正文

两条记录,说明Oracle认为这两条SQL是不同。
如果使用绑定变量:
select * from t1 where id = :1;
每次将不同的参数值带入:1中,语义和上面两条相同,但对应哈希值可是1个,换句话说,解析树和执行计划是可以重用的。
使用绑定变量除了以上可以避免硬解析的好处之外,还有其自身的缺陷,就是这种纯绑定变量的使用适合于绑定变量列值比较均匀分布的情况,如果绑定变量列值有一些非均匀分布的特殊值,就可能会造成非高效的执行计划被选择。
如下是测试表:

其中name列是非唯一索引,NAME是A的有100000条记录,NAME是B的有1条记录,值分布是不均匀的,上一篇文章中我们使用如下两条SQL做实验。
select * from t1 where name = 'A';
select * from t1 where name = 'B';
其中第一条使用的是全表扫描,第二条使用了索引范围扫描,过程和原因上篇文章中有叙述,此处就不再赘述。
如上SQL使用的是字面值或常量值作为检索条件,接下来我们使用绑定变量的方式来执行SQL,为了更好地说明,此处我们先关闭绑定变量窥探(默认情况下,是开启的状态),他是什么我们稍后再说。

首先A为条件。

显示使用了全表扫描。
再以B为条件。

发现仍旧是全表扫描,我们之前知道B值记录只有一条,应该使用索引范围扫描,而且这两个SQL执行计划中Rows、Bytes和Cost值完全一致。之所以是这样,是因为这儿用的未开启绑定变量窥探情况下的绑定变量,Oracle不知道绑定变量值是什么,只能采用常规的计算Cardinality方式,参考dbsnake的书,CBO用来估算Cardinality的公式如下:
Computed Cardinality = Original Cardinality * Selectivity
Selectivity = 1 / NUM_DISTINCT
收集统计信息后,计算如下:
Computed Cardinality = 100001 * 1 / 2
约等于50001。因此无论是A还是B值,CBO认为结果集都是50001,占据一半的表记录总量,自然会选择全表扫描,而不是索引扫描。
下面我们说说绑定变量窥探,是9i引入的一个新特性,其作用就是会查看SQL谓词的值,以便生成最佳的执行计划,其受隐藏参数控制,默认为开启。

