正文
这个就是大名鼎鼎的ELK架构。es比较适合存储较短时间的热数据的实时检索查询,对于需要长期存储,并且希望使用hadoop或者spark进行大时间跨度的离线分析时,还需要存储到hdfs上,所以比较常见的数据流程图为:
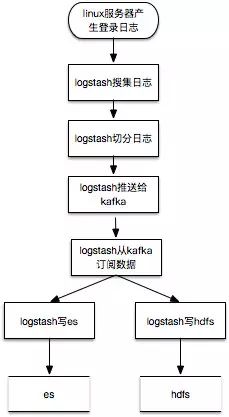
数据处理纬度
这里以数据实时流式处理为例,storm 从 kafka 中订阅切分过的ssh登录日志,匹配检测规则,检测结果的写入 mysql 或者 es。
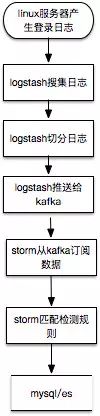
在这个例子中,孤立看一条登录日志难以识别安全问题,最多识别非跳板机登录,真正运行还需要参考知识库中的常见登录IP、时间、IP情报等以及临时存储处理状态的状态库中最近该IP的登录成功与失败情况。比较接近实际运行情况的流程如下:
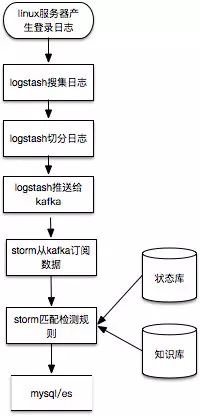
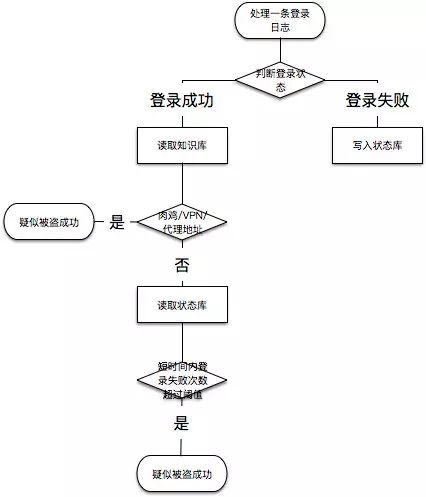
具体判断逻辑举例如下,实际中使用大量代理IP同时暴力破解,打一枪换一个地方那种无法覆盖,这里只是个举例:
扩展数据源
生产环境中,处理安全事件,分析入侵行为,只有ssh登录日志肯定是不够,我们需要尽可能多的搜集数据源,以下作为参考:
-
linux/window系统安全日志/操作日志
-
web服务器访问日志
-
数据库SQL日志
-
网络流量日志
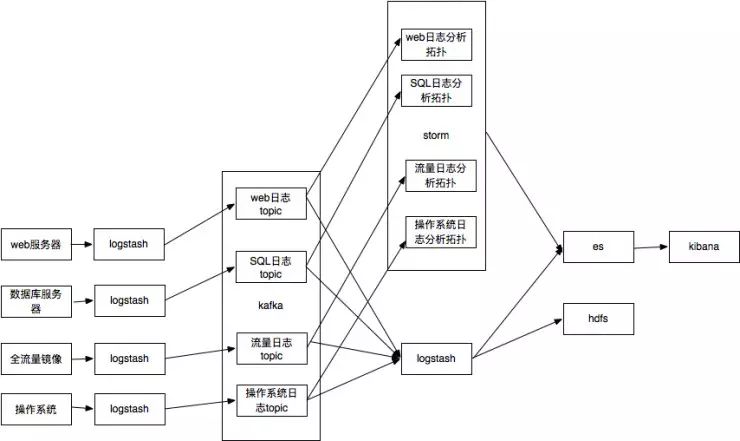
简化后的系统架构如下,报警也存es主要是查看报警也可以通过kibana,人力不足界面都不用开发了:
消息队列:kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
流式处理:storm
Apache Storm 是一个免费开源的分布式实时计算系统。简化了流数据的可靠处理,像 Hadoop 一样实现实时批处理。Storm 很简单,可用于任意编程语言。
Storm 有很多应用场景,包括实时数据分析、联机学习、持续计算、分布式 RPC、ETL 等。Storm 速度非常快,一个测试在单节点上实现每秒一百万的组处理。
storm拓扑支持python开发,以处理SQL日志为例子:
假设SQL日志的格式是
"Feb 16 06:32:50 " "127.0.0.1" "root@localhost" "select * from user where id=1"
一般storm的拓扑结构:
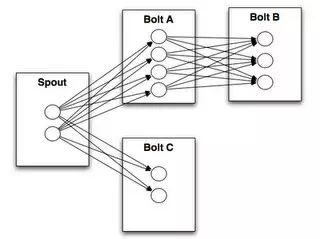
简化后 spout 是通用的从 kafka 读取数据的,就一个 bolt 处理 SQL 日志,匹配规则,命中策略即输出”alert”:”原始SQL日志”。
数据搜集:logstash
-
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
-
当然它可以单独出现,作为日志收集软件,你可以收集日志到多种存储系统或临时中转系统,如MySQL,redis,kakfa,HDFS, lucene,solr等并不一定是ElasticSearch。
logstash的配置量甚至超过了storm的拓扑脚本开发量,这里就不展开了。
实时检索:ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。









