正文
基于 Kafka 和 Flink 的在消息中间件以及流式计算方面的耀眼表现,于是产生了围绕 Kafka 及 Flink 为基础的流计算平台体系,如下图所示:基于 APP、web 等方式将实时产生的日志采集到 Kafka,然后交由 Flink 来进行常见的 ETL,全局聚合以及Window 聚合等实时计算。
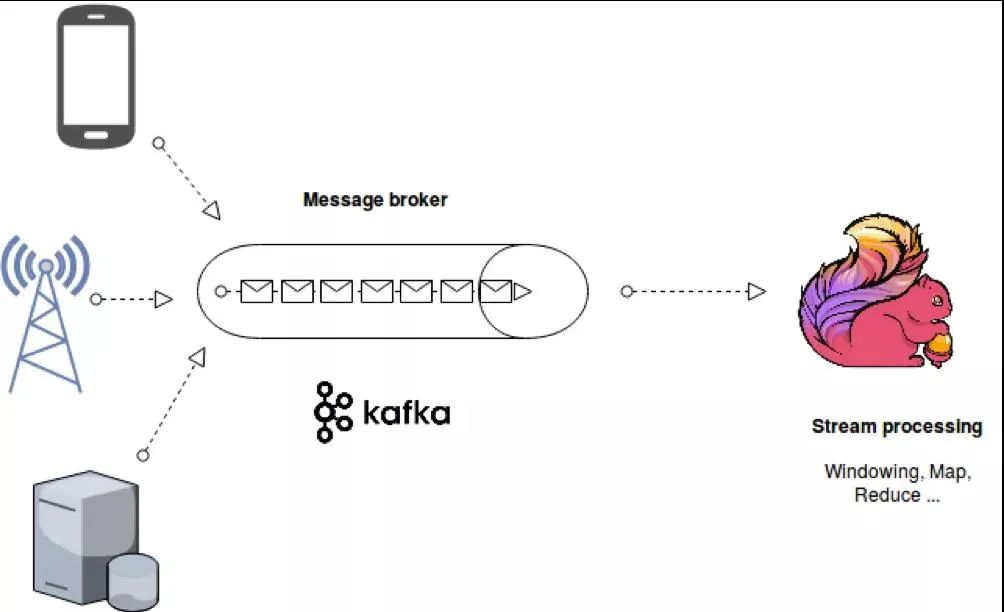
目前我们有 10+个 Kafka 集群,各个集群的主要任务不同,有些作为业务集群,有些作为镜像集群,有些作为计算集群等。当前 Kafka 集群的总节点数达到 200+,单 Kafka 峰值 QPS 400W+。目前,网易云音乐基于 Kafka+Flink 的实时任务达到了 500+。
基于以上情况,我们想要对 Kafka+Flink 做一个平台化的开发,减少用户的开发成本和运维成本。实际上在 2018 年的时候我们就开始基于 Flink 做一个实时计算平台,Kafka 在其中发挥着重要作用,今年,为了让用户更加方便、更加容易的去使用 Flink 和 Kafka,我们进行了重构。
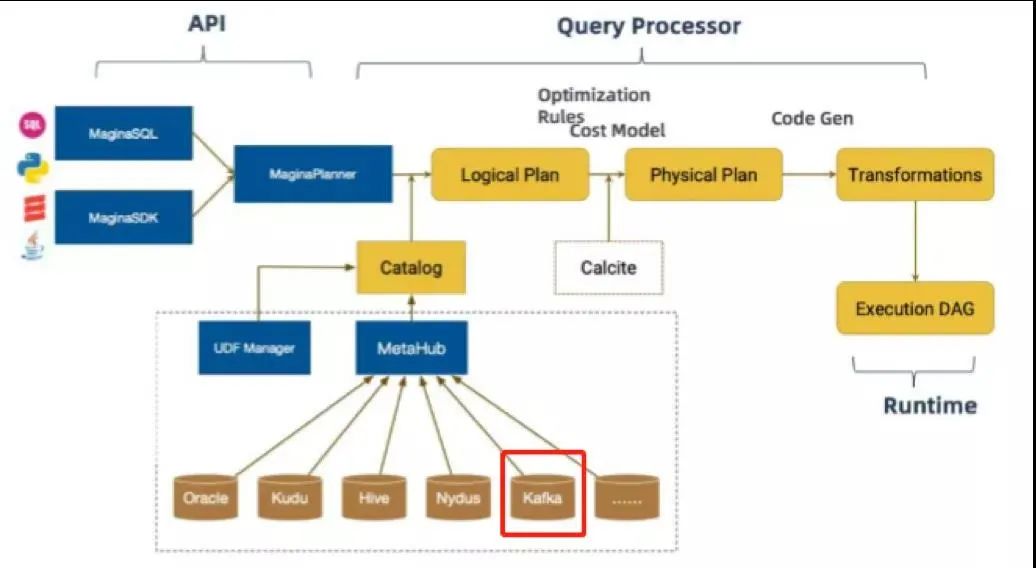
基于 Flink 1.0 版本我们做了一个 Magina 版本的重构,在 API 层次我们提供了 Magina SQL 和 Magina SDK 贯穿 DataStream 和 SQL 操作;然后通过自定义 Magina SQL Parser 会把这些 SQL 转换成 Logical Plan,在将 LogicalPlan 转化为物理执行代码,在这过程中会去通过 catalog 连接元数据管理中心去获取一些元数据的信息。