正文
Condition 条件锁
Event 事件锁
Semaphore 信号量
这个就不展开细谈了,属于另一个语言无关的大领域。(以前写过一个很简略的简介:并行编程中的各种锁(https://blog.laisky
.com
/p/concurrency-lock/))
对于资源控制,一般来说主要就是两个地方:
-
缓存区有多大(Queue 长度)
-
并发量有多大(workers 数量)
一般来说,前者直接确定了你内存的消耗量,最好选择一个恰好或略高于消费量的数。后者一般直接决定了你的 CPU 使用率,过高的并发量会增加切换开销,得不偿失。
既然提到了 workers,稍微简单展开一下“池”这个概念。我们经常提到线程池、进程池、连接池。说白了就是对于一些可重用的资源,不必每次都创建新的,而是使用完毕后回收留待下一个数据继续使用。比如你可以选择不断地开子线程,也可以选择预先开好一批线程,然后通过 queue 来不断的获取和处理数据。
所以说使用“池”的主要目的就是减少资源的消耗。另一个优点是,使用池可以非常方便的控制并发度(很多新人以为 Queue 是用来控制并发度的,这是错误的,Queue 控制的是缓存量)。
对于连接池,还有另一层好处,那就是端口资源是有限的,而且回收端口的速度很慢,你不断的创建连接会导致端口迅速
耗尽
。
这里做一个用语的订正。Queue 控制的应该是缓冲量(buffer),而不是缓存量(cache)。一般来说,我们习惯上将写入队列称为缓冲,将读取队列称为缓存(有源)。
对前面介绍的 python 中进程/线程做一个小结,线程池可以用来解决 I/O 的阻塞,而进程可以用来解决 GIL 对 CPU 的限制(因为每一个进程内都有一个 GIL)。所以你可以开 N 个(小于等于核数)进程池,然后在每一个进程中启动一个线程池,所有的线程池都可以订阅同一个 Queue,来实现真正的多核并行。
非常简单的描述一下进程/线程,对于操作系统而言,可以认为进程是资源的最小单位(在 PCB 内保存如图 1 的数据)。而线程是调度的最小单位。同一个进程内的线程共享除栈和寄存器外的所有数据。
所以在开发时候,要小心进程内多线程数据的冲突,也要注意多进程数据间的隔离(需要特别使用进程间通信)
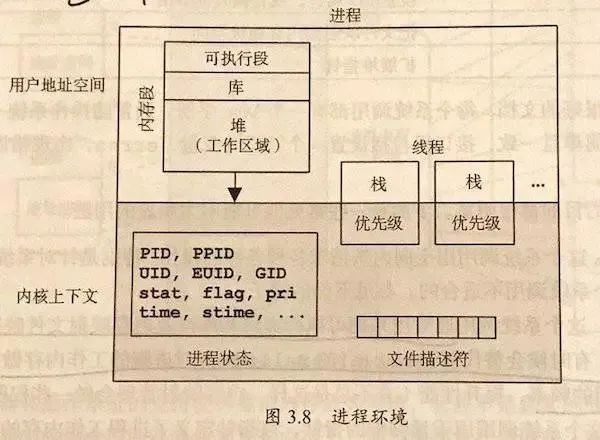

