正文
而李世石版AlphaGo则用了48个TPU。阿尔法零除了独立地学会了人类花费数千年时间来发现的围棋规则,还自行学会了非常有趣的围棋策略,并且许多走法都“极具创造性”。
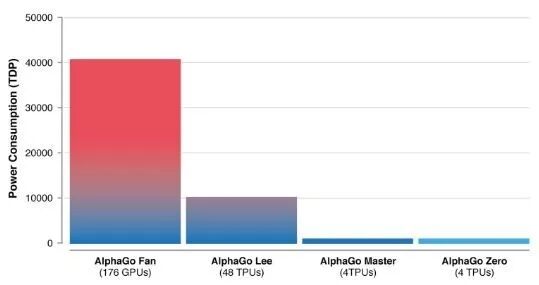
▲AlphaGo的效率越来越高(图片来源:DeepMind)
那么阿尔法零是如何实现这种飞跃的?
每日经济新闻(微信号:nbdnews)记者注意到,阿尔法零采用的是人工神经网络。这种网络可以计算出下一步走棋的可能性,估算出下棋选手赢的概率。随后根据计算,阿尔法零会选择最大概率赢的一步去下。
整个训练过程中,并没有人类参与,全程是阿尔法零自我学习,自我对弈。在训练过程中,阿尔法零每下一步需要思考的时间是0.4秒。但正是通过对围棋游戏的模拟和训练,神经网络变得越来越好。

▲阿尔法零从0到72小时的自学成长图(图片来源:DeepMind 论文)

创始人:AI可以解决现实难题
谷歌深度学习联合创始人兼CEO德米斯·哈比斯(Demis Hassabis)表示,阿尔法零这个项目之所以如此强大,是因为它“
不再受限于人类知识的局限
”。

▲图片来源:DeepMind官网
哈比斯还相信,如果将这个项目应用到治疗像老年痴呆症这样重大的健康问题上的话,
那么在几周内,就能找到治愈人类需要花费几百年时间才能找到的疗法。
“我们希望利用这种算法突破,
来帮助解决各种紧迫的现实世界问题。
如果类似的技术可以应用到其他问题上,例如减少能源消耗或寻找新材料,那么取得的突破就具有推动人类的理解的潜力,并对我们的生活产生积极影响。”






