正文
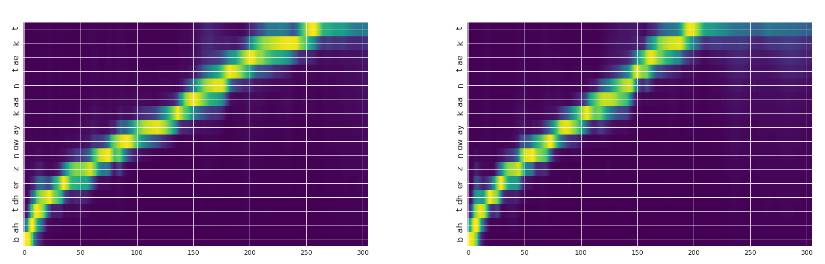
说明:X 轴是输出时间(声学样本),Y 轴是输入(文本/音素)。左图是说话者 10,右图是说话者 14
最后,该系统还支持自由文本:
python generate.py --text "hello world" --spkr 1 --checkpoint models/vctk/bestmodel.pth
安装
需求:Linux/OSX、Python2.7 和 PyTorch 0.1.12。代码当前版本需要 CUDA 支持训练。生成将在 CPU 上完成。
git clone https://github.com/facebookresearch/loop.git
cd loop
pip install -r scripts/requirements.txt
数据
论文中用于训练模型的数据可以通过以下方式下载:
bash scripts/download_data.sh
脚本下载 VCTK 的子集,并进行预处理。该子集包括美国口音的说话者。使用 Merlin 对该数据集进行预处理——使用 WORLD 声码器从每个音频剪辑文件中抽取声码器特征。下载完成后,该数据集将位于子文件夹 data 下,如下所示:
loop
├── data
└── vctk
├── norm_info
│ ├── norm.dat
├── numpy_feautres
│ ├── p294_001.npz
│ ├── p294_002.npz