我们在绑定变量窥探开启的情况下,再次执行上述两条SQL(区别仅是不用explain plan,使用dbms_xplan.display_cursor可以得到更详细的信息),首先A为条件的SQL。
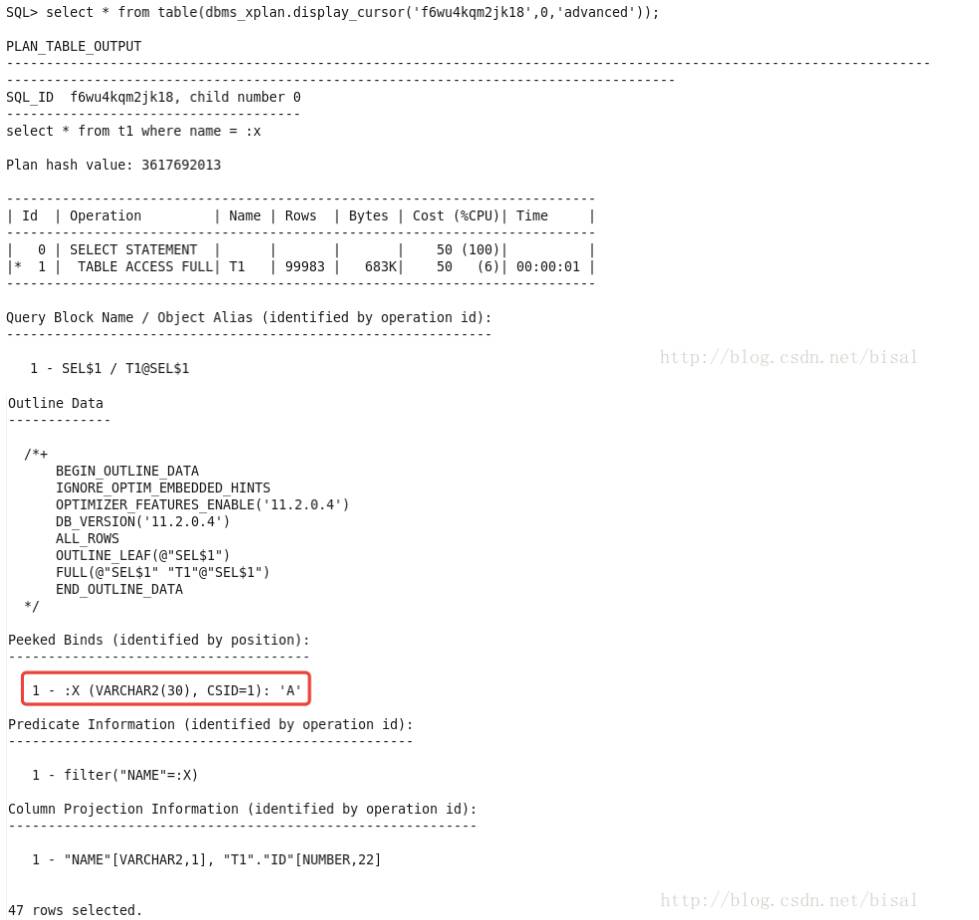
这次使用了全表扫描,窥探了绑定变量值是A。
再使用以B为条件的SQL:
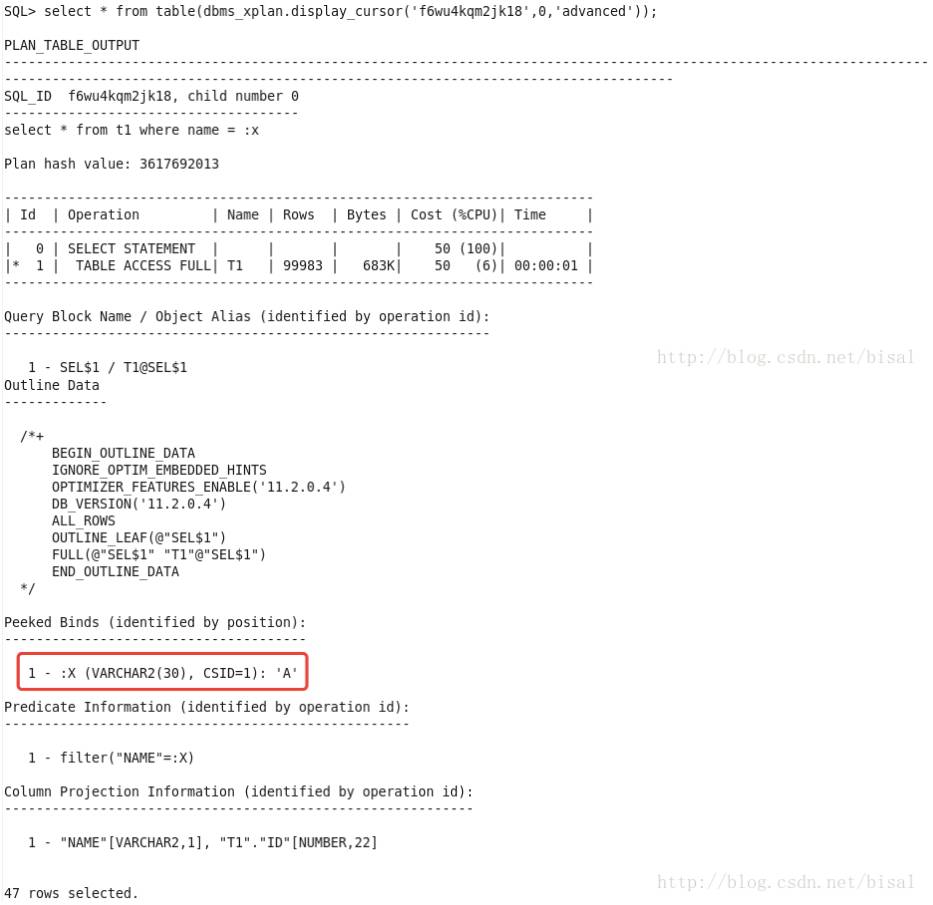
仍旧采用了全表扫描,绑定变量窥探值是A,因为只有第一次硬解析的时候才会窥探绑定变量值,接下来执行都会使用第一次窥探的绑定变量值。B的记录数只有1条,1/100001的选择率,显然索引范围扫描更合适。
为了让SQL重新窥探绑定变量值,我们刷新共享池:
alter system flush shared_pool;
此时清空了所有之前保存在共享池中的信息,包括执行计划,因此再次执行就会是硬解析,这次我们先使用B为条件。
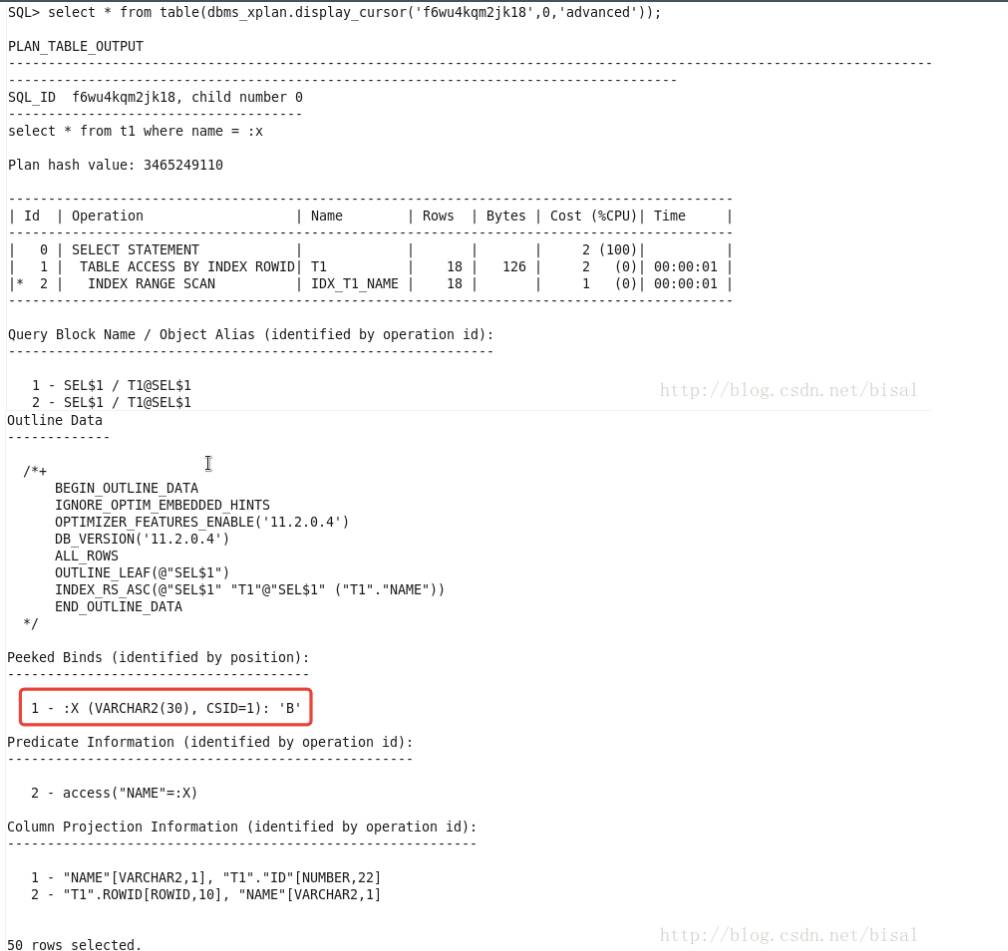
可见窥探了绑定变量值是B,因为可以知道这个绑定变量:x的具体值,根据其值分布特点,选择了索引范围扫描。
再用A为查询条件:

