正文
“指标”(metric)是衡量问题进展的一种方式,通常与测试数据集有关。给定的一个问题同参更会有几个metric,但有时是从0开始,并需要提出一些metric…
measure[ment]是在给定metric上,特定时间,特定代码库/团队/项目的得分。
1. 图像分类
视觉领域中,最简单的子问题可能是图像分类,也即让计算机识别图像中存在什么物体。从 2010 年到 2017 年,ImageNet 竞赛一直是业界密切关注的热点。

ImageNet 数据集示例
图像分类不仅包括识别图像中的单个物体,还包括对它们进行定位,并且确定哪些像素属于哪个物体。MSRC-21 指标是专门为此任务而建的:
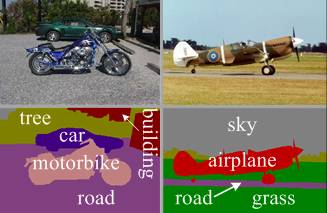
MSRC-21 示例
2. 看图回答问题(Visual Question Answering)
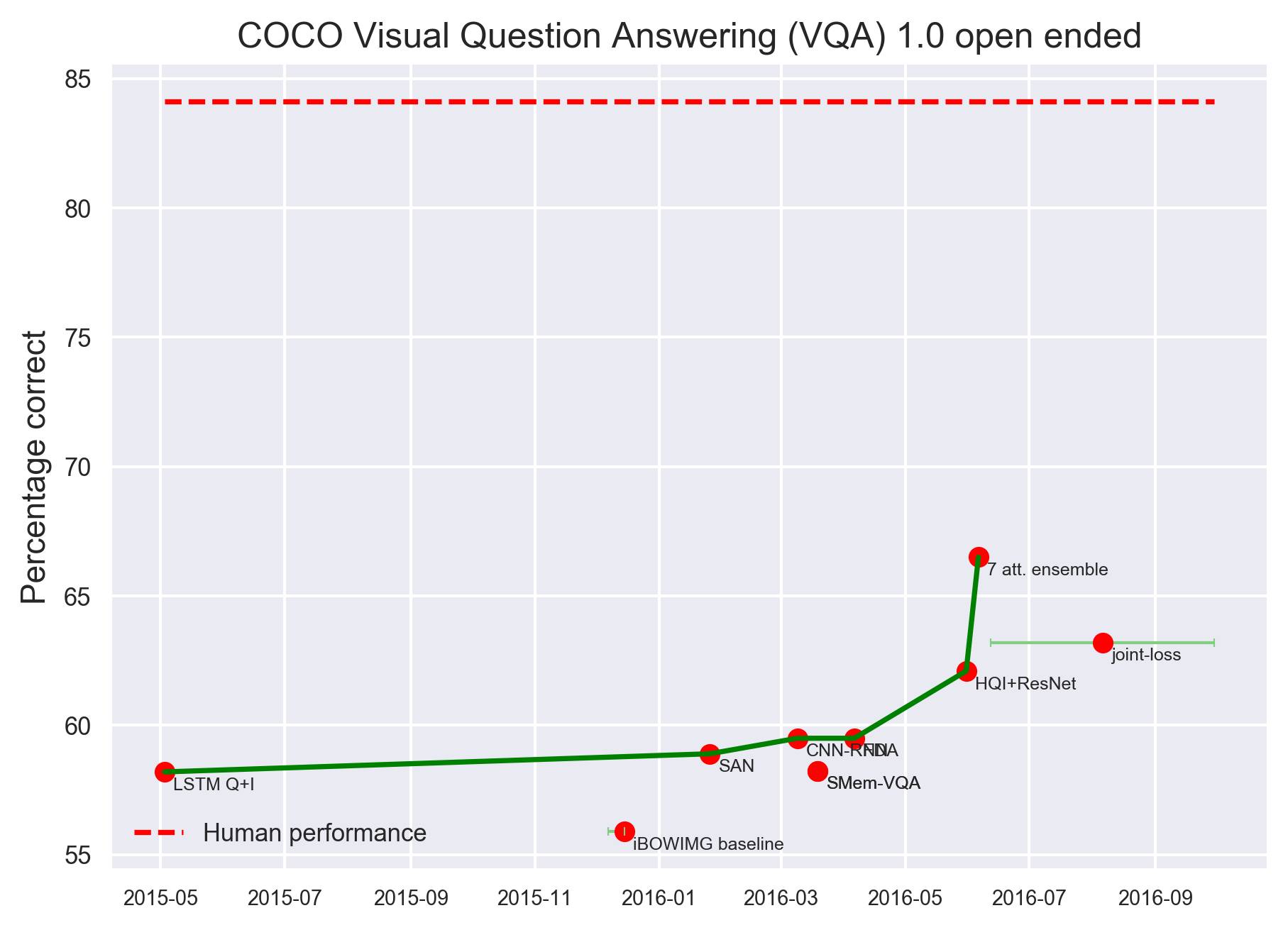
理解图像涉及的不仅仅是识别其中的物体或实体,也包括从图像中识别事件、关系和场景。理解图像不仅需要进行图像识别,还要掌握语言、世界建模和“图像理解”(image comprehension)。目前在这方面有几个数据集。下图来自 VQA,其中图像来自 Microsoft COCO 图像集,问题和问答都是由 Amazon Mechanical Turk 工作人员提出的。

