正文

简单而言,分析层也做两件事情。
第一是对多模态医疗数据的分析
,不管是结构化病历数据、影像数据,还是文本数据、时间序列数据,不同的数据不存在单一的技术能够对所有数据都进行一个很完美的分析,所以目前针对不同类型的数据有不同的分析方法,有些适合用深度学习的方法,有些采用时间序列的方法,有一些适合用回归分析的方法,分类的方法,聚类的方法。
第二,分析是与医疗领域相关的,医学里有一些特定的问题,不是去分析照片是谁或者什么,而是分析数据里疾病风险的因素是什么,怎么样做疾病的预测和预防,怎么样对患者进行精准分群,可以对患者进行个性化治疗或者有不同的治疗方案时哪种方案对患者反应比较好(treatment effectiveness),包括影像识别怎么自动发现影像中间的病灶,都有非常强的医学知识。从解决方案的角度来看,医疗是一个非常复杂的行业,医院、医生、药厂、医疗设备制造商、健康管理机构、医疗保险公司,他们的诉求是不一样的,不必须要针对不同类型的客户做出不同的解决方案,可以利用底层的云平台和分析技术。在解决方案里,我们有针对像医院类型的医疗机构的解决方案,包括肿瘤的个性化治疗,Oncologyand Genomics,医院影像(medical imaging)的分析。还有针对药企做新药发现和上市药物有效性、安全性的分析,还有帮助健康管理机构,对常见的慢性病人群(高血压、糖尿病、慢性肾病)以及多种并发性慢病的患者进行管理解决方案,也有帮助医疗保险机构合理地valuedbased care,按照价值来付费,来进行疾病管理。在目前的平台上,IBM通过过去两年的收购,目前有超过2亿美国人的医疗保险数据,有超过1亿美国人的电子病历数据,有超过10亿张的医学影像片子,有美国几十个州的慢性病管理数据,把这些数据关联起来做分析,就会发现非常有价值的,任何单一数据源都无法发现的一些insight或者evidence,可以支持上面各种各样的应用。
接下来,给大家来介绍一些具体案例。
第一个我想介绍的是沃森个性化肿瘤治疗助手。