我们在 Kafka 的使用过程中,会将 Kafka 元数据信息登记到元数据中心,对实时数据的访问都是以流表的形式。在 Magina 中我们对 Kafka 的使用主要做了三部分的工作:
-
集群 catalog 化;
-
Topic 流表化;
-
Message Schema 化。
用户可以在元数据管理中心登记不同的表信息或者 catalog 信息等,也可以在 DB 中创建和维护 Kafka 的表,用户在使用的过程只需要根据个人需求使用相应的表即可。下图是对 Kafka 流表的主要引用逻辑。
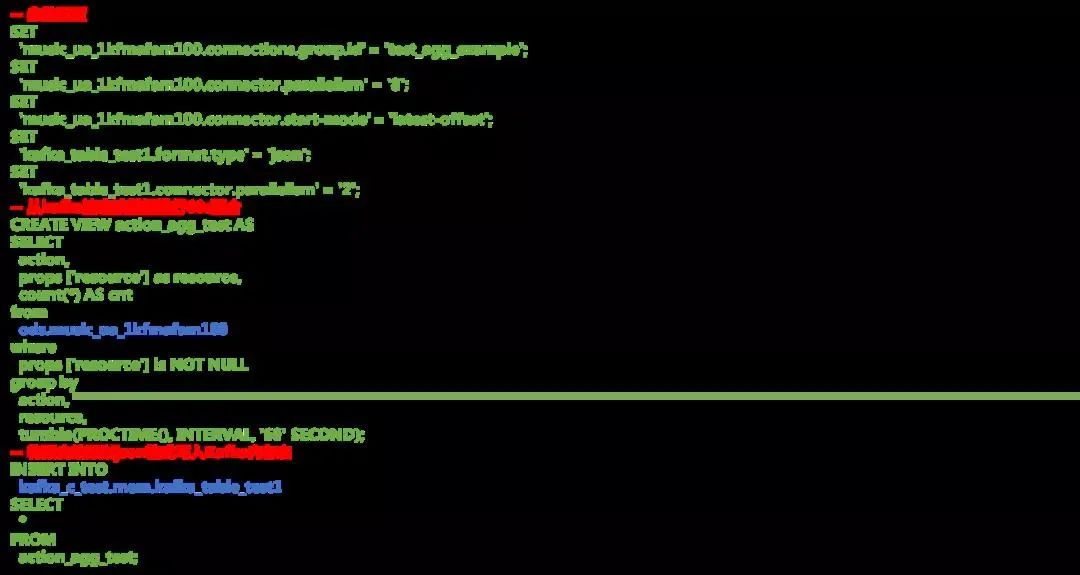
Kafka 在实时数仓使用的过程中,我们遇到了不同的问题,中间也尝试了不同的解决办法。
在平台初期, 最开始用于实时计算的只有两个集群,且有一个采集集群,单 Topic 数据量非常大;不同的实时任务都会消费同一个大数据量的 Topic,Kafka 集群 IO 压力异常大;
因此,在使用的过程发现 Kafka 的压力异常大,经常出现延迟、I/O 飙升。
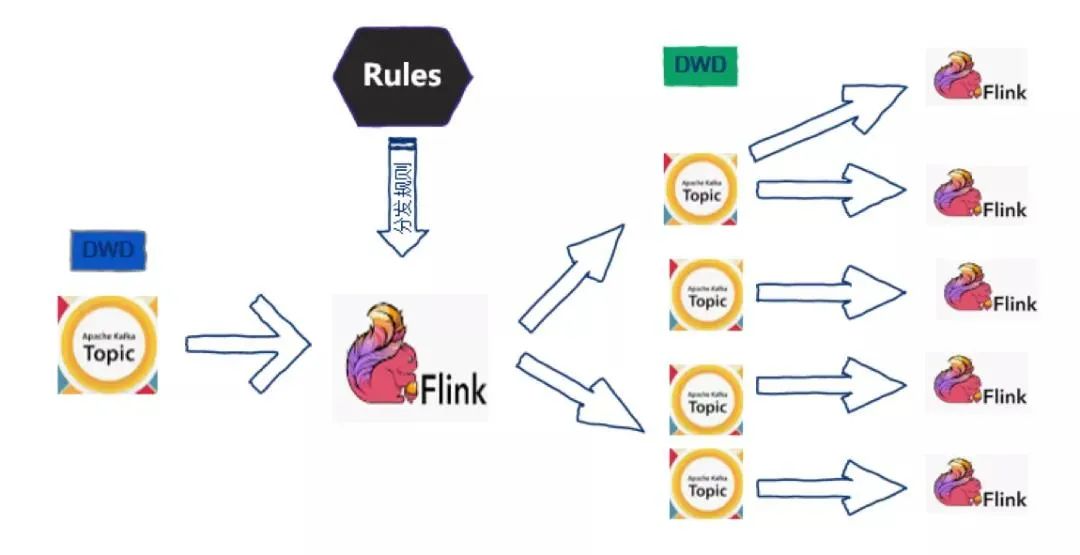
我们想到把大的 Topic 进行实时分发来解决上面的问题,基于 Flink 1.5 设计了如下图所示的数据分发的程序,也就是实时数仓的雏形。基于这种将大的 Topic 分发成小的 Topic 的方法,大大减轻了集群的压力,提升了性能,另外,最初使用的是静态的分发规则,后期需要添加规则的时候要进行任务的重启,对业务影响比较大,之后我们考虑了使用动态规则来完成数据分发的任务。