正文
所以如果你突然发现有一些机器要下线了又不在你的计划之内这是非常头疼的。我们发现一些过保之后的旧机器经常出现磁盘损坏,或者内存 CPU 的故障等等各种问题。
第三要考虑各种机房的因素
,比如机架、电源、网络。我做 Hadoop 运维这一块才意识到这些问题,比如:你的机器上架在什么位置,是不是同一个机架,是集中上架还是分散到各个交换机下,都是需要考虑的问题。
电源问题,有时候机房同事会跟我们抱怨,说 Hadoop 机架又超电了,所以我们在这些问题上需要提前规划,这是非常必要的。

上图指规范用户的使用,用户如果不告诉他如何规范用 Hadoop 服务的话,基本上各种用法都有可能,所以我们在这 4 个方面都要做这样的规划。
第一点是 HDFS 用户我们是根据各个业务、各个部门进行分配,而不是分配一些个人用户,这样比较多比较难以管理。
一般来说,一个部门可能会有一到三个用户,然后我们需要管理他们的使用限额、配额,包括存储和计算,存储方面主要是 Name quota,是说文件数不能多,Space quota 是不能超过使用的空间。
所以 Name quota 是为了规范用户的使用,希望小文件不要太多,如果他们 Space quota 每年达到上线,但是 Name quota 达到了,就会把小文件合并成大文件,需要用户的主动性。
第二点是如何配置数据权限,在 Hadoop1.0 的时代,如果 A 用户想访问 B 用户数据,这个是非常麻烦的事情,我们可能一般来说会通过开放一个组的权限去设置,在 Hadoop2.3 就进入 ACL 的功能,可以让你针对单个目录配置单个用户的访问权限。
这个我们现在访问是通过 HDFS ACL 做的,虽然它有可能对 Name quota 造成一些压力,但是只要合理配置,不需要大批量的这个应该是可以避免的。最后计算资源管理我们用的是 Fair Scheduler,这个也是 CDH 默认的调度器。
2.2 Hadoop工作平台
Hadoop 工作平台,前面有规范用户的使用,以及我们对集群的规划之后,我们需要把一些机器的信息、集群的信息管理起来,这时候有了这样的东西。

右边红色的底下一层是后台管理数据库 CMDB,这个主要是包括集群、服务器、配置信息以及用户信息,所有的跟我们公司内部 Hadoop 集群相关的管理信息都是存在 CMDB 中,并提供 API 给上面4个模块使用,包括运维管理,就是所有运维操作都要平台化,而不是运维人员在登到命令行中操作。
这样有可能误操作我们还不知道,如果平台化有这样的好处,减少误操作的几率,降低运维的门槛,并且有一个记录谁操作什么样的事情,是否运维操作是否成功,以及可以察看一下 LOG。我们脚本主要以 Ansible 为主,这个工具非常适合管理 Hadoop 集群。
第二块是数据管理,用户可以直接上我们平台查看,而不需要输入 Hive 语句看那些表。公共库管理是在 Hive 用到 UDF,其实各位业务部门都会用到这个 UDF,大家我们希望放在统一进行管理,这样可以节省重复的人力劳动,并且质量上也比较容易把控。
QoS 这个模块指的是对 Hadoop 服务质量监控,我们平时经常会说到这样的反馈,“集群是不是又变慢了”,“我的任务又跑不了了是不是集群有问题?”
之前我们可能查看各种监控数据或者 LOG,最后找到一个原因,有这个 QoS 之后,我们的目的是希望直接打开 QoS,不管是运维人员还是使用方,都可以直接的看到当时的状况,如果有任何异常需要直接反映在这个上面,这是我们的目的。
3、遇到的困难及应对措施

下面讲一下我们遇到的一些坑,这些坑是大多数是 bug,以及我们做的应对方案。大概分为两类,一类是跟机器、网络或者系统相关的,另一类是 Hadoop 本身的 Bug。