首先肿瘤是一个非常恶性的疾病,目前很多肿瘤也没有什么好的办法,但是危害非常大的。以中国为例,每年新发的肿瘤大概超过 400 万,有一些特定的肿瘤,比如与消化道相关的食管癌胃癌发病率很高,全世界每年新发胃癌有超过40%是在中国。同时,肿瘤治疗很困难。一方面疾病本身比较困难,另一方面治疗方法层出不穷,各种靶向药物,各种新的治疗方法不断的出现。如果想要做一个好的肿瘤医生,每月要读超过1万篇与肿瘤相关的新的科研文献,这是不可能的。这个解决方案的核心技术是运用自然语言理解技术,让机器去代替人去读书。这个系统读了两千多万篇文献,应用自然语言理解抽取里面的疾病症状、诊断治疗、患者病情,然后构成非常复杂的知识图谱。基于这样的知识图谱,当患者问诊,系统会自动从患者所有的既往病历信息中,包括检查报告、片子、检验结果、病史的描述,自动抽取上百项的关键信息,借助后台的知识图谱进行一个很复杂的推理过程,给出治疗的推荐治疗方案,包括不同的方案与患者的契合度,这样的信息可以帮助肿瘤科医生更好地用最新的最好的治疗方案,为患者提供个性化的治疗。Watson Genetics从基因维度切入,与前面解决方案一起解决肿瘤治疗。

因为肿瘤本质上是一种基因变异导致的恶性疾病,医生们就想能不能通过直接用药物打靶,靶向作用到变异的基因来控制肿瘤。
这个系统也很简单。拿到一个患者的二代测序结果后,通过分子的profiling,在患者所有的变异基因全部找到之后,进行很复杂的pathway分析。Pathway主要通过在几千万篇文献中,学习各种药物靶向、基因变异、蛋白质作用过程等方方面面,构成了很复杂的网络,然后推理,给出相应的靶向药物的治疗推荐。前一阶段有个新闻报道,日本东京大学有一个患者得了非常罕见的白血病,然后没有医生没有见过,没有办法确诊,还甚至进行了误诊。借助这样一个系统,很快就找到患者可能得的白血病,同时推荐了一些靶向药物,挽救他的生命。
Watson先读了很多书,包括300本期刊,200多本教科书,几千万的文献。这就是实际系统使用的界面,来了一个患者之后系统会推荐,每一行是一个治疗方案,绿色的是最好的治疗方案,包括放疗、化疗、手术治疗、药物治疗、各种不同的治疗。同时,每一种治疗方案,系统会给出更多的信息,比如治疗方案,愈后效果,是否有毒性,毒性是什么样的。这些信息并不靠医生手工提前录入,而是由系统自动从几千万份文献中,利用自然语言的理解技术,把这些关键信息抽取出来构造成一个知识库,然后推送到医生面前。
