正文
jstat -gcutil [pid]

还可以通过vmstat,通过观察内核状态的上下文切换(cs)次数,来判断是否是上下文切换造成的cpu繁忙。
vmstat 1 5

此外,有时候可能会由jit引起一些cpu飚高的情形,如大量方法编译等。这里可以使用-XX:+PrintCompilation这个参数输出jit编译情况,以排查jit编译引起的cpu问题。
内存分析
对Java应用来说,内存主要是由堆外内存和堆内内存组成。
1. 堆外内存堆外内存主要是JNI、Deflater/Inflater、DirectByteBuffer(nio中会用到)使用的。对于这种堆外内存的分析,还是需要先通过vmstat、sar、top、pidstat等查看swap和物理内存的消耗状况再做判断的。此外,对于JNI、Deflater这种调用可以通过Google-preftools来追踪资源使用状况。
2. 堆内内存此部分内存为Java应用主要的内存区域。通常与这部分内存性能相关的有:
-
创建的对象:这个是存储在堆中的,需要控制好对象的数量和大小,尤其是大的对象很容易进入老年代
-
全局集合:全局集合通常是生命周期比较长的,因此需要特别注意全局集合的使用
-
缓存:缓存选用的数据结构不同,会很大程序影响内存的大小和gc
-
ClassLoader:主要是动态加载类容易造成永久代内存不足
-
多线程:线程分配会占用本地内存,过多的线程也会造成内存不足
以上使用不当很容易造成:
排查堆内存问题的常用工具是jmap,是jdk自带的。一些常用用法如下:
-
查看jvm内存使用状况:jmap -heap
-
查看jvm内存存活的对象:jmap -histo:live
-
把heap里所有对象都dump下来,无论对象是死是活:jmap -dump:format=b,file=xxx.hprof
-
先做一次full GC,再dump,只包含仍然存活的对象信息:jmap -dump:format=b,live,file=xxx.hprof
此外,不管是使用jmap还是在OOM时产生的dump文件,可以使用Eclipse的MAT(MEMORY ANALYZER TOOL)来分析,可以看到具体的堆栈和内存中对象的信息。当然jdk自带的jhat也能够查看dump文件,会启动web端口供开发者使用浏览器浏览堆内对象的信息。

IO分析
通常与应用性能相关的包括:文件IO和网络IO。
1. 文件IO可以使用系统工具pidstat、iostat、vmstat来查看io的状况。这里可以看一张使用vmstat的结果图。
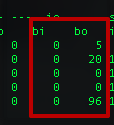
这里主要注意bi和bo这两个值,分别表示块设备每秒接收的块数量和块设备每秒发送的块数量,由此可以判定io繁忙状况。进一步的可以通过使用strace工具定位对文件io的系统调用。通常,造成文件io性能差的原因不外乎:
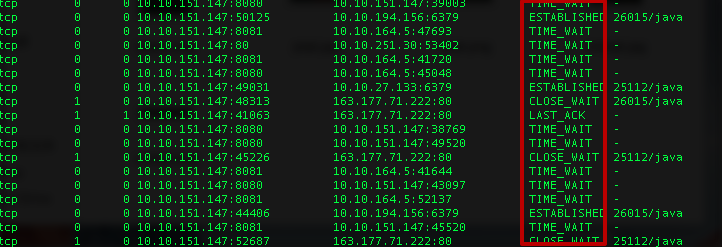
1. 网络IO查看网络io状况,一般使用的是netstat工具。可以查看所有连接的状况、数目、端口信息等。例如:当time_wait或者close_wait连接过多时,会影响应用的相应速度。
netstat -anp
此外,还可以使用tcpdump来具体分析网络io的数据。当然,tcpdump出的文件直接打开是一堆二进制的数据,可以使用wireshark阅读具体的连接以及其中数据的内容。
tcpdump -i eth0 -w tmp.cap -tnn dst port 8080 #监听8080端口的网络请求并打印日志到tmp.cap中
还可以通过查看/proc/interrupts来获取当前系统使用的中断的情况。
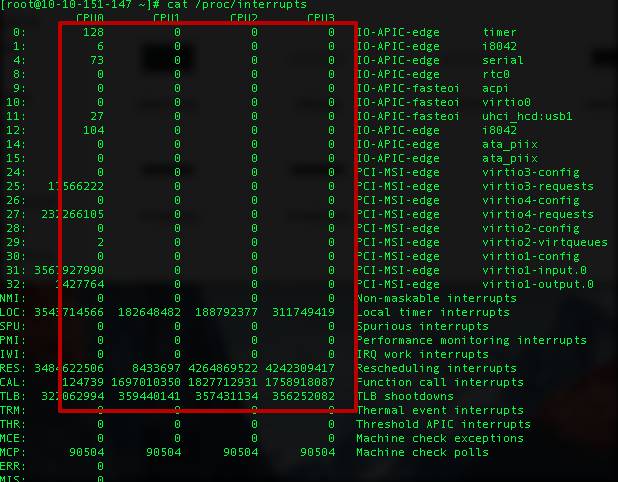
各个列依次是:
irq的序号, 在各自cpu上发生中断的次数,可编程中断控制器,设备名称(request_irq的dev_name字段)
通过查看网卡设备的终端情况可以判断网络io的状况。
其他分析工具
上面分别针对CPU、内存以及IO讲了一些系统/JDK自带的分析工具。除此之外,还有一些综合分析工具或者框架可以更加方便我们对Java应用性能的排查、分析、定位等。