VQA 数据集示例
那么,在视觉领域,计算机都在什么时间、以什么方式超越人类了呢?
最具代表性的是,在图像识别任务上,2016 年,微软亚洲研究院(MSRA)首先超越人类水平(红色虚线,下同)。
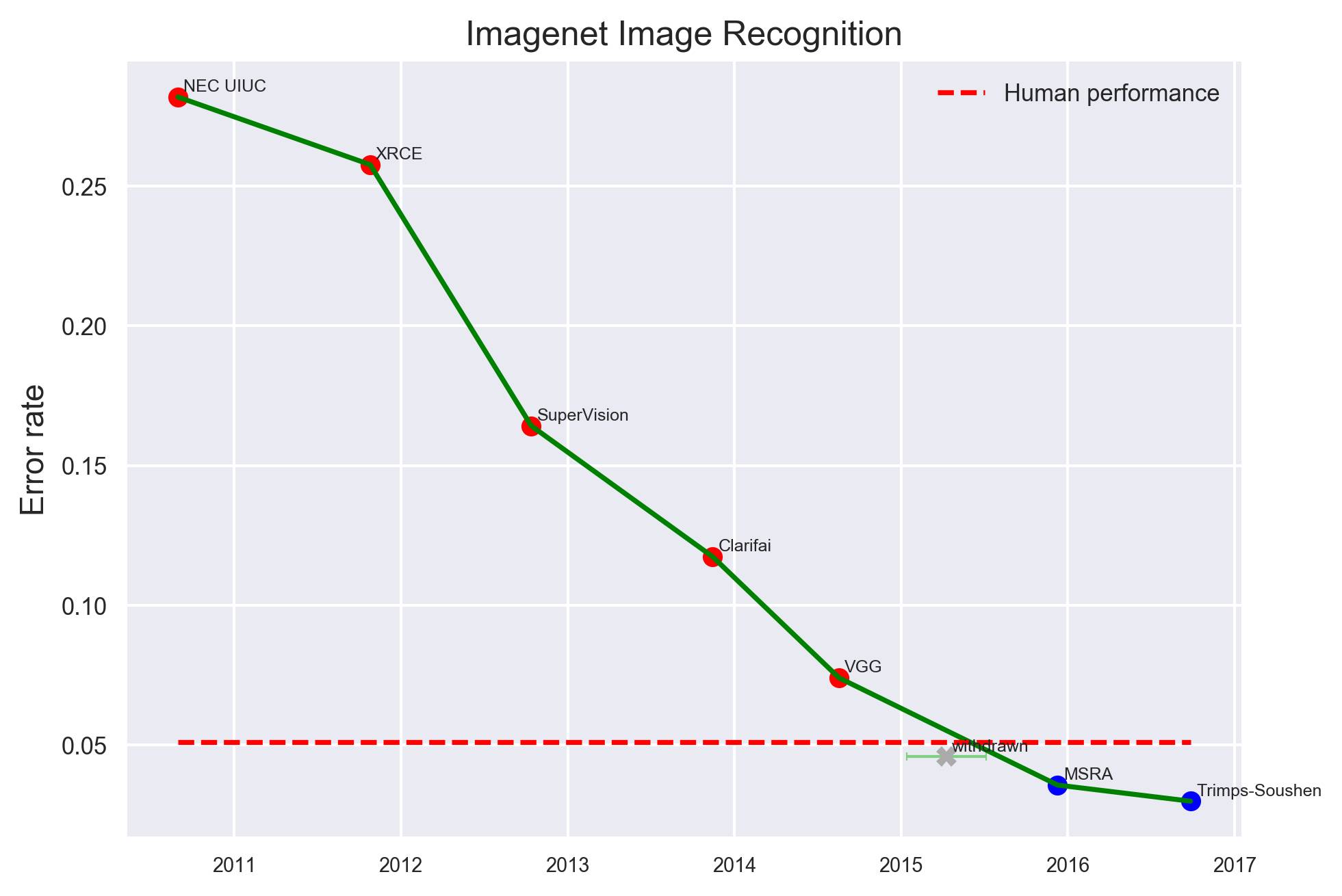
其他,在较小的数据集任务中,比如 CIFAR-10 数据集图像识别任务,2015 年 ICML 论文“Striving for Simplicity:The All Convolutional Net”率先突破人类水平。

更早一些,在街景房屋编号数据集(SVHN)上,2013 年纽约大学,包括 Yann LeCun 在内的学者提出“Regularization of Neural Networks using DropConnect”,率先超越了人类水平。

不过,在看图问答问题方面,计算机距离人类水平还有一定距离。下图是 COCO VAQ 1.0 开放问答任务,根据目前统计结果,计算机距离人类水平还有十几个百分点。
总体上,游戏是一个高效的开放式研究框架, 所有的智能都能在游戏中捕捉到。但是,抽象的游戏,比如象棋、围棋和跳棋等,可以在不需要人类世界或者物理世界知识的前提下玩。