其实,很多医院进行肿瘤治疗时,会请很多专家给出自己的治疗意见,包括治疗方案的优缺点。这个系统就相当于一个读了所有的最新文献的专家,把不同的治疗方案包括副作用、不同治疗方案药物之间的相互作用,生成了一本大概有三四十页的报告,提交给医生,帮助医生去做出针对患者最有利的一个治疗方案。
下面想介绍的案例是现在非常火的医学影像。医学影像极大地推动了医疗的发展。最早医生看病通过听诊器诊断,后来出现了X光,然后出现了更复杂的像核磁、超声等各种简单诊断设备。这些影像设备可以帮助医生,更好地看到患者体内的信息,甚至包括病理,通过组织切片用高倍显微镜看到细胞层次的变化,做出更加准确的一个判断。
影像对医学的作用太大了,所以在03年的时候,发明核磁共振的一个物理学家和一个化学家竟然得了诺贝尔医学奖,核磁共振极大的颠覆了医疗诊断和治疗。影像也是多模态数据。有一些比较常见的二维影像,比如眼底影像,皮肤癌影像,或者消化道的胃镜肠镜;还有一些是三维影像,比如ct或者核磁通过向切片扫描的方式,对人体进行上百次的扫描,生成一个完整的三维影像。能够很好地用来做各种诊断和治疗;还有一类是这种病理影像,主要做很多肿瘤的治疗,它需要从疑似肿瘤的部位取一个组织,然后进行切片,放在高倍显微镜下,都是几万*几万像素的高分辨率的影像。往往一张病历影像的片子可能就有3G-4G的大小。这些影响虽然可以提高医疗水平,但是分析同样很困难。协和医院想去约一个核磁或者ct可能需要一周甚至一个月的时间。机器其实是不休息,人要休息,看不过来。现在影像分析面临的一个很大的问题——三甲医院的医生的话有大量片子他看不过来。同时,有一些消化道影像,比如胶囊机器吞到肚子里,一次拍一个视频出来,做一次检查生成3万到5万张影像,有病变的部位不超过30张,要从3万张中间去找到那30张,那就是大海捞针,就要靠医生花大量的时间去过滤掉那些无效的片子。所以影像技术的进步对医生来说最迫切的需求就是,怎么样利用识别技术自动发现病噪,提高他看片的效率。
机器看片原理很简单。首先,用一些比较经典的一些影像分析或者模式识别的方法,模拟一个医生的看片过程,看一些视觉特征。因为很多病变部位的位置、大小、颜色、边缘形状都有一些视觉特征,利用这些视觉特征可以帮助计算机判断出来是不是一个恶性的肺结节,或者是不是某一种皮肤癌。同时,计算机可以利用复杂的卷积网络,在像素层级上看像素的变化,在像素层级上进行计算,比人看得更细致。可以通过构建多层的神经网络去提取那些隐含的特征信息,利用这样的信息做判断。
