正文
Gartner 这里提及到了四种数据,Log Data, Wire Data, Metirc data,Document text。 这样的分类,我是个人持有保留意见,感觉很奇怪,特别是 Document text 的那块,需要用到NLP,主要是用于打通ITSM 产品,分析ITSM 工单。我对这个场景存在必要性,以及实现的ROI 表示怀疑。具体原因我可能稍后会写一篇文章,进行更详细的解释。
我认为,如果从宏观的类型来划分,应该这样划分 (下含部分我司产品介绍)
机器数据(Machine Data)
:
是IT系统自己产生的数据,包括客户端、服务器、网络设备、安全设备、应用程序、传感器产生的日志,及 SNMP、WMI,监控脚本等时间序列事件数据(含CPU 内存变化的程度),这些数据都带有时间戳。这里要强调, Machine Data 不等于Log Data ,因为指标数据包含。在通常的业界实践中,这些数据通常通过运行在主机上的一个Agent程序,如LogStash, File beat,Zabbix agent 等获得,如果我们的LogInsight,Server Insight 产品,就是面向此类型数据。
网络数据(Wire Data):
系统之间2~7层网络通信协议的数据,可通过网络端口镜像流量,进行深度包检测 DPI(Deep Packet Inspection)、包头取样 Netflow 等技术分析。一个10Gbps端口一天产生的数据可达100TB,包含的信息非常多,但一些性能、安全、业务分析的数据未必通过网络传输,一些事件的发生也未被触发网络通信,从而无法获得。我司的Network Insight 主要面向的是这些数据,提供关键应用的 7 x 24 小时全方位视图。
代理数据(Agent Data):
是在 .NET、PHP、Java 字节码里插入代理程序,从字节码里统计函数调用、堆栈使用等信息,从而进行代码级别的监控。我司的Application Insight主要是解决这个问题而诞生,能获得真正用户体验数据以及应用性能指标。
探针数据(Probe Data)
:
也就是所谓的拨测,是模拟用户请求,对系统进行检测获得的数据,如 ICMP ping、HTTP GET等,能够从不同地点模拟客户端发起,进行包括网络和服务器的端到端全路径检测,及时发现问题。 我司的Cloud Test,Cloud Performance Test 主要是产出这些数据的,CT的产品能从遍布全球的拨测点,对网站的可用性进行全天候的分布式监控。其中我们的CPT 给你带来从数百到数百万完全弹性的压力测试能力,获得应用在高压力的情况下的性能表现情况。
因为IT 监控技术发展实在是太庞杂,以上的划分不一定对,但是应该没有显著的遗漏。
但如果从微观技术的角度来看,不考虑数据的来源,只考虑数据本身的属性特点,我们可以这样划分:
指标数据( Metrics Data )
描述具体某个对象某个时间点这个就不用多说了, CPU 百分比等等,指标数据等等
日志数据 ( Logging Data )
描述某个对象的是离散的事情,例如有个应用出错,抛出了NullPointerExcepction,个人认为Logging Data 大约等同于 Event Data,所以告警信息在我认为,也是一种Logging Data。
调用链数据( Tracing Data ):
Tracing Data这词貌似现在还没有一个权威的翻译范式,有人翻译成跟踪数据,有人翻译成调用数据,我尽量用Tracing 这个词。 Tracing的特点就是,它在单次请求的范围内,处理信息。 任何的数据、元数据信息都被绑定到系统中的单个事务上。 例如:一次调用远程服务的RPC执行过程;一次实际的SQL查询语句;一次HTTP请求的业务性ID。 通过对Tracing 信息进行还原,我们可以得到调用链 Call Chain 调用链,或者是 Call Tree 调用数。
 官方OpenTracing 中的Call Tree例子。
官方OpenTracing 中的Call Tree例子。
在实践的过程中,很多的日志,都会有流水号,Trace ID, span ID, ChildOf, FollowsFrom 等相关的信息,如果通过技术手段,将其串联在一起,也可以将这些日志视为Tracing 。
Tracing信息越来越被重视,因为在一个分布式环境中,进行故障定位,Tracing Data 是必不可少的。
由于Tracing 相对于Logging 以及 Metircs 相对比较复杂一点,想深入了解的话,可以参考 :
《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》
bigbully.github.io/Dapp
/
Opentracing 的技术规范文档
github.com/opentracing/
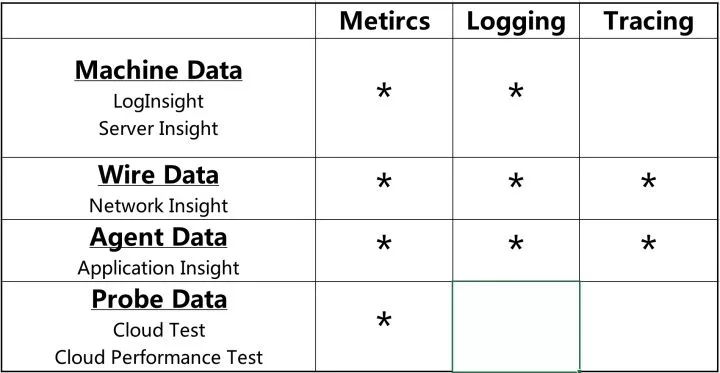
如果我们将以上数据类型做成一个矩阵看看,我们可以得到这样一个表格,比较好的说清楚了相关关系。
举例就是,我们的Server Insight 基础监控产品,能采集及处理指标数据,及日志,但是基础监控产品,不会处理Tracing Data,而我们的Application Insight 产品能从JVM 虚拟机中,通过插码,获得应用的响应时间(Metris),Java异常( Logging ),应用间的调用拓扑关系,以及调用的响应时间(Tracing)。