情形中采取行动。在实践中,这个策略通常是一个神经网络,其输入是该游戏的当前状态,然后计算可用的所有允许动作的概率。一个典型的策略函数可能有大约 1,000,000 个参数,所以我们的任务就是找到这些参数的确切配置,以使得该策略能够实现良好的表现(即在很多游戏中获胜)。

上图:在 Pong 游戏中,策略根据输入的屏幕像素来计算移动玩家拍子的概率(右边绿色的拍子):上、下或不动。
该策略的训练过程如下所示。首先是一个随机初始化,我们让该代理与环境进行一阵交互,然后收集交互的「剧情(episode)」(比如,每个 episode 就是一局 Pong 游戏)。由此我们就能得到情况的完整记录:遇到了什么样的状态序列、在每个状态采取了什么动作、每一步的奖励如何。下图给出了一个例子,这三个 episode 每个都表示在一个假想环境中的 10 个时间步骤。其中每个矩形都是一个状态,如果奖励是正面的(比如把球击回给了对方),那么矩形就是绿色;如果奖励是负面的(比如没有接到球),那么矩形则为红色:
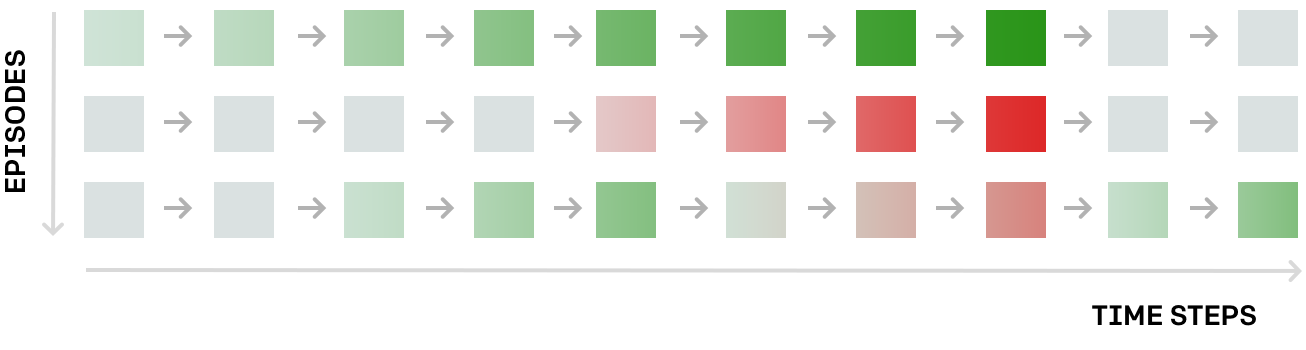
这幅图给出了改善策略的一个方法;导致绿色状态的行为是好的行为,导致红色的行为则很糟糕。然后我们可以使用反向传播来计算该网络参数的一次小的更新,该更新将使得未来的状态更有可能是绿色、更少可能是红色。我们预计更新后的策略会更好一点。然后我们迭代这一过程:收集另一批 episode,进行另一次更新……
通过在这些动作中注入噪声来进行探索。我们在强化学习中通常使用的策略是随机的,它们仅计算采取任何动作的概率。通过这种方法,代理可能会在训练过程中发现自己在不同时间处在同一个特定状态,而且由于采样的情况,它也将在不同的时间采取不同的动作。这能提供学习所需的信号:这些动作中有一些会导致好的结果,这些动作就会得到鼓励;另一些则不会奏效,就会被抑制。因此我们可以说,我们通过向代理的动作注入噪声而为其学习过程引入了探索(exploration)——我们可以通过在每个时间步骤从动作分布中采样来做到这一点。这与进化策略不同。
进化策略
关于「进化(Evolution)」。在我们探讨进化策略(ES)之前,有必要强调一下尽管这种方法名字中有「进化」这个词,但进化策略和生物进化关系不大。也许这项技术的早期版本从生物进化上获得了一些启发——在一定的抽象程度上,这种方法可被视为这样一个过程:从个体构成的群体中采样并让其中成功的个体引导未来后代的分布。但是,其数学细节在生物进化方法的基础上实现了很大的抽象,我们最好将进化策略看作是一类黑箱的随机优化技术。
黑箱优化。在进化策略中,让我们完全忘记代理、环境、涉及的神经网络和其中的交互吧。进化策略的整个设置就是一大堆数字输入(假设和前面提到的策略网络的参数数量一样,有 1,000,000 个数字),然后输出 1 个数字(对应总奖励),我们需要找到这 1,000,000 个数字的最好配置。在数学上,我们可以说是根据输入向量 w(该网络的参数/权重)来优化一个函数 f(w),但我们不对 f 的结构做出任何假设,我们只能对其进行评估(因此被称为「黑箱」)。









