正文
1)尽量不改变原表的字段名称
在做新表融合的时候,一开始只是简单归并表A 和 表B的表,因此很多字段名相同的字段做了重命名。
后来字段精简过程中,删除了很多重复字段,但是没有将重命名的字段改回来。
导致后期上线的过程中,不可避免地需要业务方进行重构字段名。
因此,新表设计的时候,除非必不得已,不要修改原表的字段名称!
2)新表的索引需要仔细斟酌
新表的索引不能简单照搬旧表,而是需要根据查询拆分分析后,重新设计。
尤其是一些字段的融合后,可能可以归并一些索引,或者设计一些更高性能的索引。
至此,分库分表的第一阶段告一段落。这一阶段所需时间,完全取决于具体业务,如果是一个历史包袱沉重的业务,那可能需要花费几个月甚至半年的时间才能完成。
这一阶段的完成质量非常重要,否则可能导致项目后期需要重建表结构、重新全量数据。
这里再次说明,对于微服务划分比较合理的服务,分库分表行为一般只需要关注存储架构的变化,或者只需要在个别应用上进行业务改造即可,一般不需要着重考虑“业务重构” 这一阶段。
对于任何分库分表的项目,存储架构的设计都是最核心的部分!
根据第一阶段整理的查询梳理结果,我们总结了这样的查询规律。
因此,我们设计了如下的整体架构,引入了数据库中间件、数据同步工具、搜索引擎(阿里云opensearch/ES)等。
下文的论述都是围绕这个架构来展开的。

1) MySQL分表存储
MySQL分表的维度是根据查询拆分分析的结果确定的。
我们发现pk1\pk2\pk3可以覆盖80%以上的主要查询。让这些查询根据分表键直接走MySQL数据库即可。
原则上一般最多维护一个分表的全量数据,因为过多的全量数据会造成存储的浪费、数据同步的额外开销、更多的不稳定性、不易扩展等问题。
但是由于本项目pk1和pk3的查询语句都对实时性有比较高的要求,因此,维护了pk1和pk3作为分表键的两份全量数据。
而pk2和pk1由于历史原因,存在一一对应关系,可以仅保留一份映射表即可,只存储pk1和pk2两个字段。
2)搜索平台索引存储
搜索平台索引,可以覆盖剩余20%的零散查询。
这些查询往往不是根据分表键进行的,或者是带有模糊查询的要求。
对于搜索平台来说,一般不存储全量数据(尤其是一些大varchar字段),只存储主键和查询需要的索引字段,搜索得到结果后,根据主键去mysql存储中拿到需要的记录。
当然,从后期实践结果来看,这里还是需要做一些权衡的:
这里特别提示,搜索引擎和数据库之间同步是必然存在延迟的。所以对于根据分表id查询的语句,尽量保证直接查询数据库,这样不会带来一致性问题的隐患。
3)数据同步
一般新表和旧表直接可以采用 数据同步 或者 双写的方式进行处理,两种方式有各自的优缺点。
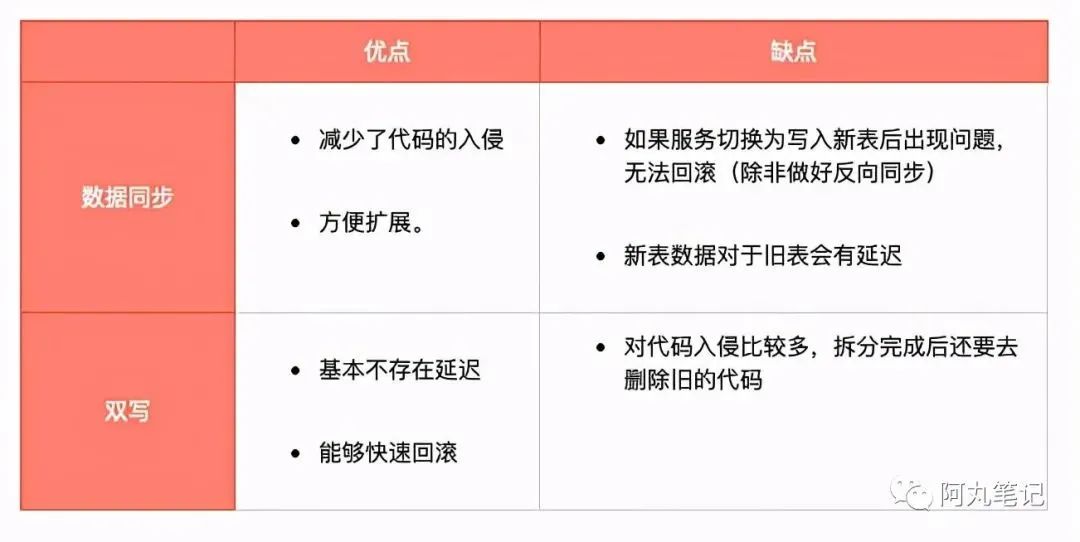
一般根据具体情况选择一种方式就行。
本次项目的具体同步关系见整体存储架构,包括了四个部分:
①旧表到新表全量主表的同步
一开始为了减少代码入侵、方便扩展,采用了数据同步的方式。而且由于业务过多,担心有未统计到的服务没有及时改造,所以数据同步能避免这些情况导致数据丢失。
但是在上线过程中发现,当延迟存在时,很多新写入的记录无法读到,对具体业务场景造成了比较严重的影响。(具体原因参考4.5.1的说明)
因此,为了满足应用对于实时性的要求,我们在数据同步的基础上,重新在3.0.0-SNAPSHOT版本中改造成了双写的形式。
②新表全量主表到全量副表的同步
③新表全量主表到映射表到同步
④新表全量主表到搜索引擎数据源的同步
②、③、④都是从新表全量主表到其他数据源的数据同步,因为没有强实时性的要求,因此,为了方便扩展,全部采用了数据同步的方式,没有进行更多的多写操作。
在申请MySQL存储和搜索平台索引资源前,需要进行容量评估,包括存储容量和性能指标。
具体线上流量评估可以通过监控系统查看QPS,存储容量可以简单认为是线上各个表存储容量的和。
但是在全量同步过程中,我们发现需要的实际容量的需求会大于预估,具体可以看3.4.6的说明。
具体性能压测过程就不再赘述。
从上文可以看到,在本次项目中,存在大量的业务改造,属于异构迁移。
从过去的一些分库分表项目来说,大多是同构/对等拆分,因此不会存在很多复杂逻辑,所以对于数据迁移的校验往往比较忽视。
在完全对等迁移的情况下,一般确实比较少出现问题。
但是,类似这样有比较多改造的异构迁移,校验绝对是重中之重!!
因此,必须对数据同步的结果做校验,保证业务逻辑改造正确、数据同步一致性正确。这一点非常非常重要。





