正文
在这其中,当下最流行的就是GAN和
V
ariational
A
uto
E
ncoder(VAE),两种方法的一个简明示意如下[3]:
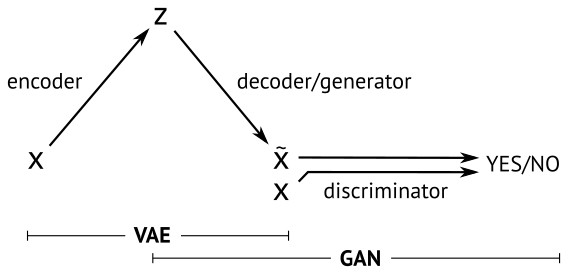
本篇不打算展开讲什么是VAE,不过通过这个图,和名字中的autoencoder也大概能知道,VAE中生成的loss是基于重建误差的。而只基于重建误差的图像生成,都或多或少会有图像模糊的缺点,因为误差通常都是针对全局。比如基于MSE(Mean Squared Error)的方法用来生成超分辨率图像,容易出现下面的情况[4]:
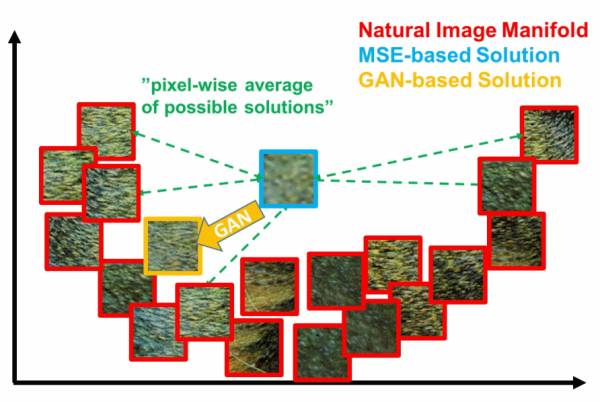
在这个二维示意中,真实数据分布在一个U形的流形上,而MSE系的方法因为loss的形式往往会得到一个接近平均值所在的位置(蓝色框)。
GAN在这方面则完爆其他方法,因为目标分布在流形上。所以只要大概收敛了,就算生成的图像都看不出是个啥,清晰度常常是有保证的,而这正是去除女优身上马赛克的理想特性!
马赛克->清晰画面:超分辨率(Super Resolution)问题
说了好些铺垫,终于要进入正题了。首先明确,去马赛克其实是个图像超分辨率问题,也就是如何在低分辨率图像基础上得到更高分辨率的图像:

视频中超分辨率实现的一个套路是通过不同帧的低分辨率画面猜测超分辨率的画面,有兴趣了解这个思想的朋友可以参考我之前的一个答案:如何通过多帧影像进行超分辨率重构?
不过基于多帧影像的方法对于女优身上的马赛克并不是很适用,所以这篇要讲的是基于单帧图像的超分辨率方法。
SRGAN
说到基于GAN的超分辨率的方法,就不能不提到SRGAN[4]:《Photo-Realistic Single Image
S
uper-
R
esolution Using a
G
enerative
A
dversarial
N
etwork》。这个工作的思路是:基于像素的MSE loss往往会得到大体正确,但是高频成分模糊的结果。所以只要重建低频成分的图像内容,然后靠GAN来补全高频的细节内容,就可以了:
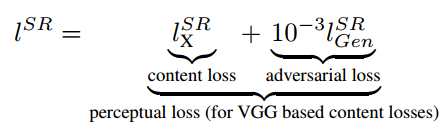
这个思路其实和最早基于深度网络的风格迁移的思路很像(有兴趣的读者可以参考我之前文章
瞎谈CNN:通过优化求解输入图像
的最后一部分),其中重建内容的content loss是原始图像和低分辨率图像在VGG网络中的各个ReLU层的激活值的差异:
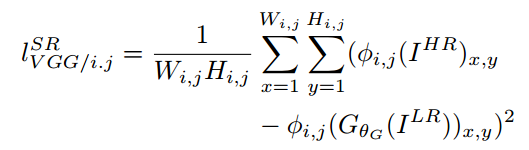
生成细节adversarial loss就是GAN用来判别是原始图还是生成图的loss:
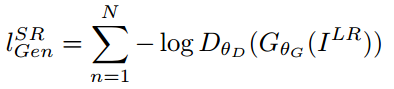
把这两种loss放一起,取个名叫perceptual loss。训练的网络结构如下:
正是上篇文章中讲过的C-GAN,条件C就是低分辨率的图片。SRGAN生成的超分辨率图像虽然PSNR等和原图直接比较的传统量化指标并不是最好,但就视觉效果,尤其是细节上,胜过其他方法很多。比如下面是作者对比bicubic插值和基于ResNet特征重建的超分辨率的结果:

可以看到虽然很多细节都和原始图片不一样,不过看上去很和谐,并且细节的丰富程度远胜于SRResNet。这些栩栩如生的细节,可以看作是GAN根据学习到的分布信息“联想”出来的。
对于更看重“看上去好看”的超分辨率应用,SRGAN显然是很合适的。当然对于一些更看重重建指标的应用,比如超分辨率恢复嫌疑犯面部细节,SRGAN就不可以了。
pix2pix
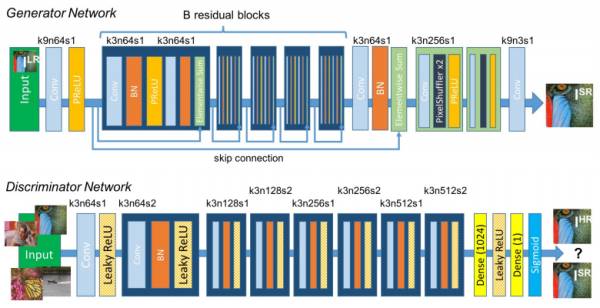
虽然专门用了一节讲SRGAN,但本文用的方法其实是pix2pix[5]。这项工作刚在arxiv上发布就引起了不小的关注,它巧妙的利用GAN的框架解决了通用的Image-to-Image translation的问题。举例来说,在不改变分辨率的情况下:把照片变成油画风格;把白天的照片变成晚上;用色块对图片进行分割或者倒过来;为黑白照片上色;…每个任务都有专门针对性的方法和相关研究,但其实总体来看,都是像素到像素的一种映射啊,其实可以看作是一个问题。这篇文章的巧妙,就在于提出了pix2pix的方法,一个框架,解决所有这些问题。方法的示意图如下:
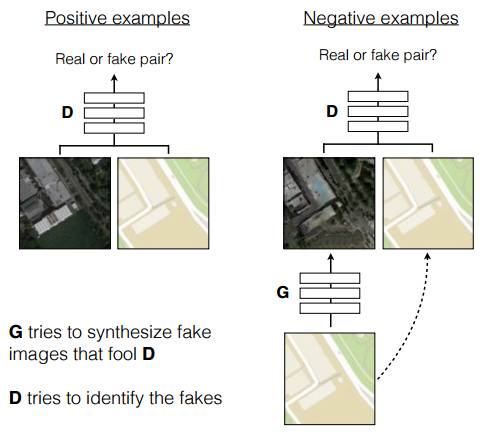
就是一个Conditional GAN,条件C是输入的图片。除了直接用C-GAN,这项工作还有两个改进:
1)
利用U-Net结构生成细节更好的图片
[6]
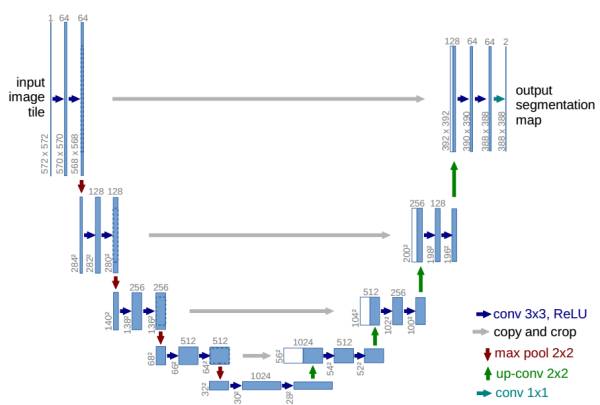
U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显,下面是pix2pix文中给出的一个效果对比:









