正文

第一点,数据处理的能力随机器的增加而增加,这是传统的可扩展。第二点,智能水平和体验壁垒要随着业务、数据量的增加而同时增加。
这个角度的 Scalable 是很少被提到的,但这个层面上的可扩展性才是人工智能被推崇的核心原因。
举个例子,过去建立竞争壁垒主要通过业务创新快、行业内跑马圈地,或是通过借助新的渠道(比方说互联网)提升效率。在这样的方式中,由于产品本身相对容易被抄袭,那么资本投入、运营与渠道是关键。但随着数据的增加与 AI 的普及,现在有了一种新的方式,就是用时间与数据创造壁垒。举个简单的例子,如果现在去做一个搜索引擎,即使有百度现成的技术现在也很难做得过百度,因为百度积累了长时间的数据,用同样的算法也很难跑出一个比百度更好的搜索结果。这样如果拥有能用好数据的人工智能,就会获得更好的体验,反过来更好的体验又会带来更多的用户,进一步丰富数据,促进人工智能的提高。可以看出,由人工智能产生的竞争壁垒是不断循环迭代提升、更容易拉开差距的高墙。
可扩展的机器学习系统需要高 VC 维
那么,我们怎么能获得一个既拥有高智能水平又能 Scalable 的学习系统呢?
60 年代 Vapnik 和 Chervonenkis 提出了 VC 维理论,形式化的描述了机器学习算法对复杂函数拟合的能力。对
VC 维的理解
,可以举个简单的例子就类似于人大脑内的神经元,神经元数量越多,这个人可能就越聪明。当然,这个不是绝对的,智商高的人比一定做出来的成就是最高的,这里关键的一点是个人的经历也要多,之后经历过很多事情、并且有思考的能力,才能悟出道理。在机器学习中,VC 维度讲的也是这个道理。
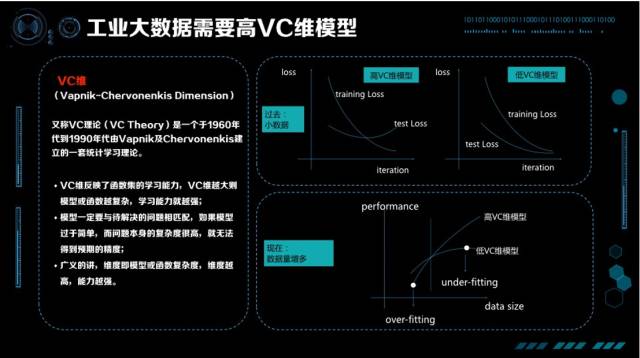
教科书上的 VC 维都是上面这样的一张图。因为过去的数据不大,训练损失函数在不断下降,测试损失函数在不断的上升,要避免过拟合,VC 维就不能太高。比如你是个很聪明的孩子,但是在很小的时候不能让你过多的思考瞎琢磨,否则很有可能走火入魔。过去对我们教导是在你经历不多、数据不多时干脆傻一点,就没有那么多精力去思考乱七八糟的事情。这是当时大家觉得比较好的解法,控制 VC 维,让训练数据的 Test Loss、Training Loss 同时下降。
但随着时代的不断发展,数据也是在不断增多的,我们的观点有了新的变化。在数据量比较小的时候,高 VC 维的模型比低 VC 维的模型效果要差,产生了 over-fitting,这只是故事的一部分;有了更多数据以后,我们发现低 VC 维模型效果再也涨不上去了,但高的 VC 维模型还在不断上升。这就是刚才说的智能 Scalable 的概念,在我们有越来越多数据的时候,要关心的是 under-fitting 而不是 over-fitting,要关心的是怎样提高 VC 维让模型更加聪明,悟出大数据中的道理。
总结成一句话,
如果要成功在工业界使用人工智能,VC 维是非常重要的问题。
工业界怎么提升 VC 维呢?我们知道「机器学习=数据+特征+模型」,如果已经有很多数据,提升 VC 维的方法有两条:一种是从特征提升,一种是从模型提升。我们把特征分为两类:一类特征叫宏观特征,比如描述类特征如年龄、统计类特征如整体的点击率、或整体的统计信息;另一类为微观特征,最典型的是 ID 类的特征,每个人都有特征,每个物品也有特征,人和物品组合也有特征。相应的模型也分为两类,一部分是简单模型如线性模型,另一类是复杂模型如深度学习模型。这里,我们可以引出工业界机器学习四个象限的概念。
模型 X 特征,工业界机器学习的四个象限
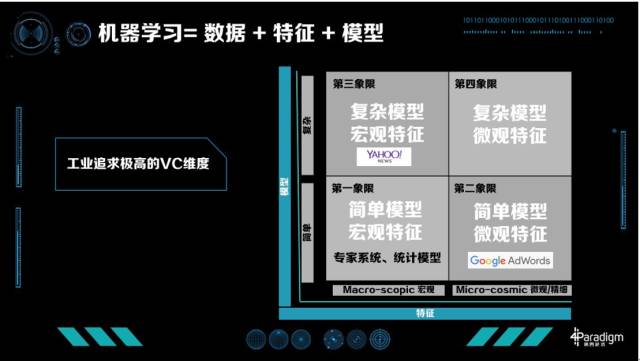
工业界具体怎么做的?
第一象限是简单模型加上宏观特征,在现在的工业界比较难以走通,很难得到极致化的优化效果。
这个象限内,有七八十年代专家系统,还有一些统计模型。大家比较熟悉的 UCI Data 就是支持这个时代研究的典型数据,每个数据集有 1000 个左右的训练数据,分的类数也不多,特征也不多。对于这样的数据统计模型比较盛行,要解决的问题是怎样找出特征之间的关系与各自的统计特性。
第二象限是简单模型、复杂特征,最成功的典型案例是 Google AdWords。
Google 在很多技术上都是开山鼻祖,包括整个计算广告学。Google AdWords 有上千亿的特征,每个人、每个广告、每个 Query 的组合都在其中。这种模型非常成功,给 Google 带来了非常大的收益。Google AdWords 占 Google 70% 以上的收入,Google 的展示广告也是用的这样的技术,占了 Google 大概剩下的 20% 左右的收入。
第三象限是复杂模型、宏观特征典型的应用,比如 Bing ads,2013 年他们提出 BPR(Bayesian Probit Regression)来 Model 每个特征的置信度。
雅虎也是第三象限忠实的传道士之一,大家所熟知的 COEC(Click Over Expected Click)这个算法就是雅虎提出的,在上面做了很多模型。其次他们还设计了很多模型解决增强学习问题,比如多臂老虎机等等算法。很多雅虎出去创业的同事最常使用的机器学习技术就是统计特征加 GBDT(Gradient Boosting Decision Tree),通常能获得非常好的效果。
第四象限,复杂模型和微观特征,现在还是热门研究的领域,它最难的一点是模型的规模实在太大。
比如广告有上千亿的特征,如果做深度学习模型一个隐层有 1000 个特征,可能会有万万亿级别的参数。虽然数据很多,但万万亿的数据还是难以获得的。所以怎么解决这个角度的模型复杂问题、正则化问题,目前研究还是一个热点的研究方向。
如何沿着模型优化?

沿着模型优化主要由学术界主导,新的模型主要来自于 ICML、NIPS、ICLR 这样的会议。他们主要的研究是非线性的,总结起来有「三把宝剑」:Kernel、Boosting、Neural Network。Boosting、Neural Network 现在非常流行,Boosting 最成功的是 GBDT,而 Neural Network 也在很多行业产生了颠覆性的变化。大约十年前,Kernel 也是很流行的。借助 Kernel,SVM 有了异常强大的非线性能力,让 SVM 风靡了 10-15 年。优化模型的科学家们为了实验的方便,对工程实现的能力要求并不是特别高,大部分模型是可以单机加载的。要解决的实际问题主要是数据分布式,降低数据分布式带来的通讯 overhead 等问题。
对于工业界中的具体问题,基于思考或观察得到新的假设,加入新的模型、结构,以获得更多的参数,这是工业界优化这一项限的步骤。
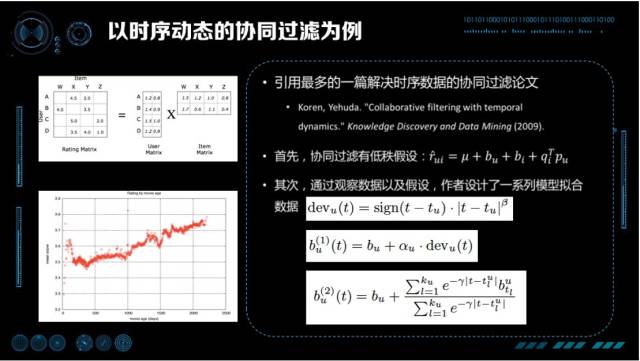
以时序动态的协同过滤为例,我们这里引用的是 Koren, Yehuda 在 2009 年在 KDD 上发表的论文 Collaborative filtering with temporal dynamics,这是时序动态协同过滤被应用最多的一篇经典论文。在这篇论文里,首先协同过滤的问题有一个低秩假设,作者认为由 User,Item 组成的稀疏矩阵是由两个低秩矩阵相乘得到预估评分。第二,通过观察数据,作者观察到 IMDB 对某些电影的打分是随着时间的加长,分数不断上升(对那些经典的电影)。根据这样线性的关系,设计「现在的时间」减去「首次被打分时间」作为偏置,拟合斜率就是一个好的模型。考虑到更复杂的情况下,打分随时间的变化并不是单纯的线性,作者进一步提出将线分成很多小段,每个小段做分段线性。
总结一下,通过机器学习优化的套路是什么?
首先,观察数据;
第二,找到规律;
第三,根据规律做模型的假设;
第四,对模型假设中的参数用数据进行拟合;
第五,把拟合的结果用到线上,看看效果怎么样。
这是模型这条路在工业界上优化的方法。
如何沿特征优化?










