正文
13 libsystem_pthread.dylib 0x07fff93c17637 _pthread_wqthread + 729
14 libsystem_pthread.dylib 0x07fff93c1540d start_wqthread + 13
主线程闲置时
Thread 0 Crashed:: Dispatch queue: com.apple.main-thread 0 libsystem_kernel.dylib 0x00007fff906614de mach_msg_trap + 10 1 libsystem_kernel.dylib 0x00007fff9066064f mach_msg + 55 2 com.apple.CoreFoundation 0x00007fff9a8c1eb4 __CFRunLoopServiceMachPort 3 com.apple.CoreFoundation 0x00007fff9a8c137b __CFRunLoopRun + 1371 4 com.apple.CoreFoundation 0x00007fff9a8c0bd8 CFRunLoopRunSpecific + 296 ... 10 com.apple.AppKit 0x00007fff8e823c03 -[NSApplication run] + 594 11 com.apple.AppKit 0x00007fff8e7a0354 NSApplicationMain + 1832 12 com.example 0x00000001000013b4 start + 52
|
主队列
Thread 0 Crashed:: Dispatch queue: com.apple.main-thread
12 com.apple.Foundation 0x00007fff931157e8 __NSBLOCKOPERATION_IS_CALLING
_OUT_TO_A_BLOCK__ + 7 13 com.apple.Foundation 0x00007fff931155b5 -[NSBlockOperation main] + 9 14 com.apple.Foundation 0x00007fff93114a6c -[__NSOperationInternal _
start:] + 653 15 com.apple.Foundation 0x00007fff93114543 __NSOQSchedule_f + 184 16 libdispatch.dylib 0x00007fff935d6c13 _dispatch_client_callout + 8 17 libdispatch.dylib 0x00007fff935e2cbf _dispatch_main_queue_callback
_4CF + 861 18 com.apple.CoreFoundation 0x00007fff8d9223f9 __CFRUNLOOP_IS_SERVICING_THE
_MAIN_DISPATCH_QUEUE__ 19 com.apple.CoreFoundation 0x00007fff8d8dd68f __CFRunLoopRun + 2159 20 com.apple.CoreFoundation 0x00007fff8d8dcbd8 CFRunLoopRunSpecific + 296 ... 26 com.apple.AppKit 0x00007fff999a1bd3 -[NSApplication run] + 594 27 com.apple.AppKit 0x00007fff9991e324 NSApplicationMain + 1832 28 libdyld.dylib 0x00007fff9480f5c9 start + 1
|
I/O 性能优化
I/O 是性能消耗大户,任何的 I/O 操作都会使低功耗状态被打破,所以减少 I/O 次数是这个性能优化的关键点,为了达成这个目下面列出一些方法。
-
将零碎的内容作为一个整体进行写入
-
使用合适的 I/O 操作 API
-
使用合适的线程
-
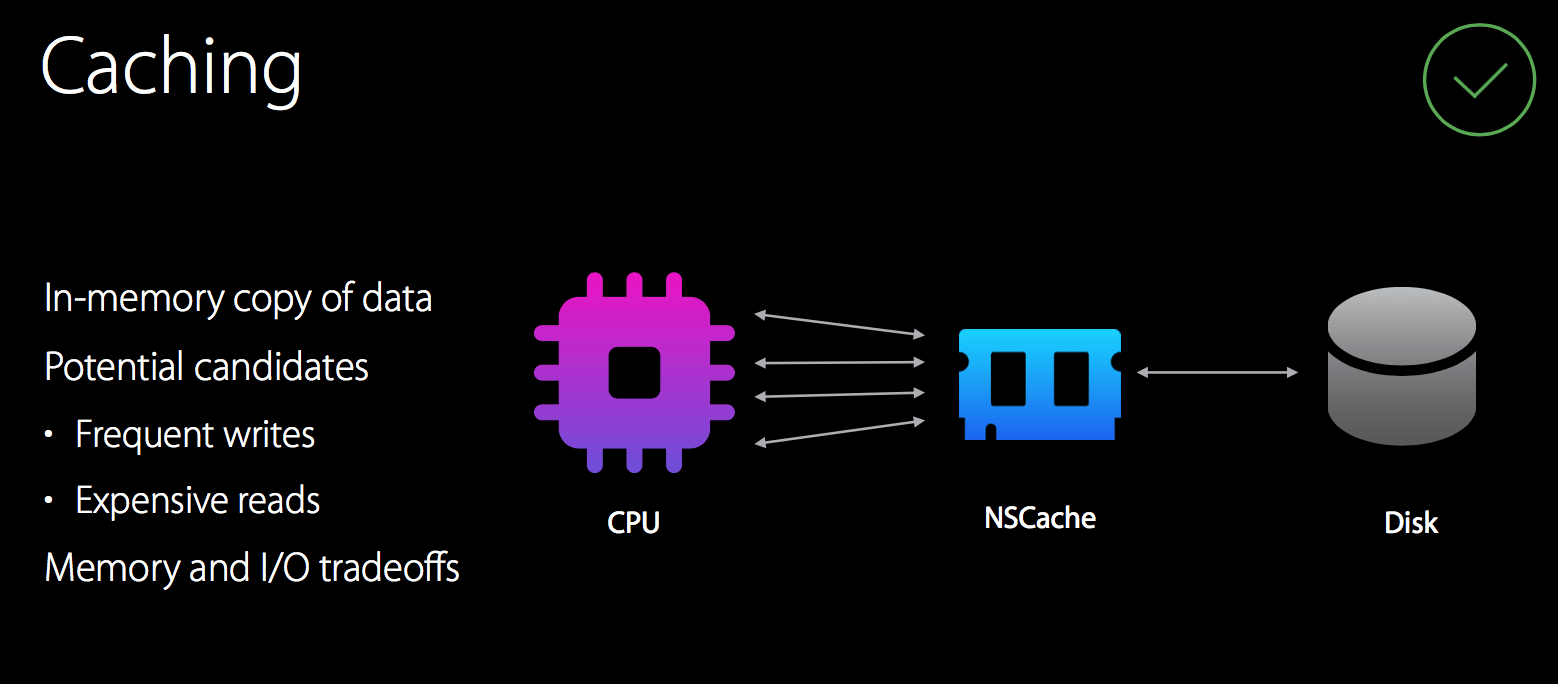
使用 NSCache 做缓存能够减少 I/O

控制 App 的 Wake 次数
