正文
VLM视觉模型
)+ 大脑(
Diffusion Transformer
)” 的分工模式,有效解决了机器人 “脑 - 体” 协同的难题,使得机器人能够在复杂环境中快速做出反应。
从技术实现角度看,GR00T N1 的跨本体泛化能力尤为突出。通过 “Embodiment-Specific Adapters”,它能够将不同机器人(如宇树 GR-1、傅利叶智能 Galbot)的关节空间投影到统一动作空间,支持在新机型上的快速迁移,无需重新训练基础模型。这一特性打破了传统机器人开发中 “一机一模型” 的局限,大大降低了开发成本和时间。在英伟达公布的实测视频中,在未见过的物体抓取任务中,GR00T N1 的成功率比传统模型提升 40%,充分证明了其泛化能力的优势。
开源生态也是 GR00T N1 的另一大特点。目前模型权重(2B 参数)和预训练脚本已经在 Hugging Face 开放,配套 LeRobot 数据格式支持快速接入自定义数据集。开发者可通过 4 步流程完成微调:数据转换(LeRobot 格式)、模态配置(视觉 / 状态 / 动作)、扩散模型训练(4 步去噪)、端侧部署(TensorRT 优化)。预计这种低门槛的开发模式,会使得更多中小团队甚至个人开发者能够参与到机器人开发中来。
除了GR00T N1,
Newton 开源物理引擎
也可以看作机器人仿真领域的一次重大突破。
基于 NVIDIA Warp 框架的Newton,实现了 70 倍于 MuJoCo (Multi-Joint dynamics with Contact)的仿真速度,支持极端场景下的复杂动力学模拟(如布料、流体、动态障碍物),单场景百万粒子计算耗时从 2 小时缩短至 1.5 分钟。这种效率提升不仅体现在计算速度上,更重要的是其微分编程特性。
通过允许梯度反向传播至物理参数(如摩擦系数),Newton 支持基于梯度的策略优化,较传统强化学习样本效率提升 3 倍。通过Newton引擎生成对抗样本(如低摩擦表面或动态障碍物),训练模型在极端条件下的鲁棒性。数据显示,在滑动表面测试中,经过对抗训练的模型成功率从32%提升至89%。这意味着开发者可以减少对真实硬件的依赖,通过更少的训练数据和时间,获得更优的控制策略,大大加速了机器人算法的迭代过程。
|
特性
|
传统引擎(如MuJoCo)
|
Newton引擎
|
|
GPU加速支持
|
无
|
支持CUDA并行计算
|
|
自动微分能力
|
需手动实现
|
内置JAX自动微分库
|
|
开源程度
|
部分模块开源
|
完全开源(MIT协议)
|
|
布料模拟精度
|
低
|
达到电影级效果
|
从生态兼容性来看,Newton 兼容 MuJoCo 仿真格式,支持 OpenUSD (Universal Scene Description)场景描述,可以添加自定义求解器,例如Material Point Method (MPM)求解器与沙子与刚体动力学相结合。这使得它能够无缝接入包括Isaac Lab、MuJoCo Playground在内的现有机器人开发工作流。
目前,迪士尼、DeepMind 等合作伙伴已基于 Newton 开发下一代娱乐机器人(如星球大战 BDX 机器人)和工业机械臂控制策略,充分证明了其在实际应用中的价值。据悉Newton将于今年下半年正式发布,值得一提的是,其开源协议(Apache 2.0)允许学术机构自由修改物理模型,这对于推动产学研协同创新,丰富机器人仿真的技术生态意义深远。
如何实现从 “数据贫困” 到 “数据爆炸” ?
