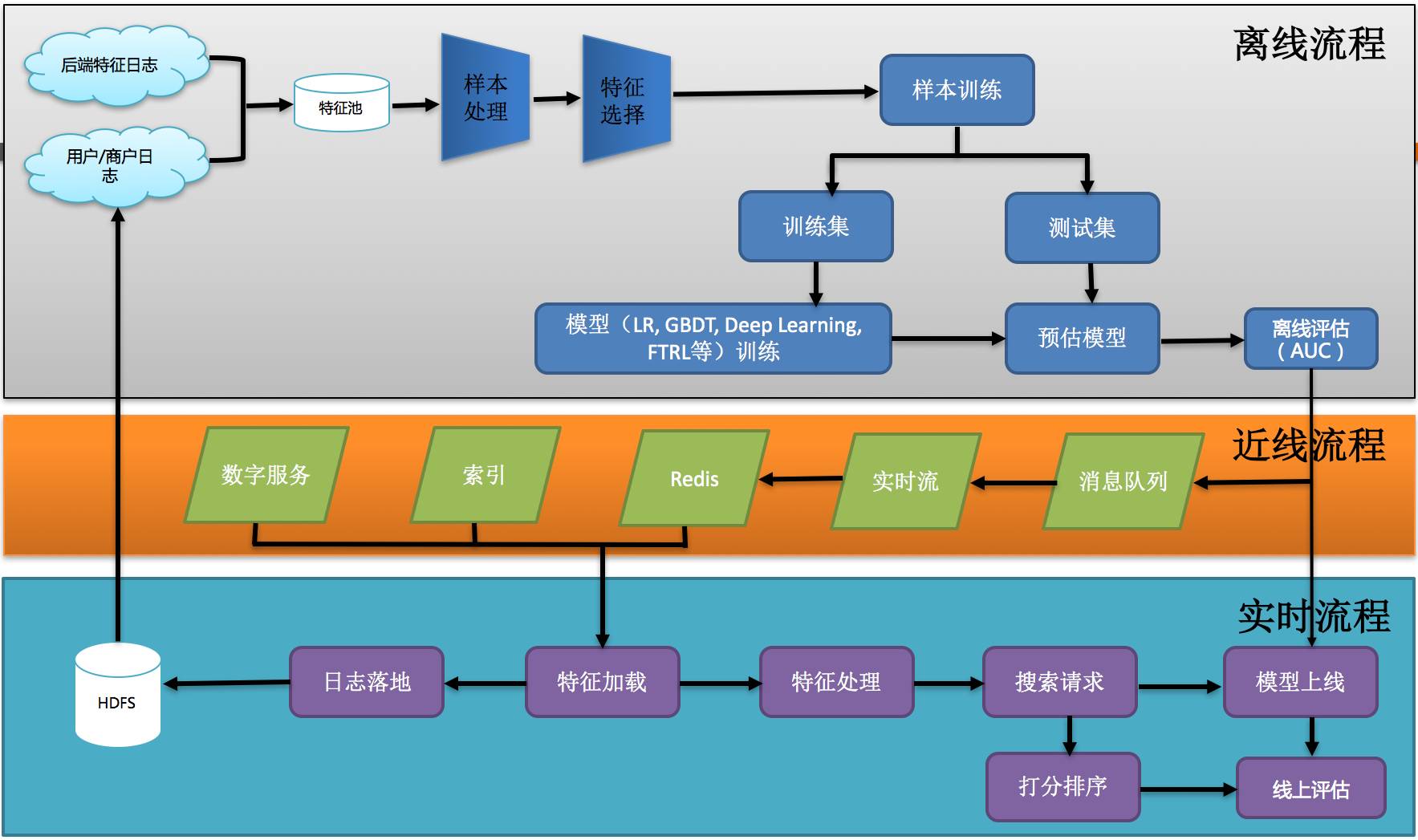
正文
3.1 现有排序框架介绍
到目前为止,点评推荐排序系统尝试了多种线性、非线性、混合模型等机器学习方法,如逻辑回归、GBDT、GBDT+LR等。通过线上实验发现,相较于线性模型,传统的非线性模型如GBDT,并不一定能在线上AB测试环节对CTR预估有比较明显的提高。而线性模型如逻辑回归,因为自身非线性表现能力比较弱,无法对真实生活中的非线性场景进行区分,会经常对历史数据中出现过的数据过度记忆。下图就是线性模型根据记忆将一些历史点击过的单子排在前面:

从图中我们可以看到,系统在非常靠前的位置推荐了一些远距离的商户,因为这些商户曾经被用户点过,其本身点击率较高,那么就很容易被系统再次推荐出来。但这种推荐并没有结合当前场景给用户推荐出一些有新颖性的Item。为了解决这个问题,就需要考虑更多、更复杂的特征,比如组合特征来替代简单的“距离”特征。怎么去定义、组合特征,这个过程成本很高,并且更多地依赖于人工经验。
而深度神经网络,可以通过低维密集的特征,学习到以前没出现过的一些Item和特征之间的关系,并且相比于线性模型大幅降低了对于特征工程的需求,从而吸引我们进行探索研究。
在实际的运用当中,我们根据Google在2016年提出的Wide & Deep Learning模型,并结合自身业务的需求与特点,将线性模型组件和深度神经网络进行融合,形成了在一个模型中实现记忆和泛化的宽深度学习框架。在接下来的章节中,将会讨论如何进行样本筛选、特征处理、深度学习算法实现等。
3.2 样本的筛选
数据及特征,是整个机器学习中最重要的两个环节,因为其本身就决定了整个模型的上限。点评推荐由于其自身多业务(包含外卖、商户、团购、酒旅等)、多场景(用户到店、用户在家、异地请求等)的特色,导致我们的样本集相比于其他产品更多元化。我们的目标是预测用户的点击行为。有点击的为正样本,无点击的为负样本,同时,在训练时对于购买过的样本进行一定程度的加权。而且,为了防止过拟合/欠拟合,我们将正负样本的比例控制在10%。最后,我们还要对训练样本进行清洗,去除掉Noise样本(特征值近似或相同的情况下,分别对应正负两种样本)。
同时,推荐业务作为整个App首页核心模块,对于新颖性以及多样性的需求是很高的。在点评推荐系统的实现中,首先要确定应用场景的数据,美团点评的数据可以分为以下几类:
-
用户画像:
性别、常驻地、价格偏好、Item偏好等。
-
Item画像:
包含了商户、外卖、团单等多种Item。其中商户特征包括:商户价格、商户好评数、商户地理位置等。外卖特征包括:外卖平均价格、外卖配送时间、外卖销量等。团单特征包括:团单适用人数、团单访购率等。
-
场景画像:
用户当前所在地、时间、定位附近商圈、基于用户的上下文场景信息等。
3.3 深度学习中的特征处理
机器学习的另一个核心领域就是特征工程,包括数据预处理,特征提取,特征选择等。
-
特征提取:
从原始数据出发构造新的特征的过程。方法包括计算各种简单统计量、主成分分析、无监督聚类,在构造方法确定后,可以将其变成一个自动化的数据处理流程,但是特征构造过程的核心还是手动的。
-
特征选择:
从众多特征中挑选出少许有用特征。与学习目标不相关的特征和冗余特征需要被剔除,如果计算资源不足或者对模型的复杂性有限制的话,还需要选择丢弃一些不重要的特征。特征选择方法常用的有以下几种:

特征选择开销大、特征构造成本高,在推荐业务开展的初期,我们对于这方面的感觉还不强烈。但是随着业务的发展,对点击率预估模型的要求越来越高,特征工程的巨大投入对于效果的提升已经不能满足我们需求,于是我们想寻求一种新的解决办法。
深度学习能自动对输入的低阶特征进行组合、变换,得到高阶特征的特性,也促使我们转向深度学习进行探索。深度学习“自动提取特征”的优点,在不同的领域有着不同的表现。例如对于图像处理,像素点可以作为低阶特征输入,通过卷积层自动得到的高阶特征有比较好的效果。在自然语言处理方面,有些语义并不来自数据,而是来自人们的先验知识,利用先验知识构造的特征是很有帮助的。
因此,我们希望借助于深度学习来节约特征工程中的巨大投入,更多地让点击率预估模型和各辅助模型自动完成特征构造和特征选择的工作,并始终和业务目标保持一致。下面是一些我们在深度学习中用到的特征处理方式:
3.3.1 组合特征
对于特征的处理,我们沿用了目前业内通用的办法,比如归一化、标准化、离散化等。但值得一提的是,我们将很多组合特征引入到模型训练中。因为不同特征之间的组合是非常有效的,并有很好的可解释性,比如我们将"商户是否在用户常驻地"、"用户是否在常驻地"以及"商户与用户当前距离"进行组合,再将数据进行离散化,通过组合特征,我们可以很好的抓住离散特征中的内在联系,为线性模型增加更多的非线性表述。组合特征的定义为:
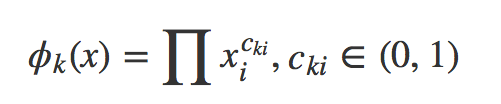
3.3.2 归一化
归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。在实际工程中,我们运用了两种归一化方法:
Min-Max:

Min
是这个特征的最小值,
Max
是这个特征的最大值。
Cumulative Distribution Function(CDF):
CDF也称为累积分布函数,数学意义是表示随机变量小于或等于其某一个取值x的概率。其公式为:

在我们线下实验中,连续特征在经过CDF的处理后,相比于Min-Max,CDF的线下AUC提高不足0.1%。我们猜想是因为有些连续特征并不满足在(0,1)上均匀分布的随机函数,CDF在这种情况下,不如Min-Max来的直观有效,所以我们在线上采用了Min-Max方法。
3.3.3 快速聚合
为了让模型更快的聚合,并且赋予网络更好的表现形式,我们对原始的每一个连续特征设置了它的super-liner和sub-liner,即对于每个特征x,衍生出2个子特征:
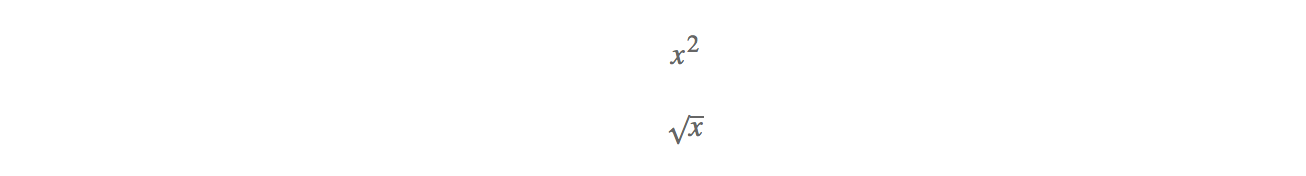
实验结果表示,通过对每一个连续变量引入2个子特征,会提高线下AUC的表现,但考虑到线上计算量的问题,并没有在线上实验中添加这2个子特征。
3.4 优化器(Optimizer)的选择







