正文
Tracing GC 管理生命周期的方式很巧妙,它并不跟踪每个具体的对象,而是通过扫描当前还有哪些对象仍然在使用,找到那些已经不再使用的对象,释放之。这种方式简单直观高效,但非常粗犷,无法确保某个对象一定在生命周期结束后得到释放。它还有一些副作用,比如消耗额外的 CPU 时间,GC 工作时会打断工作线程的执行,以及需要在内存消耗情况和 GC 频次之间找到一个平衡点等等。Tracing GC 下的内存管理就像我们的大学生活:平时各种浪,考前狂突击。
Swift 采用的是另一种策略 —— ARC(Atomic Reference Counting)。它通过编译时根据每个对象的引用情况,插入相应的引用计数代码(进入函数时,retain - 被引用的对象引用计数增加,退出时 release - 被引用的对象引用计数减少),从而精确掌控每个对象的生命周期:

(图片来自:Swift: Avoiding Memory Leaks by Examples [2])
这种方式的虽然规避了 Tracing GC 的很多副作用,但它为了实时追踪对象的引用情况,在运行时也付出了不少代价:retain/release 做了很多事情,并且为了线程安全,修改引用计数需要加锁或者使用 atomics,这比我想象的要吃性能 [3],并且 ARC 无法处理循环引用 —— 所以需要开发者在适当的地方使用 weak ref 来解除循环引用带来的引用计数问题。
ARC 下的内存管理就像在工厂打工:上班签到,下班打卡,兢兢业业,一丝不苟。