前面我们提到,训练物理AI需要的百万级带标注的轨迹数据,这样的量级依靠真机采集完全不现实,互联网数据虽多,但大部分没有标注,并不可靠。英伟达给出的方案,是构建一个合成数据生成体系,如同三级火箭般层层推进,来解决物理 AI 数据稀缺的问题。
第一级是 GR00T-Teleop 采集金标准,NVIDIA Isaac GR00T Blueprint通过 Apple Vision Pro 等设备采集人类遥操作数据(Real Data),生成高精度示范轨迹(如 3D 关节坐标、接触力传感器数据),作为合成数据的 “种子”。这些数据具有极高的真实性和准确性,为后续的数据增广提供了可靠的基础。
第二级是 GR00T-Mimic 数据增广,工作流基于 Newton 引擎的 GPU 加速能力。在一个案例中,GR00T-Mimic将 5 条真实演示分解为子任务片段(如 “伸手→抓取→移动→放置”),通过空间变换生成 1000 条变体轨迹,覆盖目标位置、物体姿态的多样性。NVIDIA Isaac Sim的传感器模拟器则可生成视觉、IMU、力觉数据。例如,在模拟仓库环境中,同步记录货架高度、机器人运动轨迹和抓取力数据,构建多维度训练集。这些合成数据(Sim Data)增强技术不仅扩大了数据规模,更重要的是增加了数据的多样性,使得模型能够学习到更多复杂场景下的应对策略。
第三级是 Cosmos 世界模型扩展,基于 2000 万小时多模态数据训练的 Cosmos Predict,可预测物体运动轨迹(如 “推箱子时的滑动距离”),生成无限长尾场景数据,解决 “未见场景泛化” 问题。
通过这三级数据生成机制,开发者就能实现从少量真实数据到大量合成数据的跨越,为物理 AI 模型的训练提供了充足的 “燃料”。
那么问题又来了,真实数据与合成数据能混用吗?带来的成功率如何?这就涉及到“真实 - 合成数据协同训练”(Co-Training)。
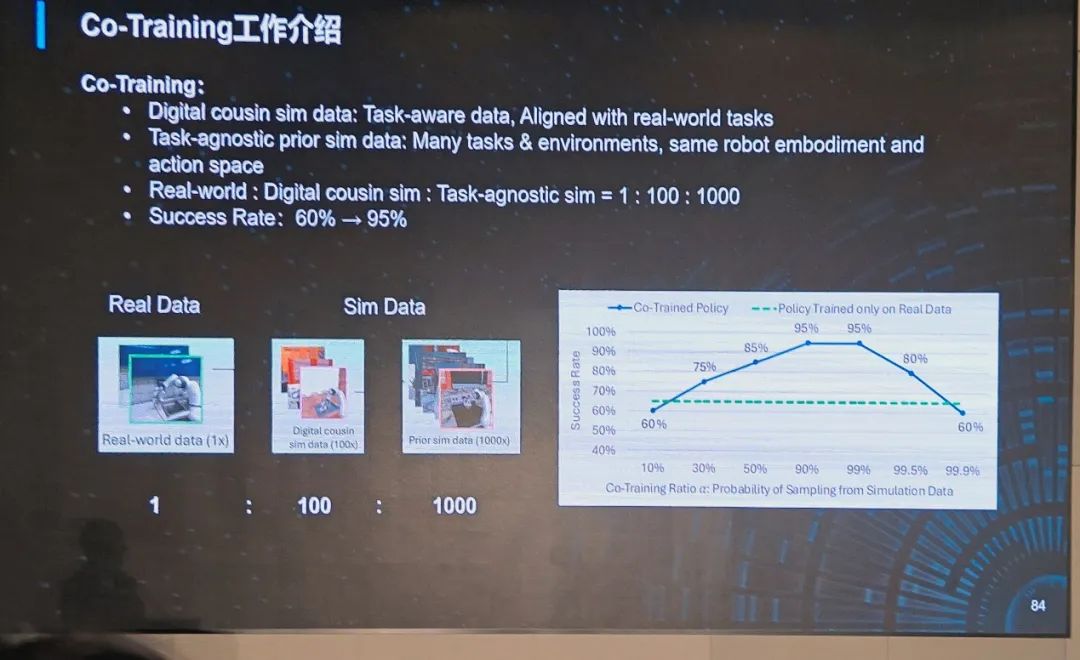
在数据训练层面,英伟达有一个 “数据金字塔” 策略。即,





