正文
司机和汽车来分享控制权,驾驶员在某些预设环境下可以不操作汽车,即手脚同时离开控制,但驾驶员仍需要随时待命,对驾驶安全负责,并随时准备在短时间内接管汽车驾驶权。比如结合了 ACC 和 LKS 形成的跟车功能。Level 2 的核心不在于要有两个以上的功能,而在于驾驶员可以不再作为主要操作者。Tesla 推送的 autopilot 也是 Level 2 的功能。
(4)Level 3:有条件自动化。
在有限情况下实现自动控制,比如在预设的路段(如高速和人流较少的城市路段),汽车自动驾驶可以完全负责整个车辆的操控,但是当遇到紧急情况,驾驶员仍需要在某些时候接管汽车,但有足够的预警时间,如即将进入修路的路段(Road work ahead)。Level 3 将解放驾驶员,即对行车安全不再负责,不必监视道路状况。
(5)Level 4:完全自动化(无人驾驶),无须司机或乘客的干预。
在无须人协助的情况下由出发地驶向目的地。仅需起点和终点信息,汽车将全程负责行车安全,并完全不依赖驾驶员干涉。行车时可以没有人乘坐(如空车货运)。
另一个对自动驾驶的分级来自美国机动工程师协会(SAE),其定义自动驾驶技术共分为 0~5 级。SAE 的定义在自动驾驶 0~3 级与 NHTSA 一致,分别强调的是无自动化、驾驶支持、部分自动化与条件下的自动化。
唯一的区别在于 SAE 对 NHTSA 的完全自动化进行了进一步细分,强调了行车对环境与道路的要求。SAE-Level4 下的自动驾驶需要在特定的道路条件下进行,比如封闭的园区或者固定的行车线路等,可以说是面向特定场景下的高度自动化驾驶。SAE-Level5 则对行车环境不加限制,可以自动地应对各种复杂的车辆、新人和道路环境。
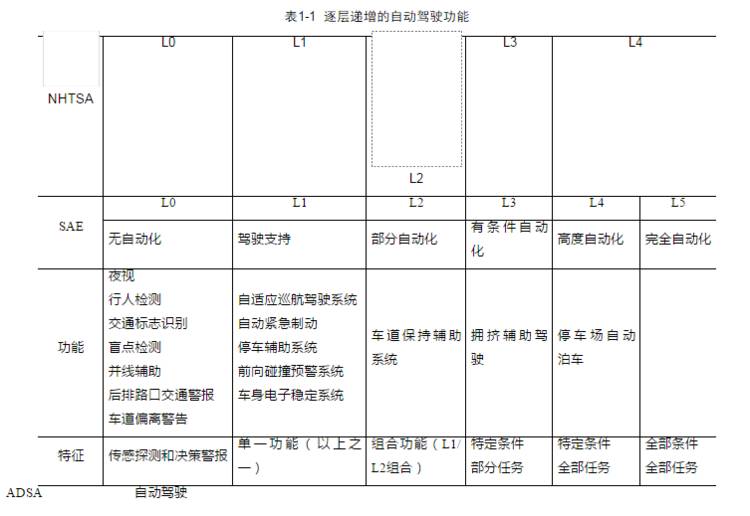
综上所述,不同 Level 所实现的自动驾驶功能也是逐层递增的,ADAS(Advanced Driving Assistant System)即高级驾驶辅助系统,属于自动驾驶 0~2 级。如表 1-1 所示,L0 中实现的功能仅能够进行传感探测和决策报警,比如夜视系统、交通标识识别、行人检测、车道偏离警告等。
L1 实现单一控制类功能,如支持主动紧急制动、自适应巡航控制系统等,只要实现其中之一就可达到 L1。
L2 实现了多种控制类功能,如具有 AEB 和 LKA 等功能的车辆。
L3 实现了特定条件下的自动驾驶,当超出特定条件时将由人类驾驶员接管驾驶。
SAE 中的 L4 是指在特定条件下的无人驾驶,如封闭园区固定线路的无人驾驶等,例如百度在乌镇景区运营的无人驾驶服务。
而 SAE 中的 L5 就是终极目标,完全无人驾驶。无人驾驶就是自动驾驶的最高级,它是自动驾驶的最终形态。
全自动无人车可能比半自动驾驶汽车更安全,因为其可以在车辆行驶时排除人为错误和不明智的判断。例如,弗吉尼亚理工大学交通学院的调查表明,“L3 级自动驾驶车辆的司机回应接管车辆的请求平均需要 17 秒,而在这个时间内,一辆时速 65 英里(105 千米)的汽车已经开出 1621 英尺(494 米)——超过 5 个足球场的长度。”百度的工程师也发现了类似的结果。
