正文
外层的 DAG 由不同的 node 构成,每一个 node 具备独立的执行环境,即上文提及的 Spark、Tensorflow、Hive、Storm、Flink 等计算引擎。外层 DAG 设计的初衷是让最合适的锤子去敲击最适合的钉子,大多数计算引擎因其设计阶段的历史局限性,都很难做到兼顾所有的工作负载类型,而是在不同程度上更好地支持某些负载(如批处理、流式实时处理、即时查询、分析型数据仓库、机器学习、图计算、交易型数据库等),因此我们的思路是让用户选择最适合自己业务负载的计算引擎。
内层的 DAG,根据计算引擎的不同,利用引擎的特性与优化机制,实现不同的抽象作为 DAG 中计算模块之间数据交互的载体。例如在 Spark node 中,我们会充分挖掘并利用 Spark 已有的优化策略和数据结构,如 Datasets、Dataframe、Tungsten、Whole Stage Code Generation,并将 Dataframe 作为 Spark node 内 DAG 数据流的载体。
在每一个 node 内部,根据其在 DAG 中上下游的位置,提供了三种操作类型的抽象,即Input、Process、Output。Input 基类定义了 Spark node 中输入数据的格式、读取和解析规范,用户可以根据 Spark 支持的数据源,创建各种格式的 Input,如图 2 中示例的 Parquet、Orc、Json、Text、CSV。当然用户也可以定义自己的输入格式,如图 2 中示例的 Libsvm。
在微博的机器学习模型训练中,有一部分场景是需要 Libsvm 格式数据作为训练样本,用户可以通过实现Input中定义的规范和接口,实现 Libsvm 格式数据的读入模块。通过 Input 读入的数据会被封装为Dataframe,传递给下游的 Process 类处理模块。
Process 基类定义了用户计算逻辑的通用规范和接口,通过实现 Process 基类中的函数,开发者可以灵活地实现自己的计算逻辑,如图 2 中示例的数据统计、清洗、过滤、组合、采样、转换等,与机器学习相关的模型训练、预测、测试等步骤,都可以在 Process 环节实现。通过 Process 处理的数据,依然被封装为 Dataframe,并传递给下游的 Output 类处理模块。
Output 类将 Process 类传递的数据进一步处理,如模型评估、输出数据存储、模型文件存储、输出 AUC 等,最终将结果以不同的方式(磁盘存储、屏幕打印等)输出。需要指出的是,凡是 Input 支持的数据读入格式,Output 都有对应的存储格式支持,从而形成逻辑上的闭环。
在使用方面,业务人员根据事先约定好的规范和格式,将双层 DAG 的计算逻辑定义在 XML 配置文件中。依据用户在 XML 指定的依赖关系和处理模块类,Weiflow 将自动生成 DAG 任务流图,并在运行时阶段调用处理模块的实现类来完成用户指定的任务流。
代码1展示了微博应用广泛的 GBDT+LR 模型训练流程的开发示例(由于篇幅有限,示例中只保留了第一个 node 的细节),代码 1 示例的训练流程所构成的双层 DAG 依赖及任务流图如图 3 所示。通过在 XML 配置文件中将所需计算模块按照依赖关系(外层的 node 依赖关系与内层的计算逻辑依赖关系)堆叠,即可以搭积木的方式完成配置化、模块化的流水线作业开发。
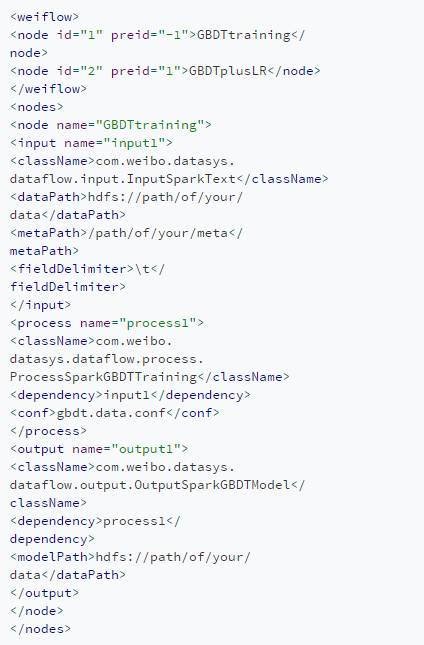
代码1 用Weiflow完成微博GBDT+LR模型训练流程

图3 Weiflow中微博GBDT+LR模型训练流程的双层DAG依赖关系及任务流
图
通过灵活的模块化开发,业务人员大幅提升了机器学习、数据科学作业的效率。随着微博的业务场景越来越复杂,业务需求也呈多样化的发展趋势,为了让更多的开发者灵活地扩展 Weiflow 的功能,Weiflow 在设计之初便充分考量了框架的可扩展性。Weiflow 通过多层次、模块化的抽象,提供近乎无限的扩展能力。
多层次的抽象是为了满足DAG外层计算引擎(上文提及的 Spark、Tensorflow、Hive、Storm、Flink等)的可扩展性,通过 Top level abstraction 提供的高度抽象定义,DAG 外层的各个计算引擎只需继承 Top level 抽象中定义的属性和方法,即可实现对计算引擎层面抽象的实现。
如图4所示,黑色文本框中的 Top level abstraction 提供了多个抽象 Base,蓝色文本框中不同的执行引擎通过继承其属性和方法,提供更加具体的抽象实现。当有新的计算引擎(如 Apache Flink)需要添加至 Weiflow 时,用户只需将新定义的计算引擎类继承 Top level 的抽象类,即可提供该引擎的抽象实现。








