正文
def sentence2sequence
(sentence):
“””
– Turns an input paragraph into an (m,d) matrix,
where n is the number of tokens in the sentence
and d is the number of dimensions each word vector has.
TensorFlow doesn’t need to be used here, as simply
turning the sentence into a sequence based off our
mapping does not need the computational power that
TensorFlow provides. Normal Python suffices for this task.
“””
tokens = sentence.strip(‘”(),-‘).lower().split(” “)
rows = []
words = []
#Greedy search for tokens
for token in tokens:
i = len(token)
while len(token) > 0:
word = token[:i]
if word in glove_wordmap:
rows.append(glove_wordmap[word])
words.append(word)
token = token[i:]
i = len(token)
continue
else:
i = i-1
if i == 0:
# word OOV
# https:
rows.append(fill_unk(token))
words.append(token)
break
return np.array(rows), words
现在我们可以把每个问题需要的数据给打包起来了,包括上下文、问题和答案的词向量。在bAbI里,上下文被我们定义成了带有序号的句子。用contextualize函数可以完成这个任务。问题和答案都在同一行里,用tab符分割开。因此在一行里我们可以使用tab符作为区分问题和答案的标记。当序号被重置后,未来的问题将会指向是新的上下文(注意:通常对于一个上下文会有多个问题)。答案里还有另外一个我们会保留下来但不用的信息:答案对应的句子的序号。在我们的系统里,神经网络将会自己学习用来回答问题的句子。
def contextualize(set_file):
“””
Read in the dataset of questions and build question+answer -> context sets.
Output is a list of data points, each of which is a 7-element tuple containing:
The sentences in the context in vectorized form.
The sentences in the context as a list of string tokens.
The question in vectorized form.
The question as a list of string tokens.
The answer in vectorized form.
The answer as a list of string tokens.
A list of numbers for supporting statements, which is currently unused.
“””
data = []
context = []
with open(set_file, “r”, encoding=”utf8″) as train:
for line in train:
l, ine = tuple(line.split(” “, 1))
# Split the line numbers from the sentences they refer to.
if l is “1”:
# New contexts always start with 1,
# so this is a signal to reset the context.
context = []
if “\t” in ine:
# Tabs are the separator between questions and answers,
# and are not present in context statements.
question, answer, support = tuple(ine.split(“\t”))
data.append((tuple(zip(*context))+
sentence2sequence(question)+
sentence2sequence(answer)+
([int(s) for s in support.split()],)))
# Multiple questions may refer to the same context, so we don’t reset it.
else:
# Context sentence.
context.append(sentence2sequence(ine[:-1]))
return data
train_data = contextualize(train_set_post_file)
test_data = contextualize(test_set_post_file)
final_train_data = []
def finalize(data):
“””
Prepares data generated by contextualize() for use in the network.
“””
final_data = []
for cqas in train_data:
contextvs, contextws, qvs, qws, avs, aws, spt = cqas
lengths = itertools.accumulate(len(cvec) for cvec in contextvs)
context_vec = np.concatenate(contextvs)
context_words = sum(contextws,[])
# Location markers for the beginnings of new sentences.
sentence_ends = np.array(list(lengths))
final_data.append((context_vec, sentence_ends, qvs, spt, context_words, cqas, avs, aws))
return np.array(final_data)
final_train_data = finalize(train_data)
final_test_data = finalize(test_data)
定义超参数
到这里,我们已经完全准备好了所需的训练和测试数据。下面的任务就是构建用来理解数据的神经网络。让我们从清除TensorFlow的默认计算图开始,从而能让我们在修改了一些东西后再次运行网络。
tf.reset_default_graph()