计算机角度来可以看多模态的数据。它不光看影像数据,还看病例信息、基因测序结果,将多模态的信息融合在一起,可以达到一个更好的效果。我们做过很多实验,如果用影像分析叠加其他模态的数据,比如将病历数据、年龄数据、历史病例等关键信息抽取出来之后,病变识别的精度可以直接提高10%以上。
我这边给大家介绍两个例子,一个是黑色素瘤的。
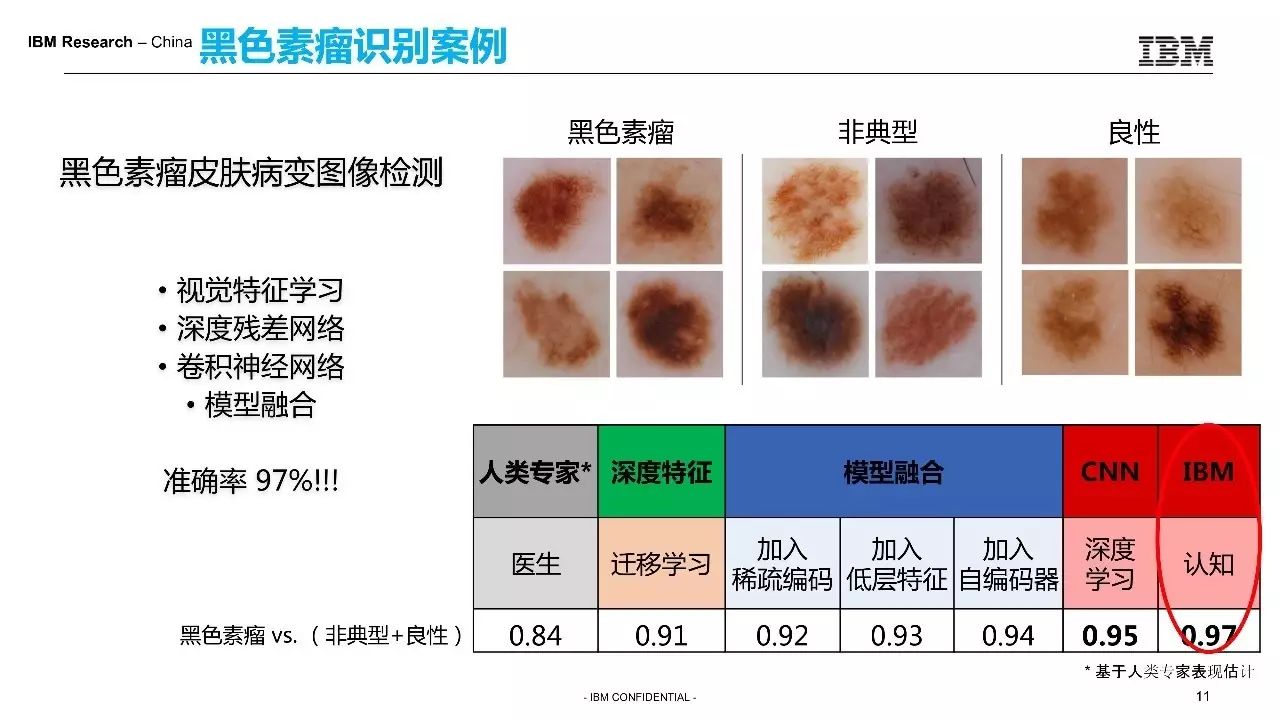
我们将1万张影像有标记的影像交给机器。它利用深度学习的技术学习之后,构建了一个模型,然后再从测试集里面拿出3000张让3名医生和计算机一起来看。人达到的精度大概是84%左右,而计算机可以达到97%。不止是IBM,很多其他公司计算机大概做到90%到95%。
另外一个例子是消化道影像。
每一次检测生成的数据特别多,有 3万到5万张,同时里面有很多不均衡的数据,若想能够自动将这些出血点检测出来,就需要迁移学习技术,很多数据的预处理技术,包括data augmentation或者data resampling,然后构建出来深度学习的网络,达到更好的识别精度。
我给大家看一个针对皮肤癌的小视频。用手机或各种有摄像头的移动设备,拍一下手上的某一个色斑,上传到后台的云服务器上,里面已经有一个训练好的模型。这个模型主要就是做一个分类,判断一下影像是不是黑色素瘤,经过后台计算之后会给出一个结果。判断它不是黑色素瘤,颜色都是比较浅。同时系统会自动把已知的一些确诊的相似的影像返回回来,帮助医生或者患者做一个更好的判断。
实验者也还选了一个已知黑色素瘤的一个确诊影像,这个系统中出现红色告警,说很大可能程度是一个恶性的黑色素瘤,同时会把一些类似的影像都会返回回来,帮助医生来做一个判断。
下面我想给大家介绍的案例的话叫
真实世界证据分析。
它是一个医学界的词,对应的词叫RCT,双盲随机对照临床实验。目前判断一个药或一个治疗方案是否有效,必须要做RCT实验,证明药效或者治疗方法的有效性。一个这样的实验平均要花十年以上的时间,要花10到15亿美金,而且不超过10%的成功率。RCT是一个非常耗时耗力耗钱的方式,真实世界证据就是跟它做对应的。