此时仍旧窥探绑定变量值为B,因此还会选择索引范围扫描,即使A值应该选择全表扫描更高效。
总结:
绑定变量窥探会于第一次硬解析的时候,“窥探“绑定变量的值,进而根据该值的信息,辅助选择更加准确的执行计划,就像上述示例中第一次执行A为条件的SQL,知道A值占比重接近全表数据量,因此选择了全表扫描。但若绑定变量列分布不均匀,则绑定变量窥探的副作用会很明显,第二次以后的每次执行,无论绑定变量列值是什么,都会仅使用第一次硬解析窥探的参数值,这就有可能选择错误的执行计划,就像上面这个实验中说明的,第二次使用B为条件的SQL,除非再次硬解析,否则这种情况不会改变。
简而言之,数据分布不均匀的列使用绑定变量,尤其在11g之前,受绑定变量窥探的影响,可能会造成一些特殊值作为检索条件选择错误的执行计划。11g的时候则推出了ACS(自适应游标),缓解了这个问题。
以上主要介绍了11g之前使用绑定变量和非绑定变量在解析效率方面的区别,以及绑定变量在绑定变量窥探开启的情况下副作用的效果。虽然OLTP系统,建议高并发的SQL使用绑定变量,避免硬解析,可不是使用绑定变量就一定都好,尤其是11g之前,要充分了解绑定变量窥探副作用的原因,根据绑定变量列值真实分布情况,才能综合判断绑定变量的使用正确。
3、查看绑定变量值的几种方法
上一章我们了解了,绑定变量实际是一些占位符,可以让仅查询条件不同的SQL语句可以重用解析树和执行计划,避免硬解析。绑定变量窥探则是第一次执行SQL硬解析时,会窥探使用的绑定变量值,根据该值的分布特征,选择更合适的执行计划,副作用就是如果绑定变量列值分布不均匀,由于只有第一次硬解析才会窥探,所以可能接下来的SQL执行会选择错误的执行计划。
有时可能我们需要查看某条SQL使用了什么绑定变量值,导致执行计划未用我们认为最佳的一种。以下就介绍一些常用的查看绑定变量值的方法。
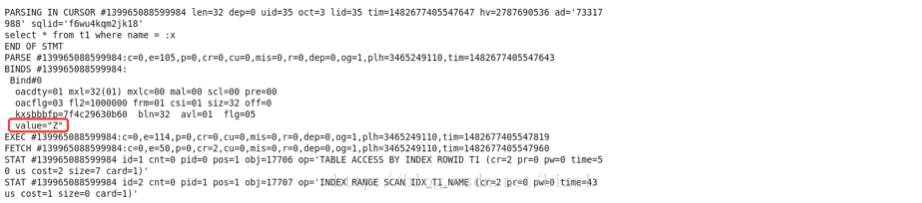
使用level=4的10046事件,查看生成的trace文件。