第一个问题是伪高可用。
HDFS 本身是配机架的信息,一个文件或者一个文件快是有三份副本存储,其中两份存储在一个机架下,另外一份是存在另外一个机架下,这种配置其实是一个高可用的。
但是有一个问题,我们在实际当中发现,交换机可能没有多高可用,也就是说一台交换机底下有可能连接很多个机架,这时候交换机高可用就挂了,就成为一个单点,有可能同时一堆机架都是出现不可用的情况。
为了避免这个问题,首先把交换机变成高可用就可以了。我们可能不是那么容易变的,不一定能够控制得了或者变更起来周期比较长,在这样基础上解决方案是,配置机架信息的时候不再用原本的传统的机架号,而是采用交换机的比如 ID,这样相当于欺骗 NameNode ,告诉它这个机器机架号是这样的。
其实这个并不是机架号而是交换机号,这样做在一个大集群里是没有什么问题的,把这个机架范围变大了之后,可以容忍整个交换机的 bug,不会出现任何 missing blocks,这是我们想出的一个替代方案。
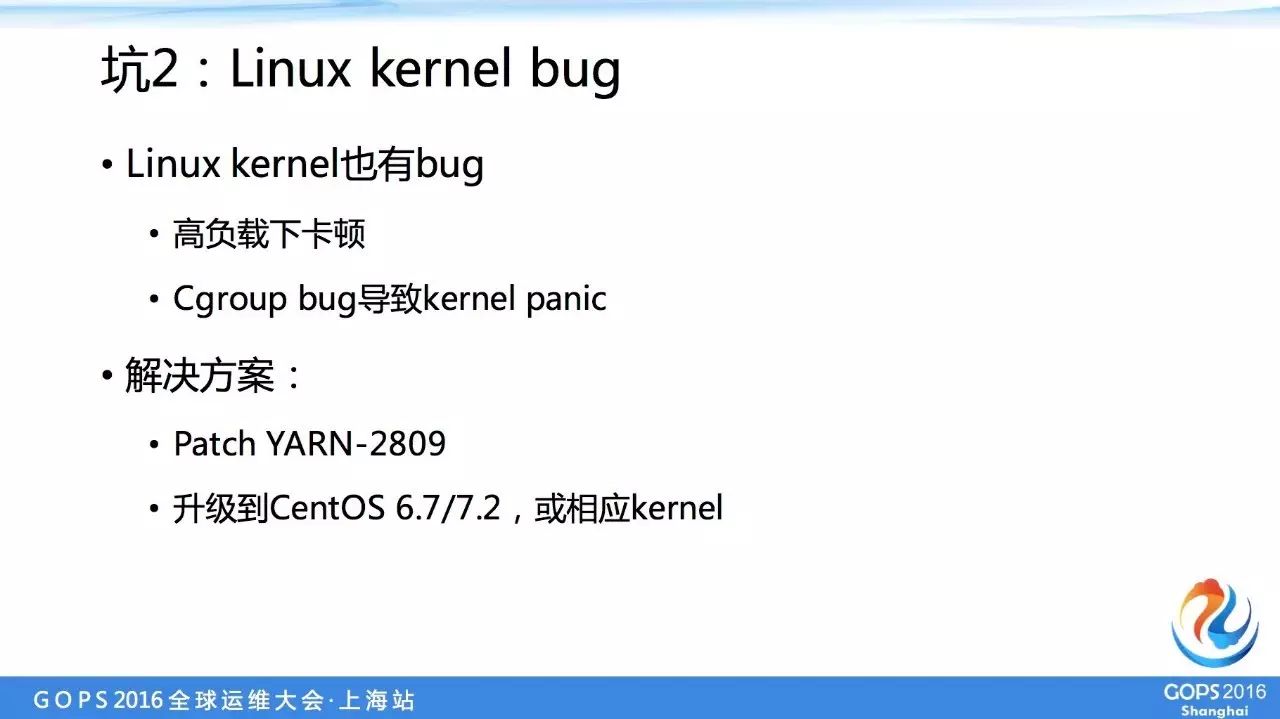
第二个问题 Linux kernel bug 。






