正文
作为计算机视觉的一个任务,图片分类有着很长的历史,且有非常多好的模型。分类需要模型能把图像里与形状和物体相关的视觉信息拼接在一起,然后把这个图片分入一个类别。其他的计算机视觉的机器学习模型,诸如物体检查和图片分割等,则不仅对呈现的信息进行识别,还通过学习如何解读二维的空间,并把这两种理解融合起来,从而能判断出图片里分布的物体信息。对于字幕生成,有两个主要的问题:
在获取图片里的重要信息时,我们如何基于图像分类模型的成功结果?
我们的模型如何能学习去融合对于语言的理解和对于图片的理解?
我们可以利用已有的模型来帮助实现图片生成字幕。迁移学习让我们可以把从其他任务上训练出来的神经网络的数据变换应用到我们自己的数据上。在我们的这个场景里,VGG-16图片分类模型是把224 x224像素的图片作为输入,产生4096维度的特征向量表示,用于分类图片。
我们可以利用这些VGG-16模型生成的表示(也叫做图向量)来训练我们的模型。限于本文的篇幅,我们省略了VGG-16的架构,而是直接用已经计算出来的4096维的特征来加快训练的过程。
导入VGG图片特征和图片字幕是相当得简单直接:
def get_data(annotation_path, feature_path):
annotations = pd.read_table(annotation_path, sep=’\t’, header=None, names=[‘image’, ‘caption’])
return np.load(feature_path,’r’), annotations[‘caption’].values
现在我们已经有了图片的表示了,还需要我们的模型能学会把这些表示解码成能被理解的字幕。因为文字天生的序列特性,我们会利用一个RNN/LSTM网络里的循环特点(想了解更多,请参考这篇“理解LSTM网络”)。这些网络被训练来预测在给定的一系列前置词汇和图片表示的情况下的下一个词。
长短期记忆(LSTM)单元能让这个模型能更好地选择什么样的信息可以用于字幕词汇序列,什么需要记忆,什么信息需要忘掉。TensorFlow提供了一个封装的功能可以对于给定的输入和输出维度生成一个LSTM层。
为了把词汇能变化成适合LSTM的固定长度表示的输入,我们使用一个向量层来把词汇映射成256维的特征(也叫词向量)。词向量帮助我们把词汇表示成向量,同时相似的词向量在语义上也相似。想了解更多关于词向量如何获取不同词汇之间的关系,请看这篇《用深度学习来获取文本语义》。
在这个VGG-16图片分类器里,卷积层抽取出了4096维表示,然后送入最后的softmax层来做分类。因为LSTM单元需要的是256维的文本输入,我们需要把图片表示转化成目标字幕所需的这种表示。为了实现这个目标,我们需要加入另外一个向量层来学习把4096维的图片特征映射成256维的文本特征空间。
全合在一起,Show and Tell模型就大概像这个样子:
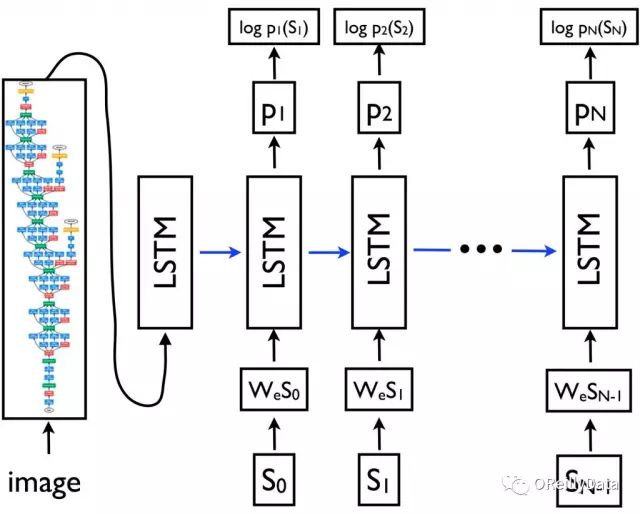
图3. 来源《Show and Tell:2015 MSCOCO图片字幕大赛所获得的经验教训》
图3中,{s0, s1, …, sN}表示我们试着去预测的字幕词汇,{wes0, wes1, …, wesN-1}是每个词的词向量。LSTM的输出{p1, p2, …, pN}是这个模型产生的句子里下一个词的概率分布。模型的训练目标是最小化对所有的词概率取对数后求和的负值。
def build_model(self):
# declaring the placeholders for our extracted image feature vectors, our caption, and our mask
# (describes how long our caption is with an array of 0/1 values of length `maxlen`
img = tf.placeholder(tf.float32, [self.batch_size, self.dim_in])
caption_placeholder = tf.placeholder(tf.int32, [self.batch_size, self.n_lstm_steps])
mask = tf.placeholder(tf.float32, [self.batch_size, self.n_lstm_steps])
# getting an initial LSTM embedding from our image_imbedding
image_embedding = tf.matmul(img, self.img_embedding) + self.img_embedding_bias
# setting initial state of our LSTM
state = self.lstm.zero_state(self.batch_size, dtype=tf.float32)