虽然,这一领域大部分的游戏已经被计算机攻克,达到了超越人类的水平,但是现在仍然有一些游戏需要解决,特别是,考虑到不同的起点,一些游戏需要智能体从任意的抽象游戏中有效地学习规则(例如,对规则的文本描述或者是正确玩法的例子)。
1. 抽象的策略游戏
复杂的抽象策略游戏中,机器系统已经达到了超越人类的水平。其中一些是规则启发的和启发式的(heuristics),在一些例子中,则结合了机器学习的技术。
抽象策略游戏的代表之一是国际象棋,我们都记得 1997 年 5 月 11 日,IBM 的 Deep Blue 对战国际象棋大师卡斯帕洛夫并取得胜利。不过,Deep Blue 在这份统计中,并不算作计算机玩国际象棋超越人类(见图中 Deep Blue 红色拐点)。
根据这份统计,2006 年 5 月 27 日,英国计算机国际象棋程序 Rybka 1.164 bit 取胜才算开了先河。这之后,计算机国际象棋程序表现越来越好,公认超越人类水平。

2. 实时视频游戏
计算机视频游戏是一个非常开放的领域,很可能,现在或者未来的一些游戏过于复杂,进而成为“AI专属”的。同时,在一些进阶的游戏中,随着复杂度的不断增加,我们可能会看到很多有趣的进步。
-
Atari 2600 Alien:人类的平均水平在6800分左右。2015年3月,DQN模型的得分是在3000分左右。2015年11月底,DDQN得分逼近4000,Duel得分超过4500,但是距离人类水平都还有一定的差距。
-
Atari Amidar:人类的平均水平在1700分左右,2015年3月,DQN的得分只有700左右,2015年11月底,DDQN和Duel都超越了人类水平,得分分别为1700和2300左右。
-
Atari2600 Assault:人类的平均水平是1500分。DQN、DDQN和Duel都已经全面超越人类。
-
Atari 2600 Asterix:人类的平均水平是8000分。2015年3月,DQN的得分是6000分,2015年11月底,DDQN得分达到17000分,Duel得分近30000。
-
Atari 2600 Gravitar:人类的平均水平在2800分左右,DQN、DDQN和Duel的得分都在600以下。
注: DeepMind 首先在2015年初发布了 Nature文章,提出DQN。在2015年一年内提出了Double DQN,Dueling Network。后两者极大提升了DQN的性能,目前的改进型DQN算法在Atari游戏的平均得分是Nature版DQN的三倍之多。
语音识别
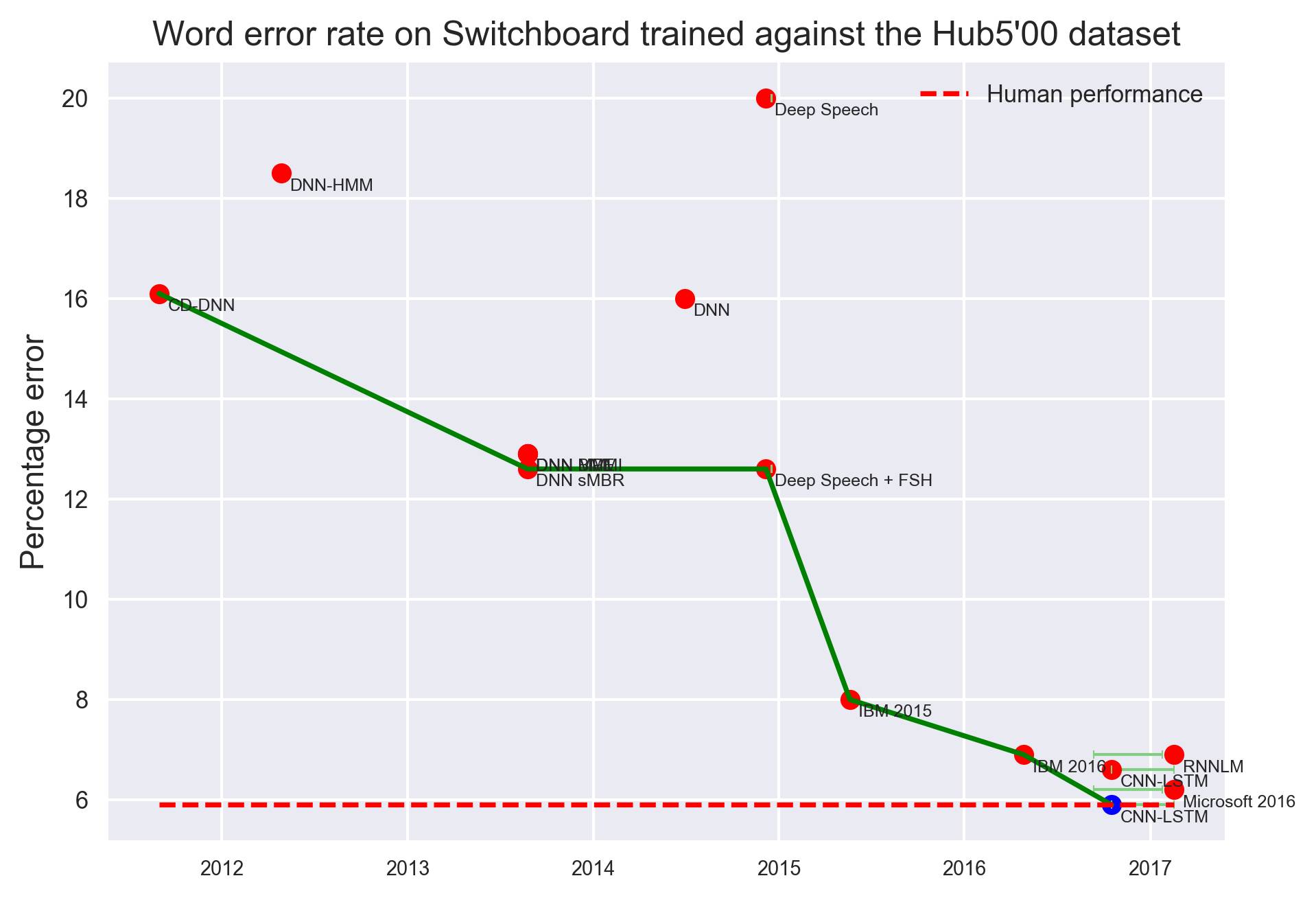
Switchboard上语音识别词错误率变化,衡量标准:Hub500