正文
以上准备可能会花上你一到两天的时间,但磨刀不误砍柴工,我们也差不多可以开始我们的征程了。
3.1 BCE Loss 训练 和 F2-Score 阈值调优
上面提到,这次比赛问题是 Multi-Label(多标签)分类问题,评价指标是 F2 Score,但 F2 Score 并不是可以直接优化的值,所以我们采取的方法是:
1. 每个输出接 Sigmoid 层,分别预测每个类的概率,使用 Binary Cross Entropy Loss 优化。这其实是多标签分类问题的常见套路,本质是独立地对每个类做二分类学习。虽说不同类之间可能存在相互依赖,但我们假设这些依赖可以通过共享底层参数来间接实现。
2. 在训练上述二分类任务时,由于正负样本数目不均衡,我们并不能直接拿 p = 0.5 作为二分类的阈值进行预测,而需要为每个类搜索一个合适的阈值,使得整体的 F2-Score 最大。具体来说,我们采取了讨论区放出的一个方案,贪婪地对每个类的阈值进行暴力搜索,逻辑如下:
# 假装是 Python 的伪代码
给定 17 个类的阈值构成的阈值向量,每个元素初始化为 0.2
for 第 i=0 到第 i=16 的类:
固定其他类的阈值不动
在第i个类上分别尝试 0.01, 0.02, 0.03, ... 0.99 总共 100 个候选
每个候选构成一个新的阈值向量,新的阈值向量可以在样本集上获得一个 F2
找到 100 个 F2 中最高的,取其对应的候选阈值,就作为第i个类的阈值
这样就把第 i 个位置的 0.2 改成了一个新的值,接着贪婪地处理下一个类
这肯定不是最优的方案,但却已经足够好。虽然后期我们优化了讨论区的代码使用 GPU 加速计算,并尝试了诸如随机初始值、随机优化顺序然后多次随机取最好,步长大小调优,进化计算搜索等方法,但都因为提交次数限制没来得及测试。
不过要注意的是,虽然我们以 BCE Loss 为训练目标,但实际上 BCE Loss 变低,F2-Score 却未必变高,可以想象一下,如果模型把一些本来就能被分对的样本的预测概率变得更搞,BCE Loss 是会降低,但 F2-Score 还是一样。
为什么要强调这点呢?因为有队友在探索 Ensemble 方法的时候,看着 BCE Loss 不好就放弃了;再往后另一个队友重新实现了一样的 Ensemble 方法,看的是 F2-Score,却发现效果拔群!所以说,如果只看 Loss,不看最终评价指标,很容易做出误判,错过有用的方案,这对于其他问题来说也是成立的。
另外讨论区也有人提到一种直接对 F2 Score 进行优化的方法,我们因为时间有限还没来得及进行尝试。
3.2 划分训练集和验证集
一开始将官方的训练数据(Train Data)划分训练集(Train Set)和验证集(Validation Set),或者均匀划分成 K 个部分,用于做 K 折交叉验证(K-Fold Cross Validation)。关键的是,随机划分结果要队伍内和方案间共享。不然的话,这个模型训练用的 K 折划分和那个模型训练用的K折划分不同,还怎么严格比较它们之间的优劣呢?而且这也是为后面数据分析和模型的 Ensemble(集成)做准备。
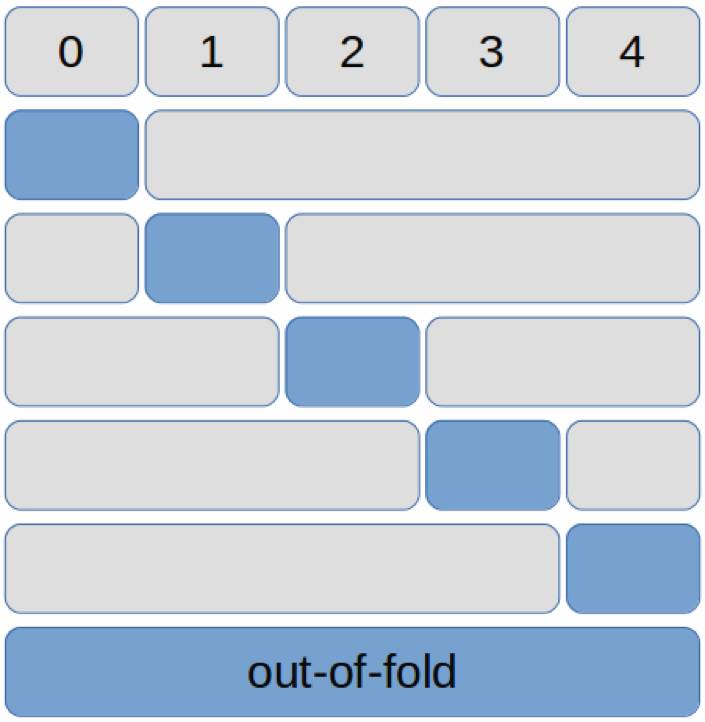
这一次我们将数据平均划分了五折(编号 0-4),使用一折作为验证集,使用其他四个折作为训练集,可以有五种组合。然后探索初期方案期间,只使用其中一种组合,例如将第 0 折作为验证集,1-4 折作为训练集。
在模型确定后,如果想用上全部数据作为训练,我们可以使用五种组合,每种组合用四折训练一个模型(对应下图中 4 个灰色大块),在剩下的一个折作为验证集预测(对应下图中 5 个蓝色小块),遍历五种组合后我们可以获得每一个折的验证集预测结果(还是对应下图中 5 个蓝色小块),因为
这些验证结果都是从没有在它们上面训练过的模型预测出来的
,我们把这个五个验证折拼在一起的结果称为 out-of-fold,包含整个训练集的验证结果(对应下图中的蓝色长块)。在 out-of-fold 上面进行阈值调优得到的 F2-Score 可以较好的代表模型的能力,可以真实地反映模型的泛化性能,多个模型的 out-of-fold 拼接在一起也可以作为第二阶段的集成学习的输入。
在上面的 5 种组合上做了 5 次训练,测试的时候我们就有了 5 个模型,每个模型预测一遍测试集就得到了 5 个概率矩阵,每个概率矩阵的形状都是(测试集样本数 x 17)。我们可以将 5 个概率矩阵直接求平均后做二分类预测,也可以分别做完二分类预测,再做投票,来获得最终的多类预测结果。这个结果实际上用到了所有 5 个折的训练数据,会更加准确,也更加稳定。
当然如果只是想用上所有数据的话,更简单的办法就是直接把整个训练集用这个模型跑一遍,再把训练好的模型模型对测试集作预测。不过我们没有采用这第二种方式,一来,所有训练样本都被这模型“看光了”,没有额外的验证集,难以评估其泛化性能;二来,我们认为第一种方法中,5 个模型的预测结果做了个简单的 Ensemble,会更稳定一点。
折数划得越多,训练验证所需要的计算力和时间也就越多,最好根据问题和自身计算力做一个权衡。
3.3 深度学习还是传统方法
通过调查我们可以发现,Kaggle 图像比赛现在基本被深度学习方法所统治。虽然在一些细节上传统方法还有发挥空间,但还是以 CNN(卷积神经网络)为主体。
3.4 框架选择与Model Zoo
虽然之前我主用 TensorFlow,不过 PyTorch 提供的 Model Zoo 使用起来很方便,代码比较轻量级,队内会用的人数也比较多,所以这次比赛我们最终采用了 PyTorch 作为主体框架——除了队内某个异端,他用 TensorFlow 为自己写了一个高效的 DataLoader。
PyTorch 的 Model Zoo 提供了 AlexNet,VGG, Inception v3, SqueezeNet, ResNet, DenseNet 等架构的预训练模型参数。我们还嫌这些模型不够用,就尝试了从 TensorFlow 上迁移过来的的 Inception v4 和 Inception Res v2(Tensorflow-Model-Zoo.torch | GitHub) 。可惜的是,大概由于这两个模型走的不是“正规渠道”,是“偷渡”过来的,大概哪里出了偏差,总之训练结果一塌涂地,果断放弃。在这里我们呼吁大家支持正版。
PyTorch 文档提供了不同模型在 ImageNet 上 Top-1、Top-5 的错误率,可以大概看出这些模型的能力,虽然这不一定和它们在比赛中的表现性能正相关。
在我们这次比赛中,ResNet 表现最好,DenseNet 紧随其后,这不是偶然的。它们有一个引人注目的共同点,就是从底层到高层有 Skip-Connection,其中 ResNet 采用的是两路叠加,Densenet 是多路拼接。为什么重要呢?我们认为,第一是因为 Skip-Connection 可以自适应调节模型复杂度,避免过拟合,第二是因为 17 个类所利用的图像特征层次不同,比如 Cloudy 更偏向底层纹理特征,Water 和 Road 更偏向高层语义,而 Skip-Connection 有助于让底层特征到很高层仍然保留,而不会淹没在几十层网络的变换中。
稍弱一点是 VGG 和 Inception v3,最弱的是 SqueezeNet 和 AlexNet。从 TensorFlow 上迁移过来 Inception v4 和 Inception Res v2 基本上不收敛,再次呼吁大家支持正版。