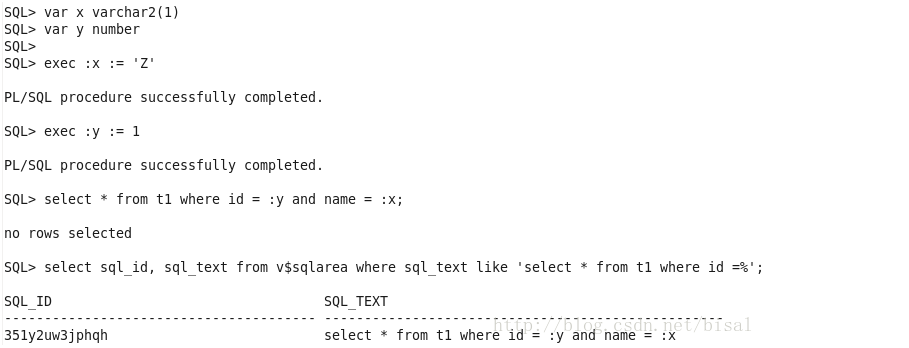
可以看出绑定变量值是’Z’。
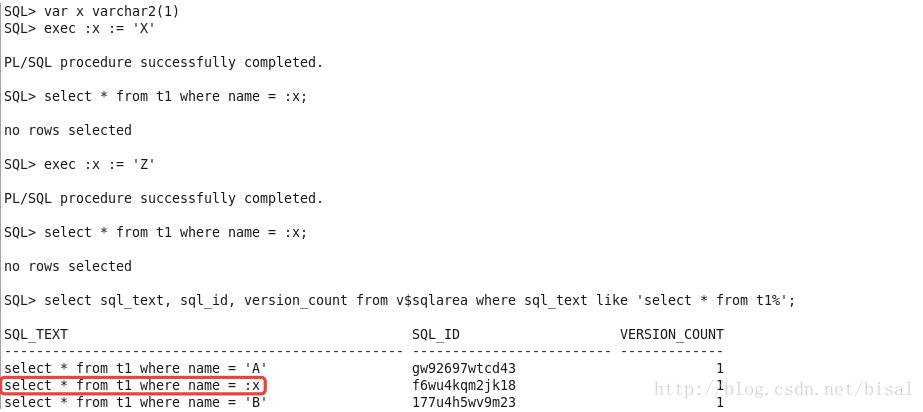
首先找出SQL对应的sql_id: