正文
-
IP 添加 IP 头(源和目的地址,协议等),交给 ETH(对于这个场景一般来说 IP 层不需要再分片)
-
ETH 添加 ETH 头(源 MAC 和目的地 MAC),并计算 CRC,交给网卡
-
网卡为这个 frame 添加合适的 preamble,序列化成电信号,传输出去
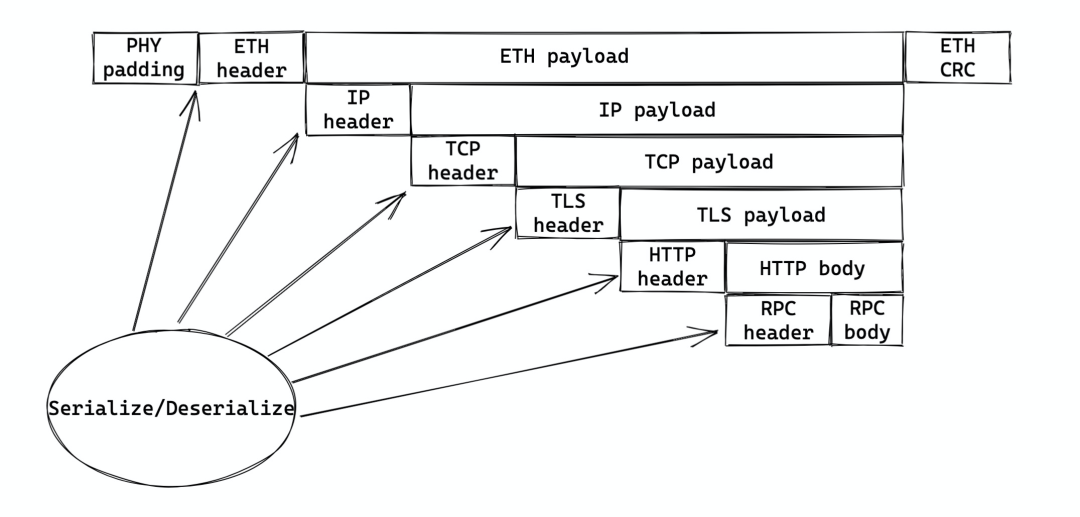
(搜不到合适的,我自己 excalidraw 画的)
我想你大概明白我的意思了。一切和信息相关的活动,都离不开序列化和反序列化。软件如此,硬件如此,序列化无处不在。
我们看:
不光是纯粹的通讯本身,就连我们写代码最基础的方法论:抽象,都离不开序列化。上文我们所谈的函数就是一个例子。函数是一切抽象的基础,而栈上的序列化和反序列化是函数得以正常执行的基础。对象也是如此,其成员函数被序列化进 vtable:
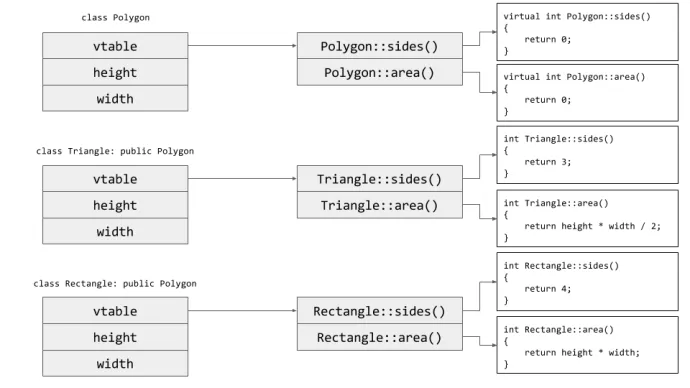
(还是 google image 搜出来的结果,来源见[3])
现在我们再想想整个软件产品,是不是感觉我们写的代码不外乎在做这样的事情:反序列化(Deserialize)信息,加工(Transform)之,然后再序列化(Serialize)传递给下一个调用者。函数如此,服务如此,应用程序也如此。我们管这个 Deserialize-Transform-Serialize 的过程叫 DTS。
其中加工的过程,往往又是一组新的 DTS。就像上面的 RPC 例子的一层层处理。就连 RPC 自己的内部的处理,也往往是向另一个数据源(比如数据库)发送序列化好的指令(如 SQL statement),然后数据源获取数据返回。
大部分时候,序列化反序列化自然而然发生,我们不需要关心,就像我们不用去亲自撸起袖子计算栈针,来保证函数调用的正常。
但,当我们要和文件,网络这些 IO 交互时,或者跨语言,跨进程传递数据时,我们需要进行合适的序列化和反序列化。
什么是好的序列化方案
这意味着要找到合适的序列化方案,或者说数据结构。好的结构应该是易于解析的,什么叫易于解析?数据是自描述的,并且我们清楚地知道数据的长度,比如 Erlang 的 external term format(ETF)中字符串的定义:




