正文
-XX:+PrintGCDetails
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCApplicationConcurrentTime
做分析最简单的方式就是直接把日志导入 Censum 之中。图一所展示的就是所有运行过的分析的总结。首先要注意的是,在各项分析中有两项是失败的,并用红色的打叉图标做出了标记。再看看这些分析结果,就会知道 Censum 已经对情况做出了判断。要把失败了的分析手动重做一次只要一分钟就可以了,但首先咱们还是先看看 Censum 的分析总结,以及“Heap after GC”图表。
两个视图都可以帮我们了解两次失败了的分析的背景。从图二的总结页面可以看出这里使用了并发回收器。共有 21 次年轻代回收和一次完全回收。这个视图中的其它指标都没有太多好说的,或者说是在可接受的范围之内。比如应用程序 99.3% 的吞吐量是远高于要求的 95% 的阈值的,而每秒 1165KByte 的分配率也是远低于每秒 1GByte 的阈值。如果超出了前一个阈值,就意味着垃圾回收机制配置得不够好(那种情况下会触发我们称之为垃圾回收器的“技术调节”的事件,但那是另一篇文章的主题),而如果超出了后面的阈值则意味着你的应用程序内存不足了,应该判断并优化内存分配的热点,当然这又是再一篇文章的主题了。
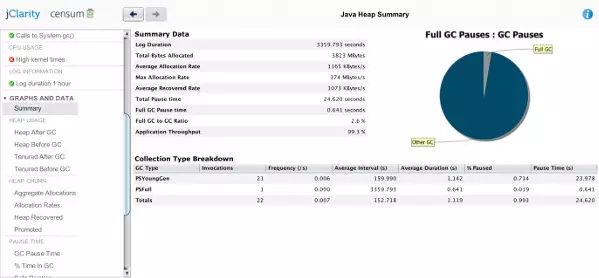
这个例子中的“Heap after GC”页表明堆也成了完整的垃圾回收过程的一部分。别的回收过程看起来都没什么,堆的使用情况看起来也还很稳定。总的堆大小在 700MB 到 800MB 之间波动。Tenured 相关的大小也很平稳的保持在 520MB。这表明年轻代的大小在 200MB 到 300MB 之间。按照现在的标准来看,这些内存池的大小都特别小,所以 Heinz 才会开那个 386 的玩笑。这份日志中没有任何东西提到“23 秒的暂停”。咱们再去看看那些失败了的分析,看看为什么会失败,看看这是不是导致长期暂停的原因。
第一个失败了的分析是简单的暂停时间分析。因为暂停的时间太长了,所以它才会失败。考虑到总的花费比较小(在这次分析中叫做“Time Paused”),这次长时间的暂停就表现得特别显眼,需要深入调查。