这里是网络的开始,因此让我们在这里定义所有需要的常量。我们叫它们“超参数”,因为它们定义了网络的结构和训练的方法。
# Hyperparameters
# The number of dimensions used to store data passed between recurrent layers in the network.
recurrent_cell_size = 128
# The number of dimensions in our word vectorizations.
D = 50
# How quickly the network learns. Too high, and we may run into numeric instability
# or other issues.
learning_rate = 0.005
# Dropout probabilities. For a description of dropout and what these probabilities are,
# see Entailment with TensorFlow.
input_p, output_p = 0.5, 0.5
# How many questions we train on at a time.
batch_size = 128
# Number of passes in episodic memory. We’ll get to this later.
passes = 4
# Feed Forward layer sizes: the number of dimensions used to store data passed from feed-forward layers.
ff_hidden_size = 256
weight_decay = 0.00000001
# The strength of our regularization. Increase to encourage sparsity in episodic memory,
# but makes training slower. Don’t make this larger than leraning_rate.
training_iterations_count = 400000
# How many questions the network trains on each time it is trained.
# Some questions are counted multiple times.
display_step = 100
# How many iterations of training occur before each validation check.
网络架构
有了这些超参数,让我们定义网络的架构。这个架构大致能被分成4个模块,具体描述请见这篇《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》。
网络里定义了一个循环层,能基于文本里的其他的信息被动态地定义,因此叫动态记忆网络(DMN,Dynamic Memory Network)。DMN大致是基于人类是如何试图去回答一个阅读理解类型的问题的理解。首先,人类会读取一段上下文,并在记忆里创建一些事实内容。基于这些记住的内容,他们再去读问题,并再次查看上下文,特别是去寻找和问题相关的答案,并把问题和每个事实去比对。
有时候,一个事实会把我们引向另外一个事实。在bAbI数据集里,神经网络可能是想找到一个足球的位置。它也许会搜索句子里和足球相关的内容,并发现John是最后一个接触足球的人。然后搜索和John相关的句子,发现John曾经出现在卧室和门厅里。一旦它意识到John最后是出现在门厅里,它就可以有信心地回答这个问题,指出足球是在门厅里。
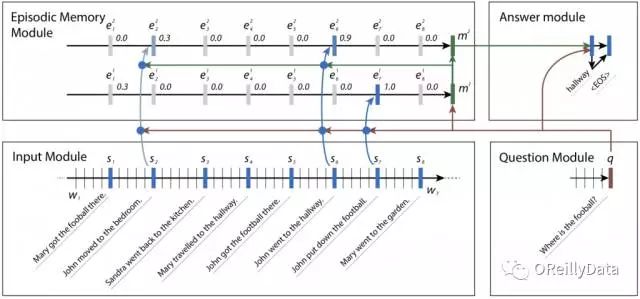
图3 神经网络里的4个模型,它们组合在一起来回答bAbI的问题。在每个片段里,新的事实被注意到,它们能帮助找到答案。Kumar注意到这个网络不正确地给句子2分配了权重,但这也合理,因为John曾经在那里,尽管此时他没有足球。来源:Ankit Kumar等,授权使用
输入模块
输入模块是我们的动态记忆网络用来得到答案的4个模块的第一个。它包括一个带有门循环单元(GRU,Gated Recurrent Unit,在TensorFlow里的tf.contrib.nn.GRUCell)的输入通道,让数据通过来收集证据片段。每个片段的证据或是事实都对应这上下文的单个句子,并由这个时间片的输出所代表。这就要求一些非TensorFlow的预处理,从而能获取句子的结尾并把这个信息送给TensorFlow来用于后面的模块。
我们会在后面训练的时候处理这些额外的过程。我们会使用TensorFlow的gather_nd来处理数据从而选择相应的输出。gather_nd功能是一个非常有用的工具。我建议你仔细看看它的API文档来学习它是如何工作的。
# Input Module
# Context: A [batch_size, maximum_context_length, word_vectorization_dimensions] tensor
# that contains all the context information.
context = tf.placeholder(tf.float32, [None, None, D], “context”)
context_placeholder = context # I use context as a variable name later on
# input_sentence_endings: A [batch_size, maximum_sentence_count, 2] tensor that
# contains the locations of the ends of sentences.
input_sentence_endings = tf.placeholder(tf.int32, [None, None, 2], “sentence”)
# recurrent_cell_size: the number of hidden units in recurrent layers.
input_gru = tf.contrib.rnn.GRUCell(recurrent_cell_size)
# input_p: The probability of maintaining a specific hidden input unit.
# Likewise, output_p is the probability of maintaining a specific hidden output unit.
gru_drop = tf.contrib.rnn.DropoutWrapper(input_gru, input_p, output_p)
# dynamic_rnn also returns the final internal state. We don’t need that, and can
# ignore the corresponding output (_).
input_module_outputs, _ = tf.nn.dynamic_rnn(gru_drop, context, dtype=tf.float32, scope = “input_module”)
# cs: the facts gathered from the context.
cs = tf.gather_nd(input_module_outputs, input_sentence_endings)
# to use every word as a fact, useful for tasks with one-sentence contexts
s = input_module_outputs
问题模块
问题模块是第二个模块,也可是说是最简单的一个。它包括另外一个GRU的通道。这次是处理问题的文本。不再是找证据,我们就是简单地进入结束状态,因为数据集里的问题肯定就是一个句子。
# Question Module
# query: A [batch_size, maximum_question_length, word_vectorization_dimensions] tensor