3.5 预训练或随机初始化
我们一开始在 ResNet-18 这个轻量级的模型分别尝试预训练参数(Pretrained)和随机初始化参数(From Scratch)进行训练,结果发现,随机初始化的模型的收敛速度比预训练的模型要慢上十倍左右,最终收敛结果也差上一截。有队友还试着自己设计一些网络架构,但结果也远远比不上预训练模型。
所以做完这波实验后,我们也大概确定这次的比赛,跑 Model Zoo 将是主要的手段。听起来并不像自己设计网络结构那么激动人心,但我们也可以在上面做些一些魔改,魔改之后也取得了意料之外的提升,具体见下一节。
3.6 预训练模型使用与改动
使用预训练模型的时候要注意,PyTorch 文档中说明了这些模型都是在 224x224 的图像上进行预训练,而且要求图片要经过归一化并减掉某个均值、除以某个方差,然后才输入模型。如果想要模型能最大程度的利用预训练的信息,一定要对我们输入图片也做同样的操作。
不过虽然模型的输入要求是 224x224,但一部分模型(比如 ResNet,DenseNet)的卷积层结束时会接一个 Global Average Pooling,将每个通道的 Feature Map 求平均,这样不管输入的图片尺寸多大,经过 Global Average Pooling 之后 Feature Map 的尺寸都会变成 1x1,所以理论上是可以直接使用的。
然而这里有一个坑点是,PyTorch 预训练模型卷积层最后其实使用是一个 7x7 固定大小的 Average Pooling,并不是真正的 Global AveragePooling。要想输入其他尺寸大小的图,我们应该把该层替换成 AdaptiveAvgPool,并将输出设置大小为 1,这样就能保证无论上一层 Feature Map 尺寸是多少,出来的尺寸都会是 1x1。
当然,有可能一下子缩到 1x1 太小了,损失了太多信息,所以我们也可以把 AdaptiveAvgPool 输出大小设置为 2 或 3,使得输出尺寸变成 2x2 和 3x3,这样的好处是保留下更多的信息。为了与之匹配,还需要改动后面整个全连接层的尺寸。我们后来在 Densenet 和 ResNet 上尝试这个改动,取得了不错的效果。
以上是针对 ResNet 和 DenseNet 来说的,而像 VGG 这种模型,最后 Feature Map 是直接 Flatten(拉直)然后接全连接,我们如果要利用到后面的预训练全连接层信息,我们就只能将输入图片缩放成 224x224 了。
除了更改 Pooling 输出尺寸,另一个尝试成功的魔改是关于全连接层的。ImageNet 模型最后一层是 1000 类,而我们需要的是 17 类输出,以往常见的做法是把最后一层全连接层换掉,换成一个 output size 为 17 的新全连接层,然后重新初始化它的参数。
然而,我们的两个队友却因为偷懒发现了效果更好的做法,就是直接在预训练模型的 1000 维输出后面,直接就接上一个 1000x17 的全连接层。我们猜测,它效果好的原因是额外地保留下了全连接层的预训练信息。
另外有些队友担心,这个比赛的大多数图片都可能被预训练模型识别为草地之类的 ImageNet 类别,所以可能基本上都只激活 1000 维中的少数几个,会很稀疏,这样其实应该是对训练不利的。针对这种疑虑,我们将很多比赛图片输入预训练模型后,发现它们在 1000 类上预测的概率值并不稀疏,所以应该没太大问题。不过,这种新做法也可能只对这次比赛任务有效,在其他任务上还是建议先试着把最后一层全连接换掉或是整个随机初始化,因为一般来说最后一层的可迁移性更差一点。
至于具体要怎么在全连接层中加 Batchnorm、Dropout 就看个人选择了,我们在发现这个任务上没有太显著影响,后面大部分模型都没有加。