而 Rust,采用了完全不同的方式。对 Rust 而言,像 C/C++ 那样靠开发者手工来追踪对象的生命周期是不靠谱的 —— 人总是会犯错,何况这个世界上合格的程序员非常稀缺;但像 Java/Swift 这样在运行时花费额外代价来追踪生命周期,又和语言本身的目标不符。最终 Rust 沿用和发展了 Cyclone 的生命周期的处理方式。
在我之前的文章《
透过 Rust 探索系统的本原:编程语言
》中,用一幅图概述了 Rust 的所有权和借用规则:
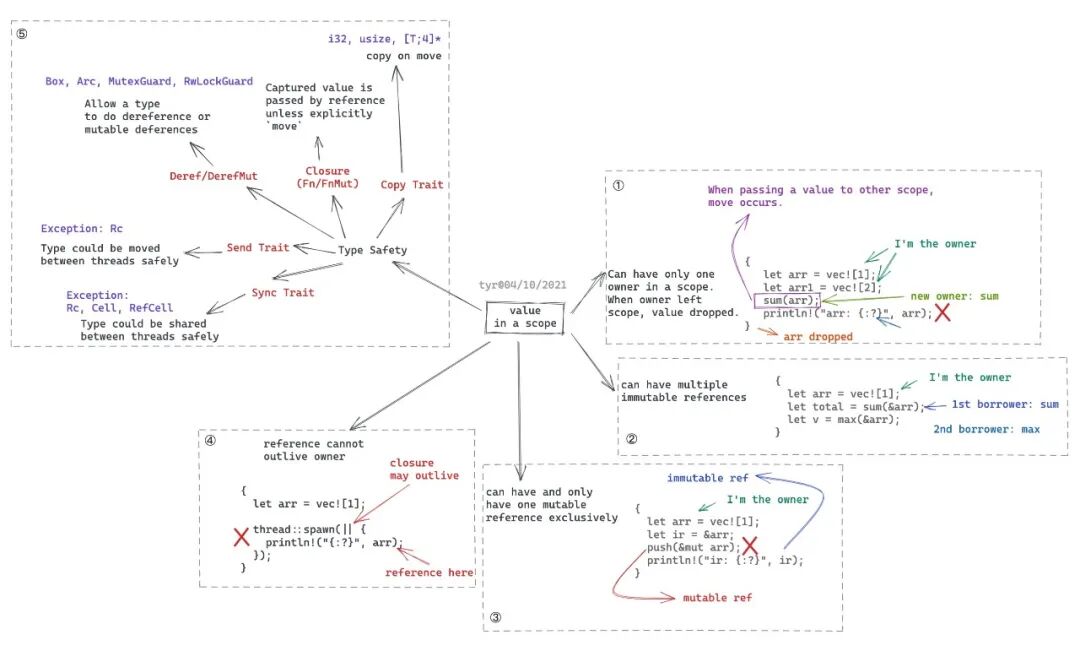
如果对所有权和借用规则不熟悉的读者,可以看我的那篇文章。我们来深入看看,Rust 的所有权和借用规则是如何结合编译期生命周期的推定,来解决堆上内存的生命周期管理的问题的。
我们先用一幅图看 move 是如何处理的:
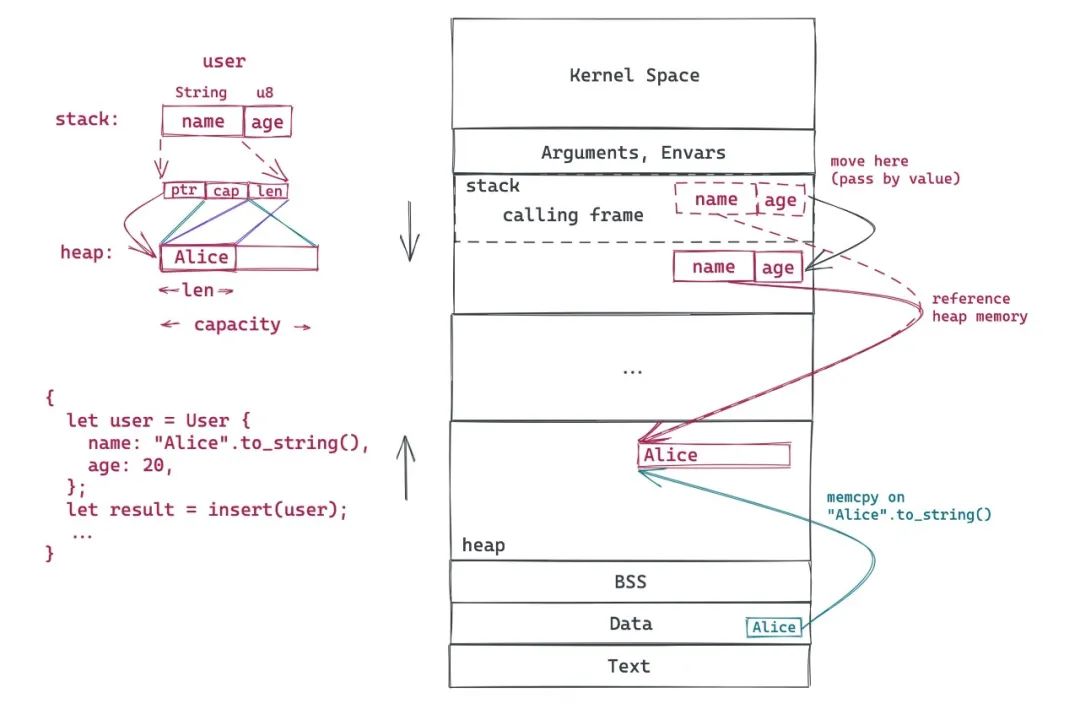
这段简单的代码里,我们生成了一个
User
对象,然后将其传递给
insert()
函数。在 Rust 里,除非特别声明(使用智能指针),对象(结构)是存储在栈上的。而 Rust 的
String
对象,会在栈上放一个指针,指向堆里的实际字符串数据。由于 Rust 的单一所有权模型,当
user
移动到
insert
函数后,
insert
就是其新的 owner,编译器会确保之前的 owner 失去对
user
的访问权:如果继续访问,会得到编译错误。由此,堆上的字符串依旧只有一个 owner(图中红色实线),而旧的 owner 因为被禁止使用,也就间接失去了对堆上数据的引用。当
insert
函数结束时,
user
被丢弃(Drop),也即意味着堆上分配的内存被释放(还记得上篇文章讲的 RAII 么)。所以,对于对象的 move,Rust 轻松搞定堆上的数据的生命周期的管理。





