正文
做了一个简单的数据测试,生成10TB数据,进行数据拷贝大约花了15分钟,换算而言1PB约为1500分钟。如果我们把1500分钟约为1天(1440分钟)来算的话,10PB就要花10天的时间进行拷
贝迁移,这显然无法令人接受。
上面给我们的要求是最多只允许2~3小时的窗口时间内(此时间允许服务downtime),分毫不差地完成所有数据的迁移。毫无疑问,这听上去对我们来说是一个巨大的挑战。
通过多次的讨论,我们基本确认出以下两种方案:
方案一,初始全量拷贝+多次增量diff的数据拷贝。
此方式的好处在于这个数据拷贝可以提前做,只有第一次全量拷贝时花的时间比较长,后续都通过增量拷贝的方式来同步那些发生了变化的数据。然后我们在最终做change的时间窗口同步
最后一次的diff数据即可。在技术可行性上,DistCp本身已经支持结合HDFS Snapshot的方式来做这样的增量拷贝。
此方案的缺陷在于实际操作性比较复杂,在最终拷贝前,我们需要定期地去同步增量的数据。而且这时候老的数据还不能删除,集群需要有富余的空间同时存储新老数据。至于定期同步增量
数据的方式,我们还得考虑自动化的方式来搞。
方案二,静态数据拷贝+最终动态数据的拷贝。
方案二和方案一在数据分层次拷贝的思想大方向是一致的。区别点在于这里我们只做最终一次的剩余动态数据的拷贝而不做多次小增量数据的拷贝。在数量级别上,它的量还是有一定规模的
。
在实际操作上,方案二比较容易施行,因为我们只要在最终拷贝前,提前拷贝走静态不变的数据,留最后变动的数据在最后一次操作完成即可。
于是我们决定采用第二种方案。紧接着,我们要面对的一个核心问题来了:如何大幅度提升DistCp的数据拷贝效率。
尽管面临的挑战非常巨大,但是后面还是得一步步开始,从而将困难由大化小,由小化无。本章节中,笔者将简单聊聊我们是如何一步步对DistCp做优化的。
鉴于我们的集群处于HDFS Federation模式,下面的DN存储是共享的,所以并没有必要在物理数据层面进行拷贝。于是我们Backport了社区HDFS-2139 (HDFS-2139:Fast copy for HDFS)
的改动到我们内部版本中。
Fastcopy的拷贝过程与原始数据拷贝方式的最大区别在于物理数据是通过建立hardlink的方式来做,省去了实际数据拷贝的过程,以此大大缩短数据拷贝的时间,原理图如下所示:
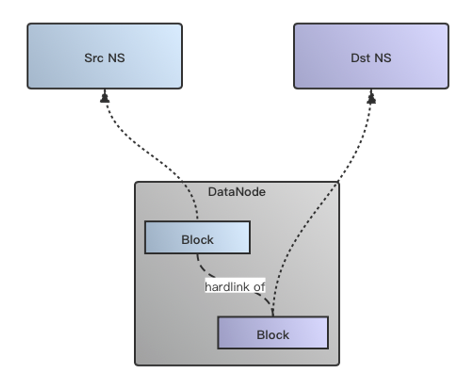
实现了HDFS Fastcopy后,我们将HDFS Fastcopy的文件拷贝操作集成到DistCp的文件拷贝过程中,通过新增一个useFastcopy的option开关来控制是否走Fastcopy的方式。
完成Fastcopy
这块的优化改动之后,我们做了性能对比测试,结果相比原生DistCp拷贝,速度提升了5倍之多。在Fastcopy的模式下,DistCp的map task就只需要做createFile,addBlock这样的简单
HDFS RPC操作了。
在实际测试过程中,我们经常发现因为文件size分布不均衡,导致长尾任务出现。比如要拷贝的目录里有众多的小文件,然后突然有个子目录里都是GB级别这样的大文件,于是这类大文件
被分到的那些task往往就会变得很慢,如果是在按照文件目录数进行划分的strategy(设置DynamicInputFormat)中则更为为明显。
但是如果按拷贝文件size进行均分,在Fastcopy下时其实是没有意义的,因为我们并不copy实际的物理数据。
我们想了一个办法,在还是基于文件size分配策略的逻辑下,对不足1个块大