通知,VoIP,定位,蓝牙等都会使设备从 Standby 状态唤起。唤起这个过程会有比较大的消耗,应该避免频繁发生。通知方面主要要在产品层面多做考虑。定位方面,下面可以看看定位的一些 API 看看它们对性能的不同影响,便于考虑采用合适的接口。
连续的位置更新
[locationManager startUpdatingLocation]
|
这个方法会时设备一直处于活跃状态。
延时有效定位
[locationManager allowDeferredLocationUpdatesUntilTraveled: timeout:] ``` 高效节能的定位方式,数据会缓存在位置硬件上。适合于跑步应用应该都采用这种方式。 重大位置变化 ```objc [locationManager startMonitoringSignificantLocationChanges]
|
会更节能,对于那些只有在位置有很大变化的才需要回调的应用可以采用这种,比如天气应用。
区域监测
[locationManager startMonitoringForRegion:(CLRegion *)]
|
也是一种节能的定位方式,比如在博物馆里按照不同区域监测展示不同信息之类的应用比较适合这种定位。
经常访问的地方
// Start monitoringlocationManager.startMonitoringVisits()// Stop
monitoring when no longlocationManager.stopMonitoringVisits()
|
总的来说,不要轻易使用 startUpdatingLocation() 除非万不得已,尽快的使用 stopUpdatingLocation() 来结束定位还用户一个节能设备。
内存对于性能的影响
首先 Reclaiming 内存是需要时间的,突然的大量内存需求是会影响响应的。
如何预防这些性能问题,需要刻意预防么
坚持下面几个原则争取在编码阶段避免一些性能问题。
那么如果写需求时来不及注意这些问题做不到预防的话,可以通过自动化代码
检查
的方式来避免这些问题吗?
如何检查
根据这些问题在代码里查,写工具或用工具自动化查?虽然可以,但是需要考虑的情况太多,现有工具支持不好,自己写需要考虑的点太多需要花费太长的时间,那么什么方式会比较好呢?
通过监听主线程方式来监察
首先用
CFRunLoopObserverCreate 创建一个观察者里面接受 CFRunLoopActivity 的回调,然后用
CFRunLoopAddObserver 将观察者添加到 CFRunLoopGetMain() 主线程 Runloop 的
kCFRunLoopCommonModes 模式下进行观察。
接下来创建一个子线程来进行监控,使用 dispatch_semaphore_wait 定义区间时间,标准是 16 或 20
微秒一次监控的话基本可以把影响响应的都找出来。监控结果的标准是根据两个 Runloop 的状态 BeforeSources 和
AfterWaiting 在区间时间是否能检测到来判断是否卡顿。
如何打印堆栈信息,保存现场
打印堆栈整体思路是获取线程的信息得到线程的 state 从而得到线程里所有栈的指针,根据这些指针在 符号表里找到对应的描述即符号化解析,这样就能够展示出可读的堆栈信息。具体实现是怎样的呢?下面详细说说:
获取线程的信息
这里首先是要通过 task_threads 取到所有的线程,
thread_act_array_t threads; //int 组成的数组比如 thread[1] = 5635 mach_msg_type_number_t thread_count = 0; //mach_msg_type_number_t 是 int 类型 const task_t this_task = mach_task_self(); //int //根据当前 task 获取所有线程 kern_return_t kr = task_threads(this_task, &threads, &thread_count);
|
遍历时通过 thread_info 获取各个线程的详细信息
SMThreadInfoStruct threadInfoSt = {0}; thread_info_data_t threadInfo; thread_basic_info_t threadBasicInfo;
|