正文
人工智能能在国际象棋上能打败人类,跟现在能在围棋上打败人类,是两种概念,看个动图就知道了~
国际象棋的复杂程度:
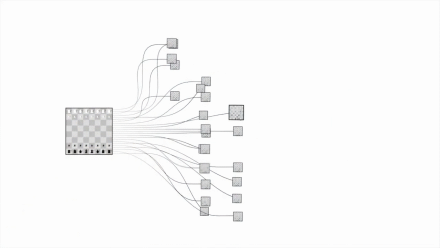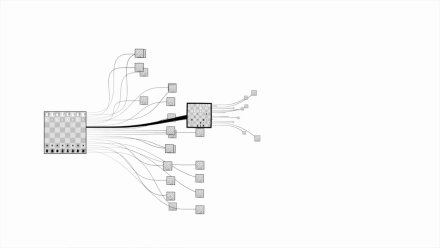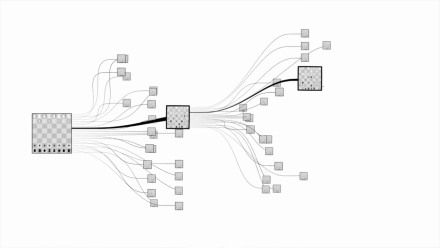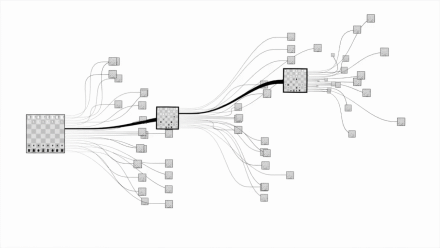
围棋的复杂程度:
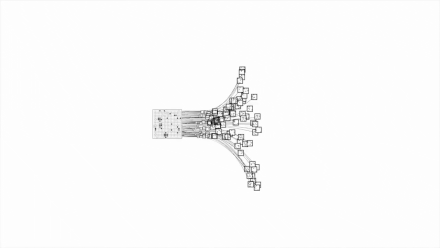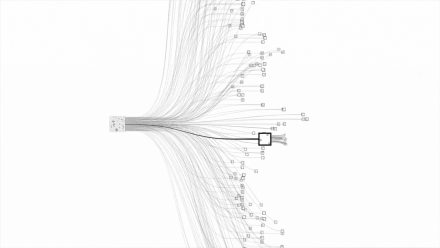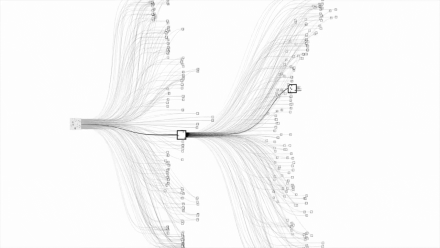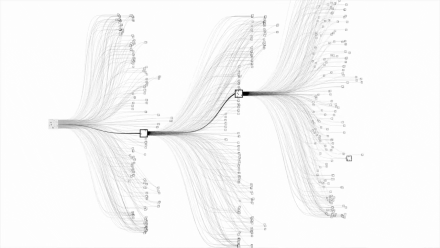
由于围棋的变数实在是太多,不通过人一样 “ 逻辑思考 ”,几乎没法暴力穷举,或者说穷举起来会很耗费资源,所以一直都没解决这个问题。
那么 AlphaGo 是怎么出来的呢?
这跟 Google 之前收购的一个叫做 Deepmind 的公司有关。

这个公司是研究 Deep machine learning (机器深度学习)方向的公司,本来就是行业里的佼佼者。
被 Google 收购之后,采用了 Google 家的 TensorFlow 系统进行开发,是把 N 维基于数据流图的计算。
通过这个,可以把很复杂的数据结构化的系统分析运算,这样,就可以把数据的处理只能话,给机器装了个 “ 有逻辑的脑子 ”!机器,可以像人脑一样有类似 “ 神经元突出联接处理问题 ” 的能力进行思考了!
TensorFlow 为了演示开放的的 “ 神经网络游乐场 ”:
而且这个系统时可以进行分布式计算的,一个 CPU 也可用,把成千上万的 CPU 连在一起的时候也可以用,只要核心足够多,系统的学习能力是很可怕的!
更叼的是,Google 自己还开发了个 “ TPU ”(Tensor Processing Unit )专门对于 TensorFlow 算法进行优化 。。。
现在硬件和开发环境都有了,就差开发了。
一开始,关于围棋大家是使用卷积神经网络进行运算的,也就是说把大量棋谱拿过来,统计 “ 到了某一步的时候,把棋下在某一步,以后赢的概率比较高 ”,这样,机器不需要很明白后面的路数,却能找到现在这步把棋下在哪里是最优解!
Google 给出的图解,红圈是最优解:

但,这是不足以让 Alpha 打败人类智慧佼佼者的,最多也就打败围棋 5、6 段的棋手 。。。
这个时候,一个很关键的人出现了,就是上面 Master 自称的 “ 黄博士 ” —— 黄士杰。

前面说到了因为为其太复杂,穷举起来很无力,所以人们一般采用蒙特卡罗模拟,不计算所有的事件,而是对事件进行抽样统计,进行概率分析,可以很有效的分析复杂事件的趋势(说出来你可能不行,这玩意之前是为了搞 “ 核事业 ” 兴起的)。。。
蒙特卡罗模拟
黄博士基于这个,采用了蒙特卡罗模搜索树进行运算。。。
蒙特卡罗模搜索树
之前是通过输入 “ 自然棋谱 ” 让机器学习,也就是让机器对已经有的棋谱进行抽样学习,这样就很难有飞跃性的提升。
这次呢,是让机器既当黑子又当白子,两方都不会下棋,就瞎落子,最后也能分出胜负。。。
就这样,通过不停地傻逼对局,不停地抽样统计分析概率,不会下棋的傻逼系统就会逐渐知道到了哪一步,把子下在那个地方以后赢的几率会高!
就这样不停地自己自学成才,最后变成了天下第一的 Master!