RCT实验一般会组织几百个人,比如五百八百人,分成组去进行实验,要积累数据。同时每天其实生成大量的医疗数据。以中国为例,一年就诊的人次接近70亿人次,相当于是全国人民,每年看五次病,当然有一些老病号。70亿次就诊产生了大量的临床数据,但是这些数据并没有被很好分析,都散落在医院的各个信息科机器上面。这些信息其实可以被用来做真实世界的挖掘,就是利用真实世界的数据,做更好的疾病治疗、预防等。
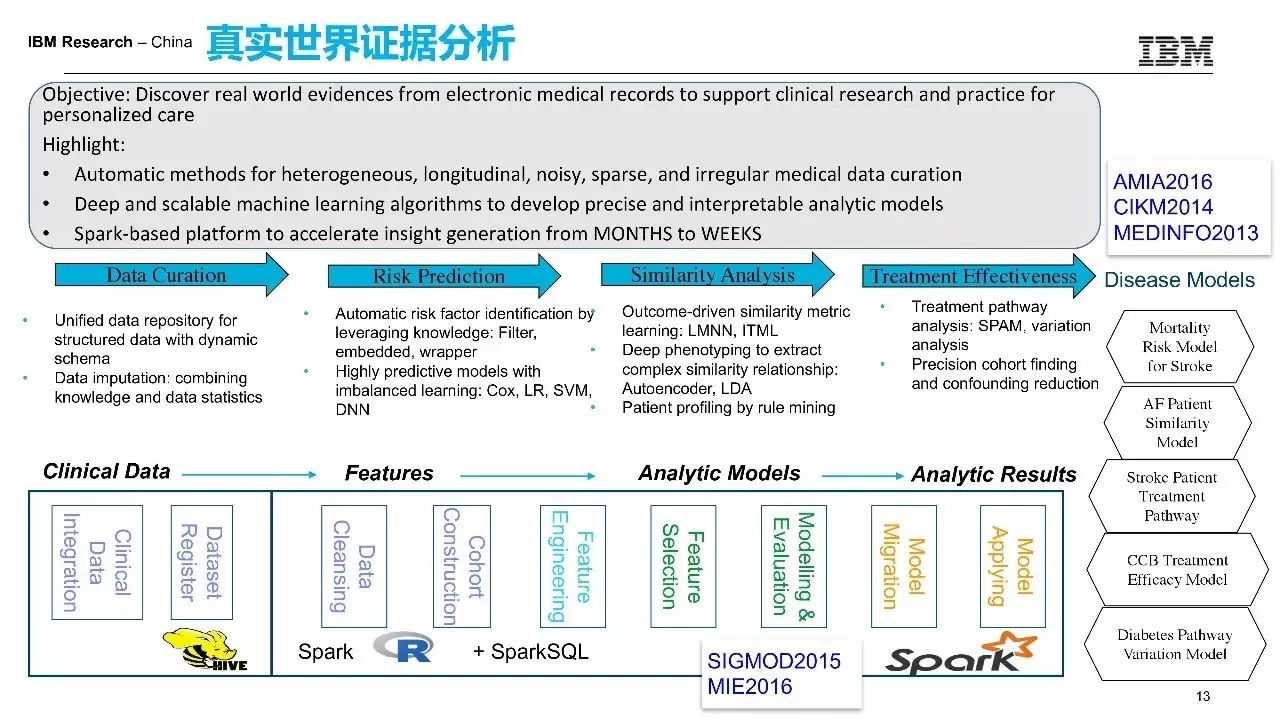
真实世界证据就是真实世界中数据,包括病历数据、医疗保险数据、疾病数据,输入进来,产出各种模型,比如中风病人的再中风预测模型,或心梗病人的死亡风险预测模型,或某种药物治疗有效性的模型。
这样的模型是通过这样的pipeline得到的。我们发现,第一可以有一个通用的pipeline去解决真实世界数据分析的问题,因为过程重复,包括导入数据,数据清洗和整理,构建患者人群,抽取特征做建模。很多是通用的,比如疾病风险预测分析,患者的相似性分群分析,治疗有效性分析,患者依从性分析。这样的分析的话都可以变成一些可重用的模块,作为一插件在平台上来做模型生成。比如,咖啡机放入数据就会生成咖啡,里面有很多参数要调整,你是要喝美式还是拿铁还是摩卡。我说起来比较简单,但是就是这么一个过程,我给大家举两个例子。
第一个例子的话是我们做的疾病风险预测的一个例子。
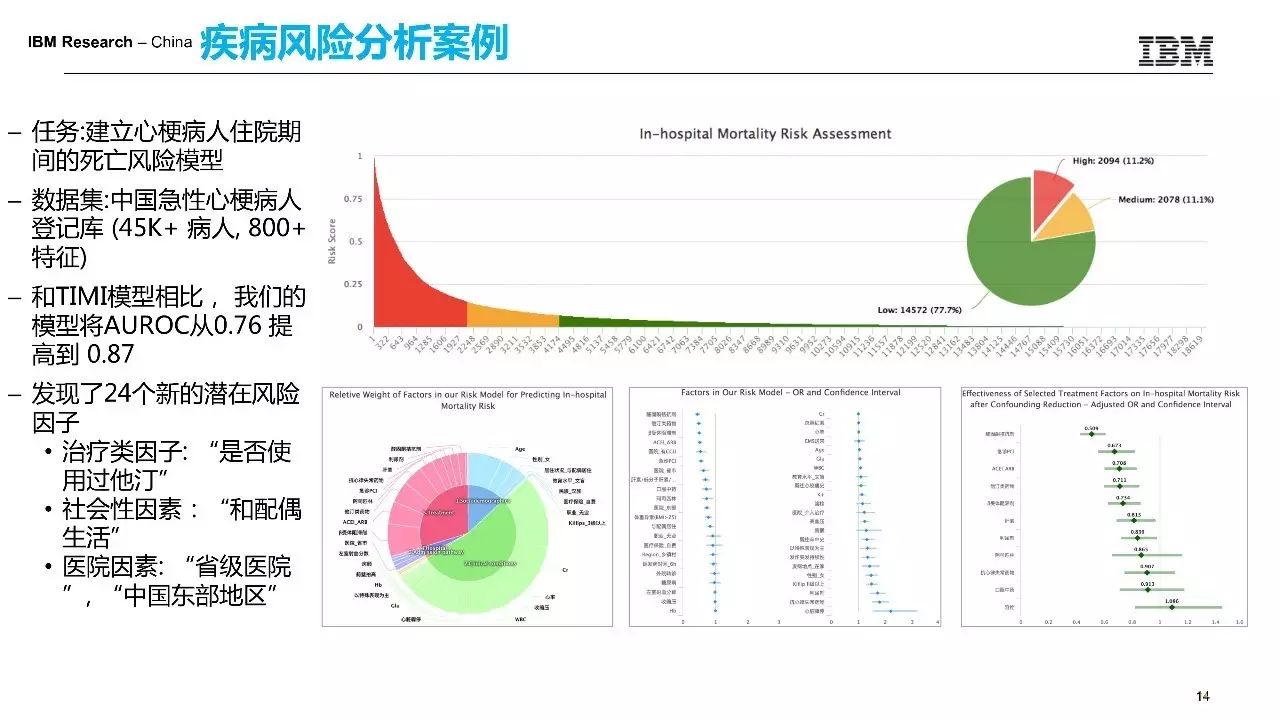
这个数据库里有45000个心梗病人,有超过800个变量去描述病人的基本信息,包括它的治疗信息,临床信息等。医生想知道哪些因素会导致患者出现院内的死亡,每个患者院内死亡的可能性有多高,这就是一个典型的疾病风险预测的问题。那这个风险模型以前是有的,TIMI模型是目前医学界公认的最好的心脏病的风险预测模型,AUC大概是在0.76,利用我们的方法AUC可以做到0.87,同时我们发现了24个新的风险因素,有很多风险因素的话是非医疗性质的,比如说一些社会性的因素或者就诊医院的一些因素,比如说家庭幸福的人不容易死。