再简单的补充一下,进程间通信的手段有:管道、信号、消息队列、信号量、共享内存和套接字。不过在 Py 里,单机上最常用的进程间通信就是 multiprocessing 里的 Queue 和 sharedctypes。
顺带一提,因为 CPython 的 refcnt 机制,所以 COW(copy on write)并不可靠。
人们在见到别人的“错误写法”时,倾向于无视或吐槽讽刺。但是这个行为除了让自己爽一下外没有任何意义,不懂的还是不懂,最后真正发挥影响的还是那些能够描绘一整条学习路径的方法。
我一直希望能看到一个“朴素诚恳”的切合工程实践的教程,而不是网上流传的入门大全和网课兜售骗钱的框架调参速成。
关于进程间的内存隔离,补充一个简单直观的例子。可以看到普通变量
normal_v
在两个子进程内变成了两个独立的变量(都输出 1),而共享内存的
shared_v
仍然是同一个变量,分别输出了 1 和 2。
from time import sleep
from concurrent.futures import ProcessPoolExecutor, wait
from multiprocessing import Manager, Queue
from ctypes import c_int64
def worker(i, normal_v, shared_v):normal_v += 1 # 因为进程间内存隔离,所以每个进程都会得到 1
shared_v.value += 1 # 因为使用了共享内存,所以会分别得到 1 和 2
print(f'worker[{i}] got normal_v {normal_v}, shared_v {shared_v.value}')
def main:executor = ProcessPoolExecutor(max_workers=2)
with Manager as manager:lock = manager.Lockshared_v = manager.Value(c_int64, 0, lock=lock)
normal_v = 0
workers = [executor.submit(worker, i, normal_v, shared_v) for i in range(2)]
wait(workers)print('all done')
main
从过去的工作经验中,我总结了一个简单粗暴的规矩:如果你要使用多进程,那么在程序启动的时候就把进程池启动起来,然后需要任何资源都请在进程内自行创建使用。如果有数据需要共享,一定要显式的采用共享内存或 queue 的方式进行传递。
见过太多在进程间共享不该共享的东西而导致的极为诡异的数据行为。
最早,一台机器从头到尾只能干一件事情。
后来,有了分时系统,我们可以开很多进程,同时干很多事。
但是进程的上下文切换开销太大,所以又有了线程,这样一个核可以一直跑一个进程,而仅需要切换进程内子线程的栈和寄存器。
直到遇到了 C10K 问题,人们发觉切换几万个线程还是挺重的,是否能更轻?
这里简单的展开一下,内存在操作系统中会被划分为内核态和用户态两部分,内核态供内核运行,用户态供普通的程序用。
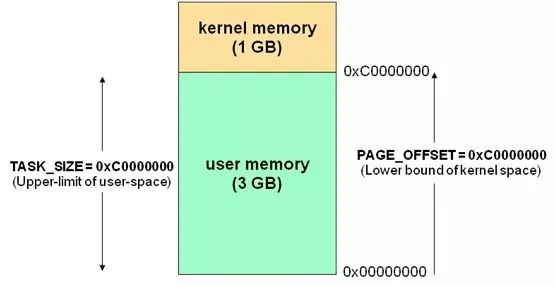
应用程序通过系统 API(俗称 syscall)和内核发生交互。拿常见的
HTTP
请求来说,其实就是一次同步阻塞的 socket 调用,每次调用都会导致线程阻塞等待内核响应(内核陷入)。
而被阻塞的线程就会导致切换的发生。所以自然会问,能不能减少这种切换开销?换句话说,能不能在一个地方把事情做完,而不要切来切去的。
这个问题有两个解决思路,一是把所有的工作放进内核去做(略)。
另一个思路就是把尽可能多的工作放到用户态来做。这需要内核接口提供额外的支持:异步系统调用。
如 socket 这样的调用就支持非阻塞调用,调用后会拿到一个未就绪的 fp,将这个 fp 交给负责管理 I/O 多路复用的 selector,再注册好需要监听的事件和回调函数(或者像 tornado 一样采用定时 poll),就可以在事件就绪(如
HTTP
请求的返回已就绪)时执行相关函数。
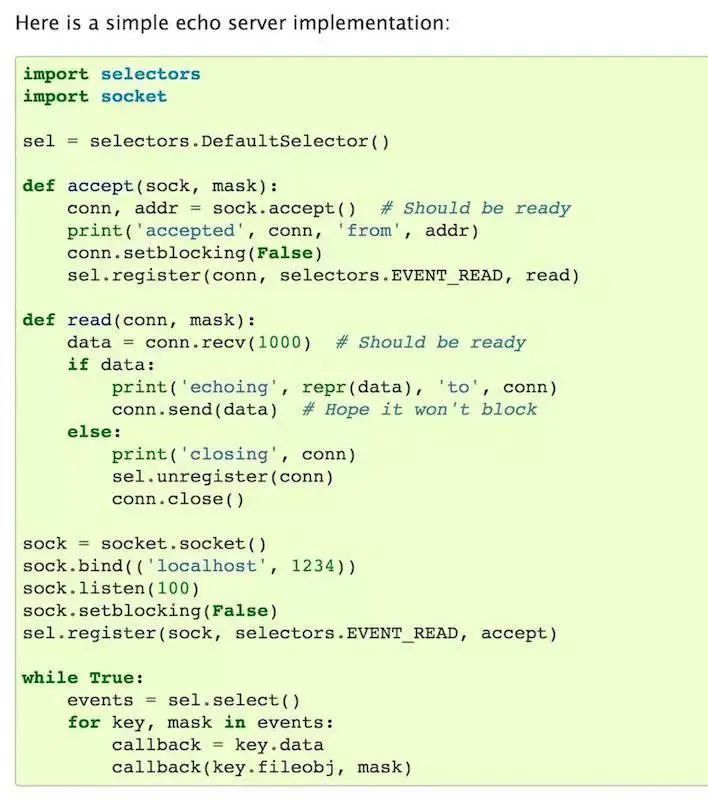
https://github
.com
/tornadoweb/tornado/blob/f1824029db933d822f5b0d02583e4e6137f2bfd2/tornado/ioloop.py#L746

这样就可以实现在一个线程内,启动多个曾经会导致线程被切换的系统调用,然后在一个线程内监听这些调用的事件,谁先就绪就处理谁,将切换的开销降到了最小。
有一个需要特别注意的要点,你会发现主线程其实就是一个死循环,所有的调用都发生在这个循环之内。所以,你写的代码一定要避免任何阻塞。

听上去很美好,这是个万能方案吗?
很可惜不是的,最直接的一个问题是,并不是所有的 syscall 都提供了异步方法,对于这种调用,可以用线程池进行封装。对于 CPU 密集型调用,可以用进程池进行封装,asyncio 里提供了 executor 和协程进行联动的方法,这里提供一个线程池的简单例子,进程池其实同理。
from time import sleep
from asyncio import get_event_loop, sleep as asleep, gather, ensure_future
from concurrent.futures import ThreadPoolExecutor, wait, Future
from functools import wraps
executor = ThreadPoolExecutor(max_workers=10)
ioloop = get_event_loopdef nonblocking(func) -> Future:@wraps(func)
def wrapper(*args):
return ioloop.run_in_executor(executor, func, *args)
return wrapper
@nonblocking # 用线程池封装没法协程化的普通阻塞程序
def foo(n: int):"""假装我是个很耗时的阻塞调用"""
print('start blocking task...')
sleep(n)print('end blocking task')
async def coroutine_demo(n: int):
"""我就是个普通的协程"""
# 协程内不能出现任何的阻塞调用,所谓一朝协程,永世协程# 那我偏要调一个普通的阻塞函数怎么办?# 最简单的办法,套一个线程池…await foo(n)
async def coroutine_demo_2:
print('start coroutine task...')
await asleep(1)
print('end coroutine task')
async def coroutine_main:
"""一般我们会写一个 coroutine 的 main 函数,专门负责管理协程"










