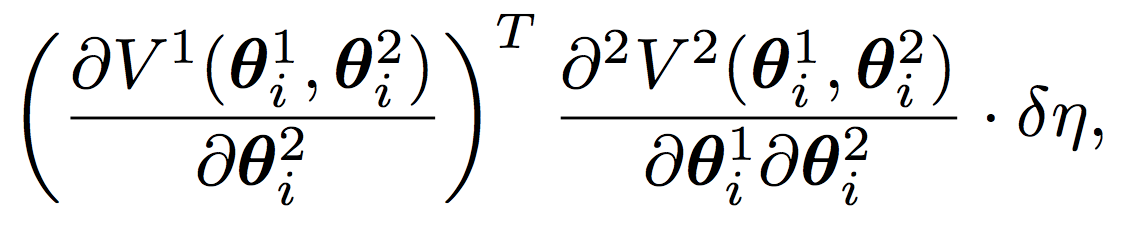正文
具体说,LOLA智能体“Alice”会对另一个智能体Bob的参数更新进行建模,建模的过程依赖于Alice自己的策略以及Bob参数更新对Alice预期回报的影响。然后,Alice会更新自己的策略,让其他智能体(比如Bob)的学习步骤更有利于自己的目标。
LOLA智能体可以在游戏(比如迭代的囚徒困境或捡硬币游戏)中,发现有效的互惠策略。相比之下,最先进的深度强化学习方法,比如 Independent PPO,无法在游戏中学习这样的策略。这些智能体一般都会学习采取自私的行为,忽视其他智能体的目标。LOLA解决了这个问题,虽然也是让智能体采取有利于自身利益的行动,但这个行动也包含了其他智能体的目标在里面。有了LOLA,就不需要手工制定促进合作的规则,也不需要设置环境条件鼓励合作,智能体能自动探求倾向于合作的行为。
研究人员表示,LOLA的灵感来自于人类是如何合作的:人类非常擅长于推理自己的行动将如何影响其他人未来的行动,并且经常发明与其他人合作的方式来实现“双赢”。人类善于合作的原因之一,是他们对其他人有一种“心智理论”(theory of mind),这让他们制定出为合作方带来好处的策略。
到目前为止,这种“心智理论”还没有在深度多代理强化学习中得到体现。对于当前最先进的深度RL智能体来说,另一个智能体只是环境中第一部分,跟一棵树没有固有的区别。
LOLA性能的关键是项的纳入(inclusion of term):