司机从看到路面物体到踩刹车需要 1.2 秒,远远长于车载计算机所用的 0.2 秒。这一时间差意味着,如果汽车时速是 120 千米(75 英里),等到司机停车时, 车子已经开出了 40 米(44 码),而如果是车载计算机做判断,则开出的距离只有 6.7 米(7 码)。在很多事故中,这一差距将决定乘客的生死。由此可见,站在自动驾驶最高级的无人驾驶才是汽车行业未来发展的“终极目标”。
无人驾驶系统是一个复杂的系统,如图所示,系统主要由三部分组成:算法端、Client 端和云端。其中算法端包括面向传感、感知和决策等关键步骤的算法;Client 端包括机器人操作系统及硬件平台;云端包括数据存储、模拟、高精度地图绘制及深度学习模型训练。
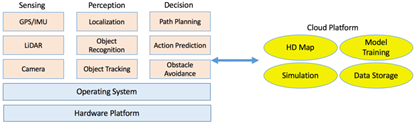
算法端从传感器原始数据中提取有意义的信息以了解周遭的环境情况,并根据环境变化做出决策。Client 端融合多种算法以满足实时性与可靠性的要求。举例来说,传感器以 60Hz 的速度产生原始数据,Client 端需要保证最长的流水线处理周期也能在 16ms 内完成。云平台为无人车提供离线计算及存储功能。通过云平台,我们能够测试新的算法、更新高精度地图并训练更加有效的识别、追踪和决策模型。
算法系统由几部分组成:第一,传感,并从传感器原始数据中提取有意义信息;第二,感知,以定位无人车所在位置及感知现在所处的环境;第三,决策,以便可靠、安全地抵达目的地。
通常来说,一辆无人车装备有许多不同类型的主传感器。每一种类型的传感器各自有不同的优劣,因此,来自不同传感器的传感数据应该有效地进行融合。现在无人驾驶中普遍使用的传感器包括以下几种。
(1)GPS/IMU:
GPS/IMU 传感系统通过高达 200 Hz 频率的全球定位和惯性更新数据,以帮助无人车完成自我定位。GPS 是一个相对准确的定位用传感器,但是它的更新频率过低,仅有 10Hz,不足以提供足够实时的位置更新。IMU 的准确度随着时间降低,因此在长时间距离内并不能保证位置更新的准确性;但是,它有着 GPS 所欠缺的实时性,IMU 的更新频率可以达到 200Hz 或者更高。通过整合 GPS 与 IMU,我们可以为车辆定位提供既准确又足够实时的位置更新。
(2)LIDAR:
激光雷达可被用来绘制地图、定位及避障。雷达的准确率非常高,因此在无人车设计中雷达通常被作为主传感器使用。激光雷达是以激光为光源,通过探测激光与被探测物相互作用的光波信号来完成遥感测量。激光雷达可以用来产生高精度地图,并针对高精地图完成移动车辆的定位,以及满足避障的要求。以 Velodyne 64- 束激光雷达为例,它可以完成 10Hz 旋转并且每秒可达到 130 万次读数。
(3)摄像头:
摄像头被广泛使用在物体识别及物体追踪等场景中,在车道线检测、交通灯侦测、人行道检测中都以摄像头为主要解决方案。为了加强安全性,现有的无人车实现通常在车身周围使用至少八个摄像头,分别从前、后、左、右四个维度完成物体发现、识别、追踪等任务。这些摄像头通常以 60Hz 的频率工作,当多个摄像头同时工作时,将产生高达 1.8GB 每秒的巨额数据量。
(4)雷达和声呐:
雷达把电磁波的能量发射至空间中某一方向,处在此方向上的物体反射该电磁波,雷达通过接收此反射波,以提取该物体的某些有关信息,包括目标物体至雷达的距离、距离变化率或径向速度、方位、高度等。雷达和声呐系统是避障的最后一道保障。雷达和声呐产生的数据用来表示在车的前进方向上最近障碍物的距离。一旦系统检测到前方不远有障碍物出现,则有极大的相撞危险,无人车会启动紧急刹车以完成避障。因此,雷达和声呐系统产生的数据不需要过多的处理,通常可直接被控制处理器采用,并不需要主计算流水线的介入,因此可实现转向、刹车或预张紧安全带等紧急功能。
在获得传感信息之后,数据将被推送至感知子系统以充分了解无人车所处的周遭环境。在这里感知子系统主要做的是三件事:定位、物体识别与追踪。
1)定位
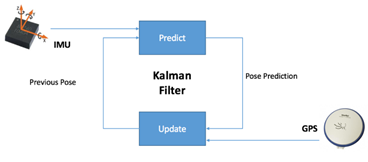
GPS 以较低的更新频率提供相对准确的位置信息,IMU 则以较高的更新频率提供准确性偏低的位置信息。我们可以使用卡尔曼滤波整合两类数据各自的优势,合并提供准确且实时的位置信息更新。如图 1-4 所示,IMU 每 5ms 更新一次,但是期间误差不断累积精度不断降低。所幸的是,每 100ms,我们可以得到一次 GPS 数据更新,以帮助我们校正 IMU 积累的误差。因此,我们最终可以获得实时并准确的位置信息。然而,我们不能仅仅依靠这样的数据组合完成定位工作。原因有三:其一,这样的定位精度仅在一米之内;其二,GPS 信号有着天然的多路径问题将引入噪声干扰;其三,GPS 必须在非封闭的环境下工作,因此在诸如隧道等场景中 GPS 都不适用。
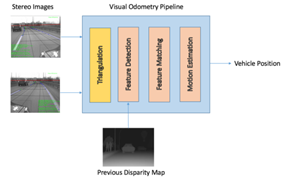
因此作为补充方案,摄像头也被用于定位。简化来说,如图 1-5 所示,基于视觉的定位由三个基本步骤组成:
① 通过对立体图像的三角剖分,首先获得视差图用以计算每个点的深度信息;
② 通过匹配连续立体图像帧之间的显著特征,可以通过不同帧之间的特征建立相关性,并由此估计这两帧之间的运动情况;
③ 通过比较捕捉到的显著特征和已知地图上的点计算车辆的当前位置。然而,基于视觉的定位方法对照明条件非常敏感,因此其使用受限且可靠性有限。
因此,借助于大量粒子滤波的激光雷达通常被用作车辆定位的主传感器。由激光雷达产生的点云对环境进行了“形状化描述”,但并不足以区分各自不同的点。通过粒子滤波,系统可将已知地图与观测到的具体形状进行比较以减少位置的不确定性。
为了在地图中定位运动的车辆,可以使用粒子滤波的方法关联已知地图和激光雷达测量过程。粒子滤波可以在 10cm 的精度内达到实时定位的效果,在城市的复杂环境中尤为有效。然而,激光雷达也有其固有的缺点:如果空气中有悬浮的颗粒(比如雨滴或者灰尘),那么测量结果将受到极大的扰动。因此,如图 1-6 所示,我们需要利用多种传感器融合技术进行多类型传感数据融合,处理以整合所有传感器的优点,完成可靠并精准的定位。